Chapter 4. Datenverwaltung
4.1. Räumliches Datenmodell
4.1.1. OGC-Geometrie
Das Open Geospatial Consortium (OGC) hat den Standard Simple Features Access (SFA) entwickelt, um ein Modell für Geodaten bereitzustellen. Er definiert den grundlegenden Raumtyp Geometrie sowie Operationen, die Geometriewerte manipulieren und transformieren, um räumliche Analyseaufgaben durchzuführen. PostGIS implementiert das OGC Geometry Modell als die PostgreSQL Datentypen Geometry und Geography.
Geometrie ist ein abstrakter Typ. Geometriewerte gehören zu einem seiner konkreten Untertypen, die verschiedene Arten und Dimensionen geometrischer Formen darstellen. Dazu gehören die atomaren Typen Point, LineString, LinearRing und Polygon, und die Sammlung Typen MultiPoint, MultiLineString, MultiPolygon und GeometryCollection. Der Simple Features Access - Part 1: Gemeinsame Architektur v1.2.1 fügt Subtypen für die Strukturen PolyhedralSurface, Triangle und TIN hinzu.
Geometry modelliert Formen in der 2-dimensionalen kartesischen Ebene. Die Typen PolyhedralSurface, Triangle und TIN können auch Formen im 3-dimensionalen Raum darstellen. Die Größe und Lage von Formen wird durch ihre Koordinaten angegeben. Jede Koordinate hat einen X- und Y Ordinatenwert, der ihre Lage in der Ebene bestimmt. Formen werden aus Punkten oder Liniensegmenten konstruiert, wobei Punkte durch eine einzelne Koordinate und Liniensegmente durch zwei Koordinaten angegeben werden.
Koordinaten können optionale Z- und M-Ordinatenwerte enthalten. Die Z-Ordinate wird häufig zur Darstellung der Höhe verwendet. Die M-Ordinate enthält einen Messwert, der Zeit oder Entfernung darstellen kann. Wenn Z- oder M-Werte in einem Geometriewert vorhanden sind, müssen sie für jeden Punkt in der Geometrie definiert werden. Wenn eine Geometrie Z- oder M-Ordinaten hat, ist die Koordinaten-Dimension 3D; wenn sie sowohl Z- als auch M-Werte hat, ist die Koordinaten-Dimension 4D.
Geometriewerte sind mit einem räumlichen Bezugssystem verbunden, das das Koordinatensystem angibt, in das sie eingebettet sind. Das räumliche Bezugssystem wird durch die SRID-Nummer der Geometrie identifiziert. Die Einheiten der X- und Y-Achsen werden durch das räumliche Bezugssystem bestimmt. In planaren Bezugssystemen stellen die X- und Y-Koordinaten typischerweise Ost- und Nordrichtung dar, während sie in geodätischen Systemen Längen- und Breitengrad darstellen. SRID 0 steht für eine unendliche kartesische Ebene, deren Achsen keine Einheiten zugewiesen sind. Siehe Section 4.5, “Räumliche Bezugssysteme”.
Die Geometrie Dimension ist eine Eigenschaft von Geometrietypen. Punkttypen haben die Dimension 0, lineare Typen haben die Dimension 1, und polygonale Typen haben die Dimension 2. Sammlungen haben die Dimension der maximalen Elementdimension.
Ein Geometriewert kann leer sein. Leere Werte enthalten keine Scheitelpunkte (bei atomaren Geometrietypen) oder keine Elemente (bei Sammlungen).
Eine wichtige Eigenschaft von Geometriewerten ist ihre räumliche Ausdehnung oder bounding box, die im OGC-Modell envelope genannt wird. Dies ist der 2- oder 3-dimensionale Rahmen, der die Koordinaten einer Geometrie umschließt. Es ist ein effizientes Mittel, um die Ausdehnung einer Geometrie im Koordinatenraum darzustellen und zu prüfen, ob zwei Geometrien interagieren.
Das Geometriemodell ermöglicht die Auswertung topologischer räumlicher Beziehungen, wie in Section 5.1.1, “Dimensionell erweitertes 9-Schnitte-Modell” beschrieben. Um dies zu unterstützen, werden für jeden Geometrietyp die Konzepte interior, boundary und exterior definiert. Geometrien sind topologisch geschlossen, sie enthalten also immer ihren Rand. Der Rand ist eine Geometrie der Dimension eins weniger als die der Geometrie selbst.
Das OGC-Geometriemodell definiert Gültigkeitsregeln für jeden Geometrietyp. Diese Regeln stellen sicher, dass die Geometriewerte realistische Situationen darstellen (z.B. ist es möglich, ein Polygon mit einem Loch außerhalb der Schale zu spezifizieren, was aber geometrisch keinen Sinn ergibt und daher ungültig ist). PostGIS erlaubt auch die Speicherung und Bearbeitung von ungültigen Geometriewerten. Dies ermöglicht es, sie zu erkennen und bei Bedarf zu korrigieren. Siehe Section 4.4, “Geometrievalidierung”
4.1.1.1. Punkt
Ein Punkt ist eine 0-dimensionale Geometrie, die einen einzelnen Ort im Koordinatenraum darstellt.
POINT (1 2) POINT Z (1 2 3) POINT ZM (1 2 3 4)
4.1.1.2. Linie
Ein LineString ist eine eindimensionale Linie, die aus einer zusammenhängenden Folge von Liniensegmenten besteht. Jedes Liniensegment wird durch zwei Punkte definiert, wobei der Endpunkt eines Segments den Startpunkt des nächsten Segments bildet. Ein OGC-konformer LineString hat entweder null oder zwei oder mehr Punkte, aber PostGIS erlaubt auch Ein-Punkt-LineStrings. LineStrings können sich selbst kreuzen (self-intersect). Ein LineString ist geschlossen wenn der Start- und Endpunkt gleich sind. Ein LineString ist einfach, wenn er sich nicht selbst schneidet.
LINESTRING (1 2, 3 4, 5 6)
4.1.1.3. LinearRing
Ein LinearRing ist ein LineString, der sowohl geschlossen als auch einfach ist. Der erste und der letzte Punkt müssen gleich sein, und die Linie darf sich nicht selbst schneiden.
LINEARRING (0 0 0, 4 0 0, 4 4 0, 0 4 0, 0 0 0)
4.1.1.4. Polygon
Ein Polygon ist ein 2-dimensionaler ebener Bereich, der durch eine äußere Begrenzung (die Schale) und null oder mehr innere Begrenzungen (Löcher) begrenzt wird. Jede Begrenzung ist ein LinearRing.
POLYGON ((0 0 0,4 0 0,4 4 0,0 4 0,0 0 0),(1 1 0,2 1 0,2 2 0,1 2 0,1 1 0))
4.1.1.5. MultiPoint
Ein MultiPoint ist eine Sammlung von Punkten.
MULTIPOINT ( (0 0), (1 2) )
4.1.1.6. MultiLineString
Ein MultiLineString ist eine Sammlung von LineStrings. Ein MultiLineString ist geschlossen, wenn jedes seiner Elemente geschlossen ist.
MULTILINESTRING ( (0 0,1 1,1 2), (2 3,3 2,5 4) )
4.1.1.7. MultiPolygon
Ein MultiPolygon ist eine Sammlung von nicht überlappenden, nicht benachbarten Polygonen. Die Polygone der Sammlung dürfen sich nur an einer endlichen Anzahl von Punkten berühren.
MULTIPOLYGON (((1 5, 5 5, 5 1, 1 1, 1 5)), ((6 5, 9 1, 6 1, 6 5)))
4.1.1.8. GeometryCollection
Eine GeometryCollection ist eine heterogene (gemischte) Sammlung von Geometrien.
GEOMETRYCOLLECTION ( POINT(2 3), LINESTRING(2 3, 3 4))
4.1.1.9. PolyhedralSurface
Eine PolyhedralSurface ist eine zusammenhängende Sammlung von Flächen oder Facetten, die einige Kanten gemeinsam haben. Jedes Feld ist ein planares Polygon. Wenn die Polygonkoordinaten Z-Ordinaten haben, ist die Fläche 3-dimensional.
POLYHEDRALSURFACE Z ( ((0 0 0, 0 0 1, 0 1 1, 0 1 0, 0 0 0)), ((0 0 0, 0 1 0, 1 1 0, 1 0 0, 0 0 0)), ((0 0 0, 1 0 0, 1 0 1, 0 0 1, 0 0 0)), ((1 1 0, 1 1 1, 1 0 1, 1 0 0, 1 1 0)), ((0 1 0, 0 1 1, 1 1 1, 1 1 0, 0 1 0)), ((0 0 1, 1 0 1, 1 1 1, 0 1 1, 0 0 1)) )
4.1.1.10. Dreieck
Ein Dreieck ist ein Polygon, das durch drei verschiedene, nicht kollineare Scheitelpunkte definiert ist. Da ein Dreieck ein Polygon ist, wird es durch vier Koordinaten definiert, wobei die erste und die vierte gleich sind.
TRIANGLE ((0 0, 0 9, 9 0, 0 0))
4.1.1.11. TIN
Ein TIN ist eine Sammlung von nicht überlappenden Dreiecken, die ein Trianguliertes unregelmäßiges Netz darstellen.
TIN Z ( ((0 0 0, 0 0 1, 0 1 0, 0 0 0)), ((0 0 0, 0 1 0, 1 1 0, 0 0 0)) )
4.1.2. SQL/MM Teil 3 - Kurven
Der ISO/IEC 13249-3 SQL Multimedia - Spatial Standard (SQL/MM) erweitert den OGC SFA um die Definition von Geometrie-Subtypen, die Kurven mit Kreisbögen enthalten. Die SQL/MM-Typen unterstützen 3DM-, 3DZ- und 4D-Koordinaten.
![[Note]](../images/note.png)
|
|
|
Alle Gleitpunkt Vergleiche der SQL-MM Implementierung werden mit einer bestimmten Toleranz ausgeführt, zurzeit 1E-8. |
4.1.2.1. CircularString
CircularString ist der grundlegende Kurventyp, ähnlich einem LineString in der linearen Welt. Ein einzelnes Bogensegment wird durch drei Punkte spezifiziert: den Anfangs- und Endpunkt (erster und dritter Punkt) und einen weiteren Punkt auf dem Bogen. Zur Angabe eines geschlossenen Kreises sind der Anfangs- und der Endpunkt identisch, und der mittlere Punkt ist der gegenüberliegende Punkt auf dem Kreisdurchmesser (der den Mittelpunkt des Bogens bildet). In einer Folge von Bögen ist der Endpunkt des vorherigen Bogens der Startpunkt des nächsten Bogens, genau wie die Segmente eines LineString. Dies bedeutet, dass ein CircularString eine ungerade Anzahl von Punkten größer als 1 haben muss.
CIRCULARSTRING(0 0, 1 1, 1 0) CIRCULARSTRING(0 0, 4 0, 4 4, 0 4, 0 0)
4.1.2.2. CompoundCurve
Eine CompoundCurve ist eine einzelne kontinuierliche Kurve, die sowohl Kreisbogensegmente als auch lineare Segmente enthalten kann. Das bedeutet, dass nicht nur wohlgeformte Komponenten vorhanden sein müssen, sondern auch der Endpunkt jeder Komponente (außer der letzten) mit dem Anfangspunkt der folgenden Komponente übereinstimmen muss.
COMPOUNDCURVE( CIRCULARSTRING(0 0, 1 1, 1 0),(1 0, 0 1))
4.1.2.3. KurvenPolygon
Ein CurvePolygon ist wie ein Polygon, mit einem äußeren Ring und null oder mehr inneren Ringen. Der Unterschied besteht darin, dass ein Ring sowohl ein CircularString oder CompoundCurve als auch ein LineString sein kann.
Ab PostGIS 1.4 werden zusammengesetzte Kurven/CompoundCurve in einem Kurvenpolygon/CurvePolygon unterstützt.
CURVEPOLYGON( CIRCULARSTRING(0 0, 4 0, 4 4, 0 4, 0 0), (1 1, 3 3, 3 1, 1 1) )
Beispiel: Ein CurvePolygon mit einer Hülle, die durch eine CompoundCurve definiert ist, die einen CircularString und einen LineString enthält, und einem Loch, das durch einen CircularString definiert ist
CURVEPOLYGON(
COMPOUNDCURVE( CIRCULARSTRING(0 0,2 0, 2 1, 2 3, 4 3),
(4 3, 4 5, 1 4, 0 0)),
CIRCULARSTRING(1.7 1, 1.4 0.4, 1.6 0.4, 1.6 0.5, 1.7 1) )
4.1.2.4. MultiCurve
Eine MultiCurve ist eine Sammlung von Kurven, die LineStrings, CircularStrings oder CompoundCurves enthalten kann.
MULTICURVE( (0 0, 5 5), CIRCULARSTRING(4 0, 4 4, 8 4))
4.1.2.5. MultiSurface
Eine MultiSurface ist eine Sammlung von Flächen, die (lineare) Polygone oder CurvePolygone sein können.
MULTISURFACE(
CURVEPOLYGON(
CIRCULARSTRING( 0 0, 4 0, 4 4, 0 4, 0 0),
(1 1, 3 3, 3 1, 1 1)),
((10 10, 14 12, 11 10, 10 10), (11 11, 11.5 11, 11 11.5, 11 11)))
4.1.3. WKT und WKB
Die OGC SFA-Spezifikation definiert zwei Formate für die Darstellung von Geometriewerten zur externen Verwendung: Well-Known Text (WKT) und Well-Known Binary (WKB). Sowohl WKT als auch WKB enthalten Informationen über den Typ des Objekts und die Koordinaten, die es definieren.
Well-Known Text (WKT) bietet eine standardisierte textuelle Darstellung von räumlichen Daten. Beispiele für WKT-Darstellungen von räumlichen Objekten sind:
-
POINT(0 0)
-
PUNKT Z (0 0 0)
-
PUNKT ZM (0 0 0 0)
-
PUNKT LEER
-
LINESTRING(0 0,1 1,1 2)
-
ZEILENSTRING LEER
-
POLYGON((0 0,4 0,4 4,0 4,0 0),(1 1, 2 1, 2 2, 1 2,1 1))
-
MULTIPOINT((0 0),(1 2))
-
MEHRPUNKT Z ((0 0 0),(1 2 3))
-
MULTIPOINT LEER
-
MULTILINESTRING((0 0,1 1,1 2),(2 3,3 2,5 4))
-
MULTIPOLYGON(((0 0,4 0,4 4,0 4,0 0),(1 1,2 1,2 2,1 2,1 1)), ((-1 -1,-1 -2,-2 -2,-2 -1,-1 -1)))
-
GEOMETRYCOLLECTION(POINT(2 3),LINESTRING(2 3,3 4))
-
GEOMETRYCOLLECTION LEER
Die Ein- und Ausgabe des WKT erfolgt über die Funktionen ST_AsText und ST_GeomFromText:
text WKT = ST_AsText(geometry); geometry = ST_GeomFromText(text WKT, SRID);
Eine Anweisung zum Erstellen und Einfügen eines Geo-Objekts aus WKT und einer SRID lautet zum Beispiel so:
INSERT INTO geotable ( geom, name )
VALUES ( ST_GeomFromText('POINT(-126.4 45.32)', 312), 'A Place');
Well-Known Binary (WKB) bietet eine tragbare, hochpräzise Darstellung von Geodaten als Binärdaten (Arrays von Bytes). Beispiele für die WKB-Darstellung von Geo-Objekten sind:
-
WKT: PUNKT(1 1)
WKB: 0101000000000000000000F03F000000000000F03
-
WKT: LINIENSTRING (2 2, 9 9)
WKB: 0102000000020000000000000000000040000000000000004000000000000022400000000000002240
Die Ein- und Ausgabe von WKB erfolgt über die Funktionen ST_AsBinary und ST_GeomFromWKB:
bytea WKB = ST_AsBinary(geometry); geometry = ST_GeomFromWKB(bytea WKB, SRID);
Eine Anweisung zum Erstellen und Einfügen eines Geo-Objekts aus WKB lautet zum Beispiel so:
INSERT INTO geotable ( geom, name )
VALUES ( ST_GeomFromWKB('\x0101000000000000000000f03f000000000000f03f', 312), 'A Place');
4.2. Geometrie Datentyp
PostGIS implementiert das OGC Simple Features Modell durch die Definition eines PostgreSQL Datentyps namens geometry. Er repräsentiert alle Geometrie-Subtypen durch Verwendung eines internen Typcodes (siehe GeometryType und ST_GeometryType). Dies ermöglicht die Modellierung von räumlichen Merkmalen als Zeilen von Tabellen, die mit einer Spalte vom Typ geometry definiert sind.
Der Geometrie Datentyp ist opaque, was bedeutet, dass der gesamte Zugriff über den Aufruf von Funktionen auf Geometriewerte erfolgt. Funktionen ermöglichen die Erstellung von Geometrieobjekten, den Zugriff auf alle internen Felder oder deren Aktualisierung sowie die Berechnung neuer Geometriewerte. PostGIS unterstützt alle Funktionen, die in der OGC Simple feature access - Part 2: SQL option (SFS) Spezifikation spezifiziert sind, sowie viele andere. Siehe Chapter 7, Referenz PostGIS für die vollständige Liste der Funktionen.
|
|
|
|
PostGIS folgt dem SFA-Standard, indem es den räumlichen Funktionen das Kürzel "ST_" voranstellt. Dies sollte für "Spatial and Temporal" (räumlich und zeitlich) stehen, aber der zeitliche Teil des Standards wurde nie entwickelt. Stattdessen kann es als "Spatial Type" interpretiert werden. |
Der SFA-Standard sieht vor, dass Geo-Objekte einen Spatial Reference System Identifier (SRID) enthalten. Der SRID ist erforderlich, wenn Geo-Objekte zum Einfügen in die Datenbank erstellt werden (er kann auf 0 voreingestellt sein). Siehe ST_SRID und Section 4.5, “Räumliche Bezugssysteme”
Um die Abfrage von Geometrien effizient zu gestalten, definiert PostGIS verschiedene Arten von räumlichen Indizes und räumliche Operatoren, um diese zu verwenden. Siehe Section 4.9, “Räumliche Indizes” und Section 5.2, “Räumliche Indizes verwenden” für Details.
4.2.1. PostGIS EWKB und EWKT
Die OGC SFA-Spezifikationen unterstützten ursprünglich nur 2D-Geometrien, und die Geometrie-SRID ist nicht in den Eingabe-/Ausgabedarstellungen enthalten. Die OGC-SFA-Spezifikation 1.2.1 (die mit der ISO-Norm 19125 übereinstimmt) unterstützt nun auch 3D- (ZYZ) und gemessene (XYM und XYZM) Koordinaten, enthält aber immer noch keinen SRID-Wert.
Aufgrund dieser Einschränkungen hat PostGIS erweiterte EWKB- und EWKT-Formate definiert. Sie bieten Unterstützung für 3D- (XYZ und XYM) und 4D-Koordinaten (XYZM) und enthalten SRID-Informationen. Durch die Einbeziehung aller Geometrieinformationen kann PostGIS EWKB als Datensatzformat verwenden (z. B. in DUMP-Dateien).
EWKB und EWKT werden für die "kanonischen Formen" von PostGIS-Datenobjekten verwendet. Für die Eingabe ist die kanonische Form für binäre Daten EWKB, und für Textdaten wird entweder EWKB oder EWKT akzeptiert. Dies ermöglicht die Erstellung von Geometriewerten durch Umwandlung eines Textwerts in HEXEWKB oder EWKT in einen Geometriewert unter Verwendung von ::geometry. Für die Ausgabe ist die kanonische Form für Binärdaten EWKB und für Textdaten HEXEWKB (hexkodiertes EWKB).
Diese Anweisung erzeugt zum Beispiel eine Geometrie durch Casting aus einem EWKT-Textwert und gibt sie in der kanonischen Form HEXEWKB aus:
SELECT 'SRID=4;POINT(0 0)'::geometry; geometry ---------------------------------------------------- 01010000200400000000000000000000000000000000000000
Die PostGIS EWKT-Ausgabe weist einige Unterschiede zur OGC WKT auf:
-
Bei 3DZ-Geometrien entfällt der Qualifier Z:
OGC: PUNKT Z (1 2 3)
EWKT: PUNKT (1 2 3)
-
Für 3DM-Geometrien ist der Qualifier M enthalten:
OGC: PUNKT M (1 2 3)
EWKT: POINTM (1 2 3)
-
Bei 4D-Geometrien entfällt der ZM-Bezeichner:
OGC: PUNKT ZM (1 2 3 4)
EWKT: PUNKT (1 2 3 4)
EWKT vermeidet eine übermäßige Spezifizierung der Dimensionalität und die Inkonsistenzen, die beim OGC/ISO-Format auftreten können, wie z. B.:
-
PUNKT ZM (1 1)
-
PUNKT ZM (1 1 1)
-
PUNKT (1 1 1 1)
![[Caution]](../images/caution.png)
|
|
|
Die erweiterten PostGIS-Formate sind derzeit eine Obermenge der OGC-Formate, so dass jedes gültige OGC-WKB/WKT auch ein gültiges EWKB/EWKT ist. Dies könnte sich jedoch in Zukunft ändern, wenn das OGC ein Format in einer Weise erweitert, die mit der PosGIS-Definition in Konflikt steht. Sie sollten sich also NICHT auf diese Kompatibilität verlassen! |
Beispiele für die EWKT-Textdarstellung von räumlichen Objekten sind:
-
POINT(0 0 0) -- XYZ
-
SRID=32632;POINT(0 0) -- XY mit SRID
-
POINTM(0 0 0) -- XYM
-
POINT(0 0 0 0) -- XYZM
-
SRID=4326;MULTIPOINTM(0 0 0,1 2 1) -- XYM mit SRID
-
MULTILINESTRING((0 0 0,1 1 0,1 2 1),(2 3 1,3 2 1,5 4 1))
-
POLYGON((0 0 0,4 0 0,4 4 0,0 4 0,0 0 0),(1 1 0,2 1 0,2 2 0,1 2 0,1 1 0))
-
MULTIPOLYGON(((0 0 0,4 0 0,4 4 0,0 4 0,0 0 0),(1 1 0,2 1 0,2 2 0,1 2 0,1 1 0)),((-1 -1 0,-1 -2 0,-2 -2 0,-2 -1 0,-1 -1 0)))
-
GEOMETRYCOLLECTIONM( POINTM(2 3 9), LINESTRINGM(2 3 4, 3 4 5) )
-
MULTICURVE( (0 0, 5 5), CIRCULARSTRING(4 0, 4 4, 8 4) )
-
POLYHEDRALSURFACE( ((0 0 0, 0 0 1, 0 1 1, 0 1 0, 0 0 0)), ((0 0 0, 0 1 0, 1 1 0, 1 0 0, 0 0 0)), ((0 0 0, 1 0 0, 1 0 1, 0 0 1, 0 0 0)), ((1 1 0, 1 1 1, 1 0 1, 1 0 0, 1 1 0)), ((0 1 0, 0 1 1, 1 1 1, 1 1 0, 0 1 0)), ((0 0 1, 1 0 1, 1 1 1, 0 1 1, 0 0 1)) )
-
TRIANGLE ((0 0, 0 10, 10 0, 0 0))
-
TIN( ((0 0 0, 0 0 1, 0 1 0, 0 0 0)), ((0 0 0, 0 1 0, 1 1 0, 0 0 0)) )
Die Ein- und Ausgabe in diesen Formaten ist über die folgenden Funktionen möglich:
bytea EWKB = ST_AsEWKB(geometry); text EWKT = ST_AsEWKT(geometry); geometry = ST_GeomFromEWKB(bytea EWKB); geometry = ST_GeomFromEWKT(text EWKT);
Eine Anweisung zum Erstellen und Einfügen eines PostGIS-Gebietsobjekts unter Verwendung von EWKT lautet zum Beispiel so:
INSERT INTO geotable ( geom, name )
VALUES ( ST_GeomFromEWKT('SRID=312;POINTM(-126.4 45.32 15)'), 'A Place' )
4.3. Geographie Datentyp
Der Datentyp PostGIS geography bietet native Unterstützung für räumliche Merkmale, die in "geografischen" Koordinaten (manchmal auch "geodätische" Koordinaten oder "lat/lon" oder "lon/lat" genannt) dargestellt werden. Geografische Koordinaten sind sphärische Koordinaten, die in Winkeleinheiten (Grad) ausgedrückt werden.
Die Grundlage für den PostGIS-Geometriedatentyp ist eine Ebene. Der kürzeste Weg zwischen zwei Punkten in der Ebene ist eine gerade Linie. Das bedeutet, dass Funktionen für Geometrien (Flächen, Abstände, Längen, Schnittpunkte usw.) mit Geradenvektoren und kartesischer Mathematik berechnet werden. Dadurch sind sie einfacher zu implementieren und schneller auszuführen, aber auch ungenau für Daten auf der sphäroidischen Oberfläche der Erde.
Der PostGIS-Geodatentyp basiert auf einem Kugelmodell. Der kürzeste Weg zwischen zwei Punkten auf der Kugel ist ein Großkreisbogen. Funktionen auf Geografien (Flächen, Entfernungen, Längen, Schnittpunkte usw.) werden mit Hilfe von Bögen auf der Kugel berechnet. Da die Funktionen die Kugelform der Welt berücksichtigen, liefern sie genauere Ergebnisse.
Da die zugrunde liegende Mathematik komplizierter ist, sind für den Typ Geografie weniger Funktionen definiert als für den Typ Geometrie. Im Laufe der Zeit, wenn neue Algorithmen hinzukommen, werden sich die Möglichkeiten des Typs Geografie erweitern. Als Abhilfe kann man zwischen den Typen Geometrie und Geografie hin- und herwechseln.
Wie der Datentyp Geometrie sind auch die Geodaten über einen Spatial Reference System Identifier (SRID) mit einem räumlichen Bezugssystem verbunden. Jedes in der Tabelle spatial_ref_sys definierte geodätische (long/lat-basierte) Raumbezugssystem kann verwendet werden. (Vor PostGIS 2.2 unterstützte der Geografietyp nur das geodätische WGS 84 (SRID:4326)). Sie können Ihr eigenes geodätisches Raumbezugssystem hinzufügen, wie in Section 4.5.2, “Benutzerdefinierte räumliche Bezugssysteme” beschrieben.
Für alle räumlichen Bezugssysteme sind die Einheiten, die von Messfunktionen (z. B. ST_Distance, ST_Length, ST_Perimeter, ST_Area) und für das Entfernungsargument von ST_DWithin zurückgegeben werden, in Metern.
4.3.1. Erstellen von Geografietabellen
Sie können eine Tabelle zum Speichern von geografischen Daten mit der SQL-Anweisung CREATE TABLE mit einer Spalte vom Typ Geografie erstellen. Das folgende Beispiel erstellt eine Tabelle mit einer Geografiespalte, die 2D LineStrings im geodätischen Koordinatensystem WGS84 (SRID 4326) speichert:
CREATE TABLE global_points (
id SERIAL PRIMARY KEY,
name VARCHAR(64),
location geography(POINT,4326)
);
Der Geografietyp unterstützt zwei optionale Typmodifikatoren:
-
Der Modifikator für die Raumart schränkt die Art der in der Spalte zulässigen Formen und Abmessungen ein. Für die Raumart sind folgende Werte zulässig: POINT, LINESTRING, POLYGON, MULTIPOINT, MULTILINESTRING, MULTIPOLYGON, GEOMETRYCOLLECTION. Der Geografietyp unterstützt keine Kurven, TINS oder POLYHEDRALSURFACEs. Der Modifikator unterstützt Einschränkungen der Koordinatendimensionalität durch Hinzufügen von Suffixen: Z, M und ZM. Ein Modifikator "LINESTRINGM" lässt beispielsweise nur Linienzüge mit drei Dimensionen zu und behandelt die dritte Dimension als Maß. In ähnlicher Weise erfordert 'POINTZM' vierdimensionale (XYZM) Daten.
-
Der Modifikator SRID schränkt das räumliche Bezugssystem SRID auf eine bestimmte Nummer ein. Wird dieser Modifikator weggelassen, so ist das SRID standardmäßig 4326 (WGS84 geodätisch), und alle Berechnungen werden mit WGS84 durchgeführt.
Beispiele für die Erstellung von Tabellen mit geografischen Spalten:
-
Erstellen Sie eine Tabelle mit 2D-Punktgeografie mit dem Standard-SRID 4326 (WGS84 long/lat):
CREATE TABLE ptgeogwgs(gid serial PRIMARY KEY, geog geography(POINT) );
-
Erstellen Sie eine Tabelle mit 2D-Punktgeografie in NAD83 longlat:
CREATE TABLE ptgeognad83(gid serial PRIMARY KEY, geog geography(POINT,4269) );
-
Erstellen Sie eine Tabelle mit 3D (XYZ) POINTs und einer expliziten SRID von 4326:
CREATE TABLE ptzgeogwgs84(gid serial PRIMARY KEY, geog geography(POINTZ,4326) );
-
Erstellen Sie eine Tabelle mit der Geografie 2D LINESTRING mit dem Standard-SRID 4326:
CREATE TABLE lgeog(gid serial PRIMARY KEY, geog geography(LINESTRING) );
-
Erstellen Sie eine Tabelle mit einer 2D POLYGON-Geografie mit dem SRID 4267 (NAD 1927 long lat):
CREATE TABLE lgeognad27(gid serial PRIMARY KEY, geog geography(POLYGON,4267) );
Geografische Felder werden in der Systemansicht geography_columns registriert. Sie können die Ansicht geography_columns abfragen und sehen, dass die Tabelle aufgeführt ist:
SELECT * FROM geography_columns;
Das Erstellen eines räumlichen Indexes funktioniert genauso wie bei Geometriespalten. PostGIS stellt fest, dass der Spaltentyp GEOGRAPHIE ist und erstellt einen entsprechenden kugelbasierten Index anstelle des üblichen planaren Index für GEOMETRI.
-- Index the test table with a spherical index CREATE INDEX global_points_gix ON global_points USING GIST ( location );
4.3.2. Verwendung von Geografietabellen
Sie können Daten in Geografietabellen auf dieselbe Weise wie Geometrie einfügen. Geometriedaten werden automatisch in den Geographietyp übertragen, wenn sie SRID 4326 haben. Die Formate EWKT und EWKB können auch zur Angabe von Geografiewerten verwendet werden.
-- Add some data into the test table
INSERT INTO global_points (name, location) VALUES ('Town', 'SRID=4326;POINT(-110 30)');
INSERT INTO global_points (name, location) VALUES ('Forest', 'SRID=4326;POINT(-109 29)');
INSERT INTO global_points (name, location) VALUES ('London', 'SRID=4326;POINT(0 49)');
Jedes in der Tabelle spatial_ref_sys aufgeführte geodätische (long/lat) Raumbezugssystem kann als Geografie-SRID angegeben werden. Nicht-geodätische Koordinatensysteme führen zu einem Fehler, wenn sie verwendet werden.
-- NAD 83 lon/lat
SELECT 'SRID=4269;POINT(-123 34)'::geography;
geography
----------------------------------------------------
0101000020AD1000000000000000C05EC00000000000004140
-- NAD27 lon/lat
SELECT 'SRID=4267;POINT(-123 34)'::geography;
geography
----------------------------------------------------
0101000020AB1000000000000000C05EC00000000000004140
-- NAD83 UTM zone meters - gives an error since it is a meter-based planar projection SELECT 'SRID=26910;POINT(-123 34)'::geography; ERROR: Only lon/lat coordinate systems are supported in geography.
Anfrage und Messfunktionen verwenden die Einheit Meter. Daher sollten Entfernungsparameter in Metern ausgedrückt werden und die Rückgabewerte sollten ebenfalls in Meter (oder Quadratmeter für Flächen) erwartet werden.
-- A distance query using a 1000km tolerance SELECT name FROM global_points WHERE ST_DWithin(location, 'SRID=4326;POINT(-110 29)'::geography, 1000000);
Sie können die Macht der Geografie in Aktion sehen, indem Sie berechnen, wie nahe ein Flugzeug, das eine Großkreisroute von Seattle nach London (LINESTRING(-122.33 47.606, 0.0 51.5)) fliegt, an Reykjavik (POINT(-21.96 64.15)) herankommt (Karte der Route).
Der Geographie-Typ berechnet die wahre kürzeste Entfernung von 122,235 km über die Kugel zwischen Reykjavik und der Großkreisfluglinie zwischen Seattle und London.
-- Distance calculation using GEOGRAPHY
SELECT ST_Distance('LINESTRING(-122.33 47.606, 0.0 51.5)'::geography, 'POINT(-21.96 64.15)'::geography);
st_distance
-----------------
122235.23815667
Der Geometrietyp berechnet eine bedeutungslose kartesische Entfernung zwischen Reykjavik und der geraden Strecke von Seattle nach London, die auf einer flachen Weltkarte eingezeichnet ist. Die nominale Einheit des Ergebnisses ist "Grad", aber das Ergebnis entspricht keiner echten Winkeldifferenz zwischen den Punkten, so dass selbst die Bezeichnung "Grad" ungenau ist.
-- Distance calculation using GEOMETRY
SELECT ST_Distance('LINESTRING(-122.33 47.606, 0.0 51.5)'::geometry, 'POINT(-21.96 64.15)'::geometry);
st_distance
--------------------
13.342271221453624
4.3.3. Wann wird der Datentyp Geografie verwendet?
Der Datentyp GEOGRAPHY ermöglicht die Speicherung von Daten in Längen- und Breitenkoordinaten, allerdings zu einem gewissen Preis: Für GEOGRAPHY sind weniger Funktionen definiert als für GEOMETRY; die definierten Funktionen benötigen mehr CPU-Zeit zur Ausführung.
Der von Ihnen gewählte Datentyp sollte sich nach dem voraussichtlichen Arbeitsbereich der Anwendung richten, die Sie erstellen. Erstrecken sich Ihre Daten über den gesamten Globus oder ein großes kontinentales Gebiet, oder sind sie auf ein Bundesland, einen Bezirk oder eine Gemeinde beschränkt?
-
Wenn sich Ihre Daten in einem kleinen Bereich befinden, werden Sie vermutlich eine passende Projektion wählen und den geometrischen Datentyp verwenden, da dies in Bezug auf die Rechenleistung und die verfügbare Funktionalität die bessere Lösung ist.
-
Wenn Ihre Daten global sind oder einen ganzen Kontinent bedecken, ermöglicht der geographische Datentyp ein System aufzubauen, bei dem Sie sich nicht um Projektionsdetails kümmern müssen. Sie speichern die Daten als Länge und Breite und verwenden dann jene Funktionen, die für den geographischen Datentyp definiert sind.
-
Wenn Sie keine Ahnung von Projektionen haben, sich nicht näher damit beschäftigen wollen und die Einschränkungen der verfügbaren Funktionalität für den geographischen Datentyp in Kauf nehmen können, ist es vermutlich einfacher für Sie, den geographischen anstatt des geometrischen Datentyps zu verwenden.
Für einen Vergleich, welche Funktionalität von Geography vs. Geometry unterstützt wird, siehe Section 13.11, “PostGIS Funktionsunterstützungsmatrix”. Für eine kurze Liste mit der Beschreibung der geographischen Funktionen, siehe Section 13.4, “PostGIS-Funktionen zur Unterstützung der Geografie”
4.3.4. Fortgeschrittene FAQ's zum geographischen Datentyp
- 4.3.4.1. Werden die Berechnungen auf einer Kugel oder auf einem Rotationsellipsoid durchgeführt?
- 4.3.4.2. Wie schaut das mit der Datumsgrenze und den Polen aus?
- 4.3.4.3. Wie lang kann ein Bogen sein, damit er noch verarbeitet werden kann?
- 4.3.4.4. Warum dauert es so lange, die Fläche von Europa / Russland / irgendeiner anderen großen geographischen Region zu berechnen?
|
4.3.4.1. |
Werden die Berechnungen auf einer Kugel oder auf einem Rotationsellipsoid durchgeführt? |
|
Standardmäßig werden alle Entfernungs- und Flächenberechnungen auf dem Referenzellipsoid ausgeführt. Das Ergebnis der Berechnung sollte in lokalen Gebieten gut mit dem planaren Ergebnis zusammenpassen - eine gut gewählte lokale Projektion vorausgesetzt. Bei größeren Gebieten ist die Berechnung über das Referenzellipsoid genauer als eine Berechnung die auf der projizierten Ebene ausgeführt wird. Alle geographischen Funktionen verfügen über eine Option um die Berechnung auf einer Kugel durchzuführen. Dies erreicht man, indem der letzte boolesche Eingabewert auf 'FALSE' gesetzt wird. Dies beschleunigt die Berechnung einigermaßen, insbesondere wenn die Geometrie sehr einfach gestaltet ist. |
|
|
4.3.4.2. |
Wie schaut das mit der Datumsgrenze und den Polen aus? |
|
Alle diese Berechnungen wissen weder über Datumsgrenzen noch über Pole Bescheid. Da es sich um sphärische Koordinaten handelt (Länge und Breite), unterscheidet sich eine Geometrie, die eine Datumsgrenze überschreitet vom Gesichtspunkt der Berechnung her nicht von irgendeiner anderen Geometrie. |
|
|
4.3.4.3. |
Wie lang kann ein Bogen sein, damit er noch verarbeitet werden kann? |
|
Wir verwenden Großkreisbögen als "Interpolationslinie" zwischen zwei Punkten. Das bedeutet, dass es für den Join zwischen zwei Punkten zwei Möglichkeiten gibt, je nachdem, aus welcher Richtung man den Großkreis überquert. Unser gesamter Code setzt voraus, dass die Punkte von der "kürzeren" der beiden Strecken her durch den Großkreis verbunden werden. Als Konsequenz wird eine Geometrie, welche Bögen von mehr als 180 Grad aufweist nicht korrekt modelliert. |
|
|
4.3.4.4. |
Warum dauert es so lange, die Fläche von Europa / Russland / irgendeiner anderen großen geographischen Region zu berechnen? |
|
Weil das Polygon so verdammt groß ist! Große Flächen sind aus zwei Gründen schlecht: ihre Begrenzung ist riesig, wodurch der Index dazu tendiert, das Geoobjekt herauszuholen, egal wie Sie die Anfrage ausführen; die Anzahl der Knoten ist riesig, und Tests (wie ST_Distance, ST_Contains) müssen alle Knoten zumindest einmal, manchmal sogar n-mal durchlaufen (wobei N die Anzahl der Knoten im beteiligten Geoobjekt bezeichnet). Wenn es sich um sehr große Polygone handelt, die Abfragen aber nur in kleinen Gebieten stattfinden, empfehlen wir wie beim geometrischen Datentyp, dass Sie die Geometrie in kleinere Stücke "denormalisieren". Dadurch kann der Index effiziente Unterabfragen auf Teile des Geoobjekts ausführen, da eine Abfrage nicht jedesmal das gesamte Geoobjekt herausholen muss. Konsultieren Sie dazu bitte die Dokumentation der FunktionST_Subdivide. Nur weil Sie ganz Europa in einem Polygon speichern *können* heißt das nicht, dass Sie dies auch tun *sollten*. |
4.4. Geometrievalidierung
PostGIS ist mit der Spezifikation Simple Features des Open Geospatial Consortium (OGC) konform. Dieser Standard definiert die Konzepte der Geometrie simple und valid. Diese Definitionen ermöglichen es dem Simple-Features-Geometriemodell, räumliche Objekte in einer konsistenten und eindeutigen Weise darzustellen, die effiziente Berechnungen unterstützt. (Anmerkung: OGC SF und SQL/MM haben die gleichen Definitionen für einfach und gültig).
4.4.1. Einfache Geometrie
Eine einfache Geometrie ist eine Geometrie, die keine anomalen geometrischen Punkte wie Selbstschnittpunkte oder Selbsttangenten aufweist.
Ein POINT ist von Natur aus einfach als ein 0-dimensionales Geometrieobjekt.
MULTIPOINTs sind simple, wenn sich keine zwei Koordinaten (POINTs) decken (keine identischen Koordinatenpaare aufweisen).
Ein LINESTRING ist einfach, wenn er, abgesehen von den Endpunkten, nicht zweimal durch denselben Punkt verläuft. Wenn die Endpunkte eines einfachen Linienstrangs identisch sind, wird er geschlossen und als linearer Ring bezeichnet.
|
(a) und (c) sind einfache |
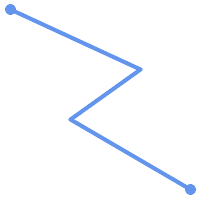
(a) |
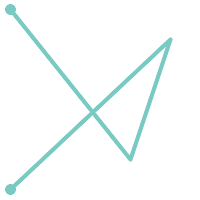
(b) |
(c) |
(d) |
Ein MULTILINESTRING ist nur dann einfach, wenn alle seine Elemente einfach sind und der einzige Schnittpunkt zwischen zwei beliebigen Elementen an Punkten auftritt, die auf den Grenzen der beiden Elemente liegen.
|
(e) und (f) sind einfache |
(e) |
(f) |
(g) |
POLYGONs werden aus linearen Ringen gebildet, daher ist eine gültige polygonale Geometrie immer einfach.
Um zu prüfen, ob eine Geometrie einfach ist, verwenden Sie die Funktion ST_IsSimple:
SELECT
ST_IsSimple('LINESTRING(0 0, 100 100)') AS straight,
ST_IsSimple('LINESTRING(0 0, 100 100, 100 0, 0 100)') AS crossing;
straight | crossing
----------+----------
t | f
Im Allgemeinen verlangen PostGIS-Funktionen nicht, dass geometrische Argumente einfach sind. Die Einfachheit wird in erster Linie als Grundlage für die Definition der geometrischen Gültigkeit verwendet. Sie ist auch eine Voraussetzung für einige Arten von Geodatenmodellen (z. B. lassen lineare Netze oft keine Linien zu, die sich kreuzen). Mehrpunkt- und lineare Geometrie kann mit ST_UnaryUnion vereinfacht werden.
4.4.2. Gültige Geometrie
Die Gültigkeit der Geometrie gilt in erster Linie für 2-dimensionale Geometrien (POLYGONs und MULTIPOLYGONs) . Die Gültigkeit wird durch Regeln definiert, die es der polygonalen Geometrie ermöglichen, ebene Flächen eindeutig zu modellieren.
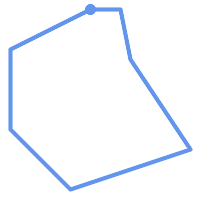
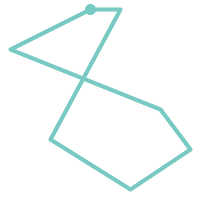
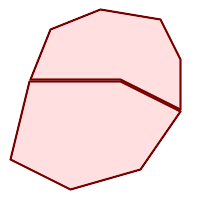
Ein POLYGON ist gültig wenn:
-
Die Begrenzungsringe des Polygons (der äußere Schalenring und die inneren Lochringe) sind einfach (kreuzen sich nicht und berühren sich nicht). Aus diesem Grund kann ein Polygon keine Schnittlinien, Zacken oder Schleifen haben. Dies bedeutet, dass Polygonlöcher als innere Ringe dargestellt werden müssen, anstatt dass der äußere Ring sich selbst berührt (ein sogenanntes "umgekehrtes Loch").
-
Grenzringe kreuzen sich nicht
-
Begrenzungsringe können sich in Punkten berühren, aber nur als Tangente (d. h. nicht in einer Linie)
-
innere Ringe sind im äußeren Ring enthalten
-
das Innere des Polygons ist einfach verbunden (d. h. die Ringe dürfen sich nicht so berühren, dass das Polygon in mehr als einen Teil zerfällt)
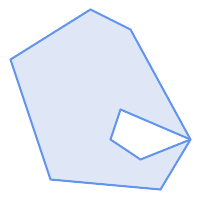
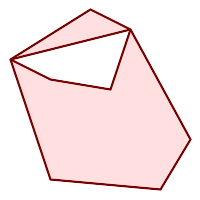
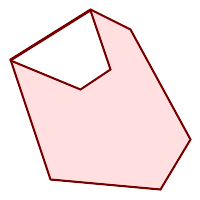
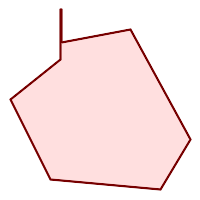
|
(h) und (i) sind gültig |
(h) |
(i) |
(j) |
(k) |
(l) |
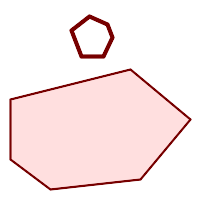
(m) |
Ein MULTIPOLYGON ist gültig wenn:
-
sein Element
POLYGONs gültig sind -
die Elemente dürfen sich nicht überschneiden (d. h. ihre Innenräume dürfen sich nicht überschneiden)
-
Elemente berühren sich nur an Punkten (d. h. nicht entlang einer Linie)
|
(n) ist ein gültiges |
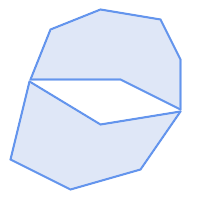
(n) |
(o) |
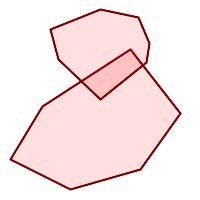
(p) |
Diese Regeln bedeuten, dass gültige polygonale Geometrie auch einfach ist.
Für die lineare Geometrie ist die einzige Gültigkeitsregel, dass LINESTRINGs mindestens zwei Punkte und eine Länge ungleich Null haben muss (oder äquivalent dazu mindestens zwei verschiedene Punkte.) Beachten Sie, dass nicht-einfache (sich selbst schneidende) Linien gültig sind.
SELECT
ST_IsValid('LINESTRING(0 0, 1 1)') AS len_nonzero,
ST_IsValid('LINESTRING(0 0, 0 0, 0 0)') AS len_zero,
ST_IsValid('LINESTRING(10 10, 150 150, 180 50, 20 130)') AS self_int;
len_nonzero | len_zero | self_int
-------------+----------+----------
t | f | t
Die Geometrien POINT und MULTIPOINT haben keine Gültigkeitsregeln.
4.4.3. Verwaltung der Gültigkeit
PostGIS ermöglicht die Erstellung und Speicherung von gültiger und ungültiger Geometrie. Dies ermöglicht es, ungültige Geometrie zu erkennen und zu markieren oder zu korrigieren. Es gibt auch Situationen, in denen die OGC-Gültigkeitsregeln strenger sind als erwünscht (Beispiele hierfür sind Linienstränge mit Nulllänge und Polygone mit invertierten Löchern).
Viele der von PostGIS bereitgestellten Funktionen beruhen auf der Annahme, dass die Geometrieargumente gültig sind. So ist es beispielsweise nicht sinnvoll, die Fläche eines Polygons zu berechnen, in dem ein Loch außerhalb des Polygons definiert ist, oder ein Polygon aus einer nicht einfachen Begrenzungslinie zu konstruieren. Durch die Annahme gültiger geometrischer Eingaben können die Funktionen effizienter arbeiten, da sie nicht auf topologische Korrektheit geprüft werden müssen. (Bemerkenswerte Ausnahmen sind Linien der Länge Null und Polygone mit Invertierungen, die im Allgemeinen korrekt behandelt werden). Außerdem erzeugen die meisten PostGIS-Funktionen eine gültige Geometrieausgabe, wenn die Eingaben gültig sind. Dadurch können PostGIS-Funktionen sicher miteinander verkettet werden.
Wenn Sie beim Aufruf von PostGIS-Funktionen unerwartete Fehlermeldungen erhalten (z. B. "GEOS Intersection() hat einen Fehler ausgelöst!"), sollten Sie sich zunächst vergewissern, dass die Argumente der Funktion gültig sind. Wenn dies nicht der Fall ist, sollten Sie eine der folgenden Techniken anwenden, um sicherzustellen, dass die zu verarbeitenden Daten gültig sind.
|
|
|
|
Wenn eine Funktion bei gültigen Eingaben einen Fehler meldet, dann haben Sie möglicherweise einen Fehler in PostGIS oder in einer der verwendeten Bibliotheken gefunden und sollten dies dem PostGIS-Projekt melden. Dasselbe gilt, wenn eine PostGIS-Funktion bei gültiger Eingabe eine ungültige Geometrie zurückgibt. |
Um zu prüfen, ob eine Geometrie gültig ist, verwenden Sie die Funktion ST_IsValid:
SELECT ST_IsValid('POLYGON ((20 180, 180 180, 180 20, 20 20, 20 180))');
-----------------
t
Informationen über die Art und den Ort einer geometrischen Ungültigkeit werden von der Funktion ST_IsValidDetail geliefert:
SELECT valid, reason, ST_AsText(location) AS location
FROM ST_IsValidDetail('POLYGON ((20 20, 120 190, 50 190, 170 50, 20 20))') AS t;
valid | reason | location
-------+-------------------+---------------------------------------------
f | Self-intersection | POINT(91.51162790697674 141.56976744186045)
In manchen Situationen ist es wünschenswert, ungültige Geometrien automatisch zu korrigieren. Verwenden Sie dazu die Funktion ST_MakeValid. (ST_MakeValid ist ein Fall einer räumlichen Funktion, die ungültige Eingaben zulässt!)
Standardmäßig prüft PostGIS beim Laden von Geometrien nicht auf Gültigkeit, da die Gültigkeitsprüfung bei komplexen Geometrien viel CPU-Zeit in Anspruch nehmen kann. Wenn Sie Ihren Datenquellen nicht trauen, können Sie eine Gültigkeitsprüfung für Ihre Tabellen erzwingen, indem Sie eine Prüfbeschränkung hinzufügen:
ALTER TABLE mytable
ADD CONSTRAINT geometry_valid_check
CHECK (ST_IsValid(geom));
4.5. Räumliche Bezugssysteme
Ein Raumbezugssystem (SRS) (auch Koordinatenreferenzsystem (CRS) genannt) definiert, wie die Geometrie auf Orte auf der Erdoberfläche bezogen wird. Es gibt drei Arten von SRS:
-
Ein geodätisches SRS verwendet Winkelkoordinaten (Längen- und Breitengrad), die direkt auf der Erdoberfläche abgebildet werden.
-
Eine projizierte SRS verwendet eine mathematische Projektionstransformation, um die Oberfläche der sphäroidischen Erde auf eine Ebene zu "glätten". Dabei werden Ortskoordinaten so zugewiesen, dass eine direkte Messung von Größen wie Entfernung, Fläche und Winkel möglich ist. Das Koordinatensystem ist kartesisch, d. h. es hat einen definierten Ursprungspunkt und zwei senkrecht zueinander stehende Achsen (in der Regel nach Norden und Osten ausgerichtet). Jede projizierte SRS verwendet eine bestimmte Längeneinheit (in der Regel Meter oder Fuß). Ein projiziertes SRS kann in seinem Anwendungsbereich begrenzt sein, um Verzerrungen zu vermeiden und in die definierten Koordinatengrenzen zu passen.
-
Ein local SRS ist ein kartesisches Koordinatensystem, das nicht auf die Erdoberfläche referenziert ist. In PostGIS wird dies durch einen SRID-Wert von 0 angegeben.
Es gibt viele verschiedene räumliche Bezugssysteme, die verwendet werden. Die gängigen SRS sind in der European Petroleum Survey Group EPSG-Datenbank standardisiert. Der Einfachheit halber bezieht sich PostGIS (und viele andere raumbezogene Systeme) auf SRS-Definitionen unter Verwendung eines ganzzahligen Bezeichners, der SRID genannt wird.
Eine Geometrie ist mit einem räumlichen Bezugssystem durch ihren SRID-Wert verbunden, auf den über ST_SRID zugegriffen wird. Der SRID für eine Geometrie kann mit ST_SetSRID zugewiesen werden. Einige Geometriekonstruktorfunktionen ermöglichen die Angabe eines SRID (z. B. ST_Point und ST_MakeEnvelope). Das Format EWKT unterstützt SRIDs mit dem Präfix SRID=n;.
Räumliche Funktionen, die Paare von Geometrien verarbeiten (z. B. die Funktionen overlay und relationship ), setzen voraus, dass die eingegebenen Geometrien im selben räumlichen Bezugssystem (mit demselben SRID) vorliegen. Geometriedaten können mit ST_Transform und ST_TransformPipeline in ein anderes räumliches Bezugssystem transformiert werden. Die von den Funktionen zurückgegebenen Geometrien haben dasselbe SRS wie die Eingabegeometrien.
4.5.1. SPATIAL_REF_SYS Tabelle
Die von PostGIS verwendete Tabelle SPATIAL_REF_SYS ist eine OGC-konforme Datenbanktabelle, die die verfügbaren räumlichen Bezugssysteme definiert. Sie enthält die numerischen SRIDs und textuelle Beschreibungen der Koordinatensysteme.
Die Definition der Tabelle spatial_ref_sys lautet:
CREATE TABLE spatial_ref_sys ( srid INTEGER NOT NULL PRIMARY KEY, auth_name VARCHAR(256), auth_srid INTEGER, srtext VARCHAR(2048), proj4text VARCHAR(2048) )
Die Spalten sind:
-
srid -
Ein ganzzahliger Code, der das Raumbezugssystem (SRS) innerhalb der Datenbank eindeutig identifiziert.
-
auth_name -
Der Name der Norm oder des Normungsgremiums, das für dieses Referenzsystem zitiert wird. Zum Beispiel ist "EPSG" ein gültiger
auth_name. -
auth_srid -
Die ID des räumlichen Bezugssystems, wie von der in
auth_namegenannten Behörde definiert. Im Falle der EPSG ist dies der EPSG-Code. -
srtext -
Die Well-Known-Text Darstellung des Koordinatenreferenzsystems. Ein Beispiel dazu:
PROJCS["NAD83 / UTM Zone 10N", GEOGCS["NAD83", DATUM["North_American_Datum_1983", SPHEROID["GRS 1980",6378137,298.257222101] ], PRIMEM["Greenwich",0], UNIT["degree",0.0174532925199433] ], PROJECTION["Transverse_Mercator"], PARAMETER["latitude_of_origin",0], PARAMETER["central_meridian",-123], PARAMETER["scale_factor",0.9996], PARAMETER["false_easting",500000], PARAMETER["false_northing",0], UNIT["metre",1] ]Eine Diskussion über SRS WKT findet sich im OGC-Standard Well-known text representation of coordinate reference systems.
-
proj4text -
PostGIS verwendet die PROJ-Bibliothek, um Koordinatentransformationen zu ermöglichen. Die Spalte
proj4textenthält die PROJ-Koordinatendefinitionszeichenfolge für eine bestimmte SRID. Zum Beispiel:+proj=utm +zone=10 +ellps=clrk66 +datum=NAD27 +units=m
Weitere Informationen finden Sie auf der PROJ-Website. Die Datei
spatial_ref_sys.sqlenthält sowohlsrtextals auchproj4textDefinitionen für alle EPSG-Projektionen.
Beim Abrufen von Definitionen für räumliche Bezugssysteme zur Verwendung in Transformationen verwendet PostGIS die folgende Strategie:
-
Wenn
auth_nameundauth_sridvorhanden sind (nicht NULL), verwenden Sie den PROJ SRS, der auf diesen Einträgen basiert (falls einer existiert). -
Wenn
srtextvorhanden ist, erstellen Sie, wenn möglich, ein SRS mit diesem Text. -
Wenn
proj4textvorhanden ist, erstellen Sie, wenn möglich, eine SRS mit diesem Text.
4.5.2. Benutzerdefinierte räumliche Bezugssysteme
Die PostGIS-Tabelle spatial_ref_sys enthält über 3000 der gebräuchlichsten Definitionen für räumliche Bezugssysteme, die von der Projektionsbibliothek PROJ verarbeitet werden. Es gibt jedoch viele Koordinatensysteme, die darin nicht enthalten sind. Sie können der Tabelle SRS-Definitionen hinzufügen, wenn Sie die erforderlichen Informationen über das räumliche Bezugssystem haben. Sie können aber auch Ihr eigenes räumliches Bezugssystem definieren, wenn Sie mit den PROJ-Konstruktionen vertraut sind. Denken Sie daran, dass die meisten räumlichen Bezugssysteme regional sind und keine Bedeutung haben, wenn sie außerhalb der Grenzen verwendet werden, für die sie bestimmt sind.
Eine Ressource zum Auffinden von nicht im Kernsatz definierten räumlichen Bezugssystemen ist http://spatialreference.org/
Einige häufig verwendete Raumbezugssysteme sind: 4326 - WGS 84 Long Lat, 4269 - NAD 83 Long Lat, 3395 - WGS 84 World Mercator, 2163 - US National Atlas Equal Area, und die 60 WGS84 UTM-Zonen. UTM-Zonen sind mit am besten für Messungen geeignet, decken aber nur 6-Grad-Regionen ab. (Um zu bestimmen, welche UTM-Zone für Ihr Gebiet von Interesse zu verwenden ist, siehe utmzone PostGIS plpgsql helper function).
Die US-Bundesstaaten verwenden State Plane-Raumbezugssysteme (meter- oder feet-basiert) - in der Regel gibt es ein oder zwei pro Staat. Die meisten der Meter-basierten Systeme sind im Kernsatz enthalten, aber viele der Fuß-basierten oder von ESRI erstellten Systeme müssen von spatialreference.org kopiert werden.
Sie können sogar Koordinatensysteme definieren, die nicht auf der Erde basieren, wie z.B. Mars 2000 Dieses Marskoordinatensystem ist nicht planar (es ist in Grad sphäroidisch), aber Sie können es mit dem Typ Geographie verwenden, um Längen- und Entfernungsmessungen in Metern statt in Grad zu erhalten.
Hier ein Beispiel für das Laden eines benutzerdefinierten Koordinatensystems unter Verwendung eines nicht zugewiesenen SRID und der PROJ-Definition für eine US-zentrische Lambert-konforme Projektion:
INSERT INTO spatial_ref_sys (srid, proj4text) VALUES ( 990000, '+proj=lcc +lon_0=-95 +lat_0=25 +lat_1=25 +lat_2=25 +x_0=0 +y_0=0 +datum=WGS84 +units=m +no_defs' );
4.6. Räumliche Tabellen
4.6.1. Erstellung einer räumlichen Tabelle
Sie können eine Tabelle zur Speicherung von Geometriedaten mit der SQL-Anweisung CREATE TABLE mit einer Spalte vom Typ Geometrie erstellen. Das folgende Beispiel erstellt eine Tabelle mit einer Geometriespalte, die 2D (XY) LineStrings im BC-Albers-Koordinatensystem (SRID 3005) speichert:
CREATE TABLE roads (
id SERIAL PRIMARY KEY,
name VARCHAR(64),
geom geometry(LINESTRING,3005)
);
Der Geometrietyp unterstützt zwei optionale Typmodifikatoren:
-
der spatial type modifier schränkt die Art der in der Spalte zulässigen Formen und Abmessungen ein. Der Wert kann einer der unterstützten Geometrie-Subtypen sein (z. B. POINT, LINESTRING, POLYGON, MULTIPOINT, MULTILINESTRING, MULTIPOLYGON, GEOMETRYCOLLECTION, usw.). Der Modifikator unterstützt Einschränkungen der Koordinatendimensionalität durch Hinzufügen von Suffixen: Z, M und ZM. Ein Modifikator 'LINESTRINGM' lässt beispielsweise nur Linienzüge mit drei Dimensionen zu und behandelt die dritte Dimension als Maß. In ähnlicher Weise erfordert 'POINTZM' vierdimensionale (XYZM) Daten.
-
Der SRID-Modifikator schränkt das Raumbezugssystem SRID auf eine bestimmte Zahl ein. Wird der Modifikator weggelassen, ist das SRID standardmäßig auf 0 gesetzt.
Beispiele für die Erstellung von Tabellen mit Geometriespalten:
-
Erstellen Sie eine Tabelle, die jede Art von Geometrie mit dem Standard-SRID enthält:
CREATE TABLE geoms(gid serial PRIMARY KEY, geom geometry );
-
Erstellen Sie eine Tabelle mit 2D-Punktgeometrie mit dem Standard-SRID:
CREATE TABLE pts(gid serial PRIMARY KEY, geom geometry(POINT) );
-
Erstellen Sie eine Tabelle mit 3D (XYZ) POINTs und einer expliziten SRID von 3005:
CREATE TABLE pts(gid serial PRIMARY KEY, geom geometry(POINTZ,3005) );
-
Erstellen Sie eine Tabelle mit 4D (XYZM) LINESTRING-Geometrie mit dem Standard-SRID:
CREATE TABLE lines(gid serial PRIMARY KEY, geom geometry(LINESTRINGZM) );
-
Erstellen Sie eine Tabelle mit 2D POLYGON Geometrie mit dem SRID 4267 (NAD 1927 long lat):
CREATE TABLE polys(gid serial PRIMARY KEY, geom geometry(POLYGON,4267) );
Es ist möglich, mehr als eine Geometriespalte in einer Tabelle zu haben. Dies kann bei der Erstellung der Tabelle angegeben werden, oder eine Spalte kann mit der SQL-Anweisung ALTER TABLE hinzugefügt werden. In diesem Beispiel wird eine Spalte hinzugefügt, die 3D LineStrings enthalten kann:
ALTER TABLE roads ADD COLUMN geom2 geometry(LINESTRINGZ,4326);
4.6.2. GEOMETRY_COLUMNS Ansicht
Die OGC Simple Features Specification for SQL definiert die GEOMETRY_COLUMNS Metadatentabelle zur Beschreibung der Geometrietabellenstruktur. In PostGIS ist geometry_columns ein View, der aus Katalogtabellen des Datenbanksystems gelesen wird. Dadurch wird sichergestellt, dass die räumlichen Metadateninformationen immer mit den aktuell definierten Tabellen und Views konsistent sind. Die Struktur des Views ist:
\d geometry_columns
View "public.geometry_columns"
Column | Type | Modifiers
-------------------+------------------------+-----------
f_table_catalog | character varying(256) |
f_table_schema | character varying(256) |
f_table_name | character varying(256) |
f_geometry_column | character varying(256) |
coord_dimension | integer |
srid | integer |
type | character varying(30) |
Die Spalten sind:
-
f_table_catalog, f_table_schema, f_table_name -
Der voll qualifizierte Name der Merkmalstabelle, die die Geometriespalte enthält. Es gibt kein PostgreSQL-Analogon für "catalog", daher wird diese Spalte leer gelassen. Für "schema" wird der Name des PostgreSQL-Schemas verwendet (
publicist der Standard). -
f_geometry_column -
Der Name der Geometriespalte in der Feature-Tabelle.
-
coord_dimension -
Die Koordinatenabmessung (2, 3 oder 4) der Spalte.
-
srid -
Die ID des räumlichen Bezugssystems, das für die Koordinatengeometrie in dieser Tabelle verwendet wird. Es handelt sich um einen Fremdschlüsselverweis auf die Tabelle
spatial_ref_sys(siehe Section 4.5.1, “SPATIAL_REF_SYS Tabelle”). -
type -
Der Datentyp des Geoobjekts. Um die räumliche Spalte auf einen einzelnen Datentyp zu beschränken, benutzen Sie bitte: POINT, LINESTRING, POLYGON, MULTIPOINT, MULTILINESTRING, MULTIPOLYGON, GEOMETRYCOLLECTION oder die entsprechenden XYM Versionen POINTM, LINESTRINGM, POLYGONM, MULTIPOINTM, MULTILINESTRINGM, MULTIPOLYGONM und GEOMETRYCOLLECTIONM. Für uneinheitliche Kollektionen (gemischete Datentypen) können Sie den Datentyp "GEOMETRY" verwenden.
4.6.3. Manuelles Registrieren von Geometriespalten
Zwei Fälle bei denen Sie dies benötigen könnten sind SQL-Views und Masseninserts. Beim Fall von Masseninserts können Sie die Registrierung in der Tabelle "geometry_columns" korrigieren, indem Sie auf die Spalte einen CONSTRAINT setzen oder ein "ALTER TABLE" durchführen. Falls Ihre Spalte Typmod basiert ist, geschieht die Registrierung beim Erstellungsprozess auf korrekte Weise, so dass Sie hier nichts tun müssen. Auch Views, bei denen keine räumliche Funktion auf die Geometrie angewendet wird, werden auf gleiche Weise wie die Geometrie der zugrunde liegenden Tabelle registriert.
-- Lets say you have a view created like this
CREATE VIEW public.vwmytablemercator AS
SELECT gid, ST_Transform(geom, 3395) As geom, f_name
FROM public.mytable;
-- For it to register correctly
-- You need to cast the geometry
--
DROP VIEW public.vwmytablemercator;
CREATE VIEW public.vwmytablemercator AS
SELECT gid, ST_Transform(geom, 3395)::geometry(Geometry, 3395) As geom, f_name
FROM public.mytable;
-- If you know the geometry type for sure is a 2D POLYGON then you could do
DROP VIEW public.vwmytablemercator;
CREATE VIEW public.vwmytablemercator AS
SELECT gid, ST_Transform(geom,3395)::geometry(Polygon, 3395) As geom, f_name
FROM public.mytable;
--Lets say you created a derivative table by doing a bulk insert
SELECT poi.gid, poi.geom, citybounds.city_name
INTO myschema.my_special_pois
FROM poi INNER JOIN citybounds ON ST_Intersects(citybounds.geom, poi.geom);
-- Create 2D index on new table
CREATE INDEX idx_myschema_myspecialpois_geom_gist
ON myschema.my_special_pois USING gist(geom);
-- If your points are 3D points or 3M points,
-- then you might want to create an nd index instead of a 2D index
CREATE INDEX my_special_pois_geom_gist_nd
ON my_special_pois USING gist(geom gist_geometry_ops_nd);
-- To manually register this new table's geometry column in geometry_columns.
-- Note it will also change the underlying structure of the table to
-- to make the column typmod based.
SELECT populate_geometry_columns('myschema.my_special_pois'::regclass);
-- If you are using PostGIS 2.0 and for whatever reason, you
-- you need the constraint based definition behavior
-- (such as case of inherited tables where all children do not have the same type and srid)
-- set optional use_typmod argument to false
SELECT populate_geometry_columns('myschema.my_special_pois'::regclass, false);
Obwohl die alte auf CONSTRAINTs basierte Methode immer noch unterstützt wird, wird eine auf Constraints basierende Geometriespalte, die direkt in einem View verwendet wird, nicht korrekt in geometry_columns registriert. Eine Typmod basierte wird korrekt registriert. Im folgenden Beispiel definieren wir eine Spalte mit Typmod und eine andere mit Constraints.
CREATE TABLE pois_ny(gid SERIAL PRIMARY KEY, poi_name text, cat text, geom geometry(POINT,4326));
SELECT AddGeometryColumn('pois_ny', 'geom_2160', 2160, 'POINT', 2, false);
In psql:
\d pois_ny;
Wir sehen, das diese Spalten unterschiedlich definiert sind -- eine mittels Typmodifizierer, eine nutzt einen Constraint
Table "public.pois_ny"
Column | Type | Modifiers
-----------+-----------------------+------------------------------------------------------
gid | integer | not null default nextval('pois_ny_gid_seq'::regclass)
poi_name | text |
cat | character varying(20) |
geom | geometry(Point,4326) |
geom_2160 | geometry |
Indexes:
"pois_ny_pkey" PRIMARY KEY, btree (gid)
Check constraints:
"enforce_dims_geom_2160" CHECK (st_ndims(geom_2160) = 2)
"enforce_geotype_geom_2160" CHECK (geometrytype(geom_2160) = 'POINT'::text
OR geom_2160 IS NULL)
"enforce_srid_geom_2160" CHECK (st_srid(geom_2160) = 2160)
Beide registrieren sich korrekt in "geometry_columns"
SELECT f_table_name, f_geometry_column, srid, type
FROM geometry_columns
WHERE f_table_name = 'pois_ny';
f_table_name | f_geometry_column | srid | type -------------+-------------------+------+------- pois_ny | geom | 4326 | POINT pois_ny | geom_2160 | 2160 | POINT
Jedoch -- wenn wir einen View auf die folgende Weise erstellen
CREATE VIEW vw_pois_ny_parks AS
SELECT *
FROM pois_ny
WHERE cat='park';
SELECT f_table_name, f_geometry_column, srid, type
FROM geometry_columns
WHERE f_table_name = 'vw_pois_ny_parks';
Die Typmod basierte geometrische Spalte eines View registriert sich korrekt, die auf Constraint basierende nicht.
f_table_name | f_geometry_column | srid | type ------------------+-------------------+------+---------- vw_pois_ny_parks | geom | 4326 | POINT vw_pois_ny_parks | geom_2160 | 0 | GEOMETRY
Dies kann sich in zukünftigen Versionen von PostGIS ändern, aber im Moment müssen Sie dies tun, um die korrekte Registrierung der einschränkungsbasierten Ansichtsspalte zu erzwingen:
DROP VIEW vw_pois_ny_parks;
CREATE VIEW vw_pois_ny_parks AS
SELECT gid, poi_name, cat,
geom,
geom_2160::geometry(POINT,2160) As geom_2160
FROM pois_ny
WHERE cat = 'park';
SELECT f_table_name, f_geometry_column, srid, type
FROM geometry_columns
WHERE f_table_name = 'vw_pois_ny_parks';
f_table_name | f_geometry_column | srid | type ------------------+-------------------+------+------- vw_pois_ny_parks | geom | 4326 | POINT vw_pois_ny_parks | geom_2160 | 2160 | POINT
4.7. Laden von Geodaten
Sobald Sie eine Geodatentabelle erstellt haben, können Sie Geodaten in die Datenbank hochladen. Es gibt zwei eingebaute Möglichkeiten, Geodaten in eine PostGIS/PostgreSQL-Datenbank zu übertragen: mit formatierten SQL-Anweisungen oder mit dem Shapefile-Loader.
4.7.1. SQL zum Laden von Daten verwenden
Wenn raumbezogene Daten in eine Textdarstellung konvertiert werden können (entweder als WKT oder WKB), dann ist die Verwendung von SQL möglicherweise der einfachste Weg, um Daten in PostGIS zu erhalten. Daten können in großem Umfang in PostGIS/PostgreSQL geladen werden, indem eine Textdatei mit SQL INSERT Anweisungen mit dem psql SQL-Dienstprogramm geladen wird.
Eine SQL-Ladedatei (z. B.roads.sql ) könnte wie folgt aussehen:
BEGIN; INSERT INTO roads (road_id, roads_geom, road_name) VALUES (1,'LINESTRING(191232 243118,191108 243242)','Jeff Rd'); INSERT INTO roads (road_id, roads_geom, road_name) VALUES (2,'LINESTRING(189141 244158,189265 244817)','Geordie Rd'); INSERT INTO roads (road_id, roads_geom, road_name) VALUES (3,'LINESTRING(192783 228138,192612 229814)','Paul St'); INSERT INTO roads (road_id, roads_geom, road_name) VALUES (4,'LINESTRING(189412 252431,189631 259122)','Graeme Ave'); INSERT INTO roads (road_id, roads_geom, road_name) VALUES (5,'LINESTRING(190131 224148,190871 228134)','Phil Tce'); INSERT INTO roads (road_id, roads_geom, road_name) VALUES (6,'LINESTRING(198231 263418,198213 268322)','Dave Cres'); COMMIT;
Die SQL-Datei kann mit psql in PostgreSQL geladen werden:
psql -d [database] -f roads.sql
4.7.2. Verwendung des Shapefile Loaders
Der shp2pgsql Datenlader konvertiert Shapefiles in SQL, das zum Einfügen in eine PostGIS/PostgreSQL-Datenbank geeignet ist, entweder im Geometrie- oder im Geografieformat. Der Lader hat mehrere Betriebsmodi, die über Kommandozeilenflags ausgewählt werden können.
Es gibt auch eine grafische Schnittstelle shp2pgsql-gui mit den meisten Optionen des Befehlszeilen-Laders. Dies kann für einmaliges, nicht skriptgesteuertes Laden oder für PostGIS-Neulinge einfacher zu verwenden sein. Es kann auch als Plugin für PgAdminIII konfiguriert werden.
- (c|a|d|p) Dies sind sich gegenseitig ausschließende Optionen:
-
-
-c -
Erzeugt eine neue Tabelle und füllt sie aus dem Shapefile. Dies ist der Standardmodus.
-
-a -
Fügt Daten aus dem Shapefile in die Datenbanktabelle ein. Beachten Sie, dass die Dateien die gleichen Attribute und Datentypen haben müssen, um mit dieser Option mehrere Dateien zu laden.
-
-d -
Löscht die Datenbanktabelle, bevor eine neue Tabelle mit den Daten im Shapefile erstellt wird.
-
-p -
Erzeugt nur den SQL-Code zur Erstellung der Tabelle, ohne irgendwelche Daten hinzuzufügen. Kann verwendet werden, um die Erstellung und das Laden einer Tabelle vollständig zu trennen.
-
-
-? -
Zeigt die Hilfe an.
-
-D -
Verwendung des PostgreSQL "dump" Formats für die Datenausgabe. Kann mit -a, -c und -d kombiniert werden. Ist wesentlich schneller als das standardmäßige SQL "insert" Format. Verwenden Sie diese Option wenn Sie sehr große Datensätze haben.
-
-s [<FROM_SRID>:]<SRID> -
Erstellt und befüllt die Geometrietabelle mit der angegebenen SRID. Optional kann für das Shapefile eine FROM_SRID angegeben werden, worauf dann die Geometrie in die Ziel-SRID projiziert wird.
-
-k -
Erhält die Groß- und Kleinschreibung (Spalte, Schema und Attribute). Beachten Sie bitte, dass die Attributnamen in Shapedateien immer Großbuchstaben haben.
-
-i -
Wandeln Sie alle Ganzzahlen in standard 32-bit Integer um, erzeugen Sie keine 64-bit BigInteger, auch nicht dann wenn der DBF-Header dies unterstellt.
-
-I -
Einen GIST Index auf die Geometriespalte anlegen.
-
-m -
-m
a_file_namebestimmt eine Datei, in welcher die Abbildungen der (langen) Spaltennamen in die 10 Zeichen langen DBF Spaltennamen festgelegt sind. Der Inhalt der Datei besteht aus einer oder mehreren Zeilen die jeweils zwei, durch Leerzeichen getrennte Namen enthalten, aber weder vorne noch hinten mit Leerzeichen versehen werden dürfen. Zum Beispiel:COLUMNNAME DBFFIELD1 AVERYLONGCOLUMNNAME DBFFIELD2
-
-S -
Erzeugt eine Einzel- anstatt einer Mehrfachgeometrie. Ist nur erfolgversprechend, wenn die Geometrie auch tatsächlich eine Einzelgeometrie ist (insbesondere gilt das für ein Mehrfachpolygon/MULTIPOLYGON, dass nur aus einer einzelnen Begrenzung besteht, oder für einen Mehrfachpunkt/MULTIPOINT, der nur einen einzigen Knoten aufweist).
-
-t <dimensionality> -
Zwingt die Ausgabegeometrie eine bestimmte Dimension anzunehmen. Sie können die folgenden Zeichenfolgen verwenden, um die Dimensionalität anzugeben: 2D, 3DZ, 3DM, 4D.
Wenn die Eingabe weniger Dimensionen aufweist als angegeben, dann werden diese Dimensionen bei der Ausgabe mit Nullen gefüllt. Wenn die Eingabe mehr Dimensionen als angegeben aufweist werden diese abgestreift.
-
-w -
Ausgabe im Format WKT anstatt WKB. Beachten Sie bitte, dass es hierbei zu Koordinatenverschiebungen infolge von Genauigkeitsverlusten kommen kann.
-
-e -
Jede Anweisung einzeln und nicht in einer Transaktion ausführen. Dies erlaubt den Großteil auch dann zu laden, also die guten Daten, wenn eine Geometrie dabei ist die Fehler verursacht. Beachten Sie bitte das dies nicht gemeinsam mit der -D Flag angegeben werden kann, da das "dump" Format immer eine Transaktion verwendet.
-
-W <encoding> -
Gibt die Codierung der Eingabedaten (dbf-Datei) an. Wird die Option verwendet, so werden alle Attribute der dbf-Datei von der angegebenen Codierung nach UTF8 konvertiert. Die resultierende SQL-Ausgabe enthält dann den Befehl
SET CLIENT_ENCODING to UTF8, damit das Back-end wiederum die Möglichkeit hat, von UTF8 in die, für die interne Nutzung konfigurierte Datenbankcodierung zu decodieren. -
-N <policy> -
Umgang mit NULL-Geometrien (insert*, skip, abort)
-
-n -
-n Es wird nur die *.dbf-Datei importiert. Wenn das Shapefile nicht Ihren Daten entspricht, wird automatisch auf diesen Modus geschaltet und nur die *.dbf-Datei geladen. Daher müssen Sie diese Flag nur dann setzen, wenn sie einen vollständigen Shapefile-Satz haben und lediglich die Attributdaten, und nicht die Geometrie, laden wollen.
-
-G -
Verwendung des geographischen Datentyps in WGS84 (SRID=4326), anstelle des geometrischen Datentyps (benötigt Längen- und Breitenangaben).
-
-T <tablespace> -
Den Tablespace für die neue Tabelle festlegen. Solange der -X Parameter nicht angegeben wird, benutzen die Indizes weiterhin den standardmäßig festgelegten Tablespace. Die PostgreSQL Dokumentation beinhaltet eine gute Beschreibung, wann es sinnvoll ist, eigene Tablespaces zu verwenden.
-
-X <tablespace> -
Den Tablespace bestimmen, in dem die neuen Tabellenindizes angelegt werden sollen. Gilt für den Primärschlüsselindex und wenn "-l" verwendet wird, auch für den räumlichen GIST-Index.
-
-Z -
Wenn dieses Flag verwendet wird, verhindert es die Erzeugung von
ANALYZEAnweisungen. Ohne das Flag -Z (Standardverhalten) werden die AnweisungenANALYZEerzeugt.
Eine Beispielsitzung, bei der der Loader eine Eingabedatei erstellt und diese lädt, könnte folgendermaßen aussehen:
# shp2pgsql -c -D -s 4269 -i -I shaperoads.shp myschema.roadstable > roads.sql # psql -d roadsdb -f roads.sql
Eine Konvertierung und das Laden können in einem Schritt über UNIX-Pipes durchgeführt werden:
# shp2pgsql shaperoads.shp myschema.roadstable | psql -d roadsdb
4.8. Extrahieren von Geodaten
Geodaten können entweder mit SQL oder mit dem Shapefile-Dumper aus der Datenbank extrahiert werden. Im Abschnitt über SQL werden einige der Funktionen vorgestellt, die für Vergleiche und Abfragen von räumlichen Tabellen zur Verfügung stehen.
4.8.1. SQL zum Extrahieren von Daten verwenden
Die einfachste Möglichkeit, Geodaten aus der Datenbank zu extrahieren, ist die Verwendung einer SQL SELECT Abfrage, um den zu extrahierenden Datensatz zu definieren und die resultierenden Spalten in eine parsbare Textdatei zu übertragen:
db=# SELECT road_id, ST_AsText(road_geom) AS geom, road_name FROM roads;
road_id | geom | road_name
--------+-----------------------------------------+-----------
1 | LINESTRING(191232 243118,191108 243242) | Jeff Rd
2 | LINESTRING(189141 244158,189265 244817) | Geordie Rd
3 | LINESTRING(192783 228138,192612 229814) | Paul St
4 | LINESTRING(189412 252431,189631 259122) | Graeme Ave
5 | LINESTRING(190131 224148,190871 228134) | Phil Tce
6 | LINESTRING(198231 263418,198213 268322) | Dave Cres
7 | LINESTRING(218421 284121,224123 241231) | Chris Way
(6 rows)
Es kann vorkommen, dass eine Art von Einschränkung erforderlich ist, um die Anzahl der zurückgegebenen Datensätze zu verringern. Im Falle von attributbasierten Einschränkungen verwenden Sie dieselbe SQL-Syntax wie bei einer nicht räumlichen Tabelle. Bei räumlichen Einschränkungen sind die folgenden Funktionen nützlich:
-
ST_Intersects -
Diese Funktion bestimmt ob sich zwei geometrische Objekte einen gemeinsamen Raum teilen
-
= -
Überprüft, ob zwei Geoobjekte geometrisch ident sind. Zum Beispiel, ob 'POLYGON((0 0,1 1,1 0,0 0))' ident mit 'POLYGON((0 0,1 1,1 0,0 0))' ist (ist es).
Außerdem können Sie diese Operatoren in Anfragen verwenden. Beachten Sie bitte, wenn Sie eine Geometrie oder eine Box auf der SQL-Befehlszeile eingeben, dass Sie die Zeichensatzdarstellung explizit in eine Geometrie umwandeln müssen. 312 ist ein fiktives Koordinatenreferenzsystem das zu unseren Daten passt. Also, zum Beispiel:
SELECT road_id, road_name FROM roads WHERE roads_geom='SRID=312;LINESTRING(191232 243118,191108 243242)'::geometry;
Die obere Abfrage würde einen einzelnen Datensatz aus der Tabelle "ROADS_GEOM" zurückgeben, in dem die Geometrie gleich dem angegebenen Wert ist.
Überprüfung ob einige der Strassen in die Polygonfläche hineinreichen:
SELECT road_id, road_name FROM roads WHERE ST_Intersects(roads_geom, 'SRID=312;POLYGON((...))');
Die häufigsten räumlichen Abfragen werden vermutlich in einem bestimmten Ausschnitt ausgeführt. Insbesondere von Client-Software, wie Datenbrowsern und Kartendiensten, die auf diese Weise die Daten für die Darstellung eines "Kartenausschnitts" erfassen.
Der Operator "&&" kann entweder mit einer BOX3D oder mit einer Geometrie verwendet werden. Allerdings wird auch bei einer Geometrie nur das Umgebungsrechteck für den Vergleich herangezogen.
Die Abfrage zur Verwendung des "BOX3D" Objekts für einen solchen Ausschnitt sieht folgendermaßen aus:
SELECT ST_AsText(roads_geom) AS geom FROM roads WHERE roads_geom && ST_MakeEnvelope(191232, 243117,191232, 243119,312);
Achten Sie auf die Verwendung von SRID=312, welche die Projektion Einhüllenden/Enveloppe bestimmt.
4.8.2. Verwendung des Shapefile-Dumpers
Der pgsql2shp Tabellendumper verbindet sich mit der Datenbank und konvertiert eine Tabelle (möglicherweise durch eine Abfrage definiert) in eine Shape-Datei. Die grundlegende Syntax lautet:
pgsql2shp [<options >] <database > [<schema >.]<table>
pgsql2shp [<options >] <database > <query>
Optionen auf der Befehlszeile:
-
-f <filename> -
Ausgabe in eine bestimmte Datei.
-
-h <host> -
Der Datenbankserver, mit dem eine Verbindung aufgebaut werden soll.
-
-p <port> -
Der Port über den der Verbindungsaufbau mit dem Datenbank Server hergestellt werden soll.
-
-P <password> -
Das Passwort, das zum Verbindungsaufbau mit der Datenbank verwendet werden soll.
-
-u <user> -
Das Benutzername, der zum Verbindungsaufbau mit der Datenbank verwendet werden soll.
-
-g <geometry column> -
Bei Tabellen mit mehreren Geometriespalten jene Geometriespalte, die ins Shapefile geschrieben werden soll.
-
-b -
Die Verwendung eines binären Cursors macht die Berechnung schneller; funktioniert aber nur, wenn alle nicht-geometrischen Attribute in den Datentyp "text" umgewandelt werden können.
-
-r -
RAW-Modus. Das Attribut
gidwird nicht verworfen und Spaltennamen werden nicht maskiert. -
-m filename -
Bildet die Identifikatoren in Namen mit 10 Zeichen ab. Der Inhalt der Datei besteht aus Zeilen von jeweils zwei durch Leerzeichen getrennten Symbolen, jedoch ohne vor- oder nachgestellte Leerzeichen: VERYLONGSYMBOL SHORTONE ANOTHERVERYLONGSYMBOL SHORTER etc.
4.9. Räumliche Indizes
Räumliche Indizes ermöglichen die Verwendung einer räumlichen Datenbank für große Datensätze. Ohne Indizierung erfordert die Suche nach Merkmalen ein sequentielles Durchsuchen aller Datensätze in der Datenbank. Die Indizierung beschleunigt die Suche, indem die Daten in einer Struktur organisiert werden, die schnell durchlaufen werden kann, um passende Datensätze zu finden.
Die B-Baum-Index-Methode, die üblicherweise für Attributdaten verwendet wird, ist für räumliche Daten nicht sehr nützlich, da sie nur die Speicherung und Abfrage von Daten in einer einzigen Dimension unterstützt. Daten wie Geometrie (die 2 oder mehr Dimensionen haben) erfordern eine Indexmethode, die Bereichsabfragen über alle Datendimensionen unterstützt. Einer der Hauptvorteile von PostgreSQL für den Umgang mit räumlichen Daten ist, dass es mehrere Arten von Indexmethoden bietet, die gut für mehrdimensionale Daten funktionieren: GiST-, BRIN- und SP-GiST-Indizes.
-
GiST (Generalized Search Tree) Indizes unterteilen Daten in "Dinge, die auf einer Seite liegen", "Dinge, die sich überschneiden", "Dinge, die im Inneren liegen" und können für eine Vielzahl von Datentypen verwendet werden, einschließlich GIS-Daten. PostGIS verwendet einen R-Tree-Index, der auf GiST aufbaut, um räumliche Daten zu indizieren. GiST ist die am weitesten verbreitete und vielseitigste räumliche Indexmethode und bietet eine sehr gute Abfrageleistung.
-
BRIN (Block Range Index) Indizes fassen die räumliche Ausdehnung von Bereichen von Tabellendatensätzen zusammen. Die Suche erfolgt über einen Scan der Bereiche. BRIN ist nur für einige Arten von Daten geeignet (räumlich sortiert, mit seltenen oder keinen Aktualisierungen). Es ermöglicht jedoch eine wesentlich schnellere Indexerstellung und eine wesentlich geringere Indexgröße.
-
SP-GiST (Space-Partitioned Generalized Search Tree) ist eine generische Indexmethode, die partitionierte Suchbäume wie Quad-Bäume, k-d-Bäume und Radix-Bäume (Tries) unterstützt.
Räumliche Indizes speichern nur die Bounding Box von Geometrien. Räumliche Abfragen verwenden den Index als primären Filter, um schnell einen Satz von Geometrien zu ermitteln, die möglicherweise der Abfragebedingung entsprechen. Die meisten räumlichen Abfragen erfordern einen sekundären Filter, der eine räumliche Prädikatsfunktion verwendet, um eine spezifischere räumliche Bedingung zu testen. Weitere Informationen über Abfragen mit räumlichen Prädikaten finden Sie unter Section 5.2, “Räumliche Indizes verwenden”.
Siehe auch den PostGIS Workshop Abschnitt über räumliche Indizes, und das PostgreSQL Handbuch.
4.9.1. GiST-Indizes
GiST steht für "Generalized Search Tree" (verallgemeinerter Suchbaum) und ist eine generische Form der Indexierung für mehrdimensionale Daten. PostGIS verwendet einen R-Tree-Index, der auf GiST aufbaut, um räumliche Daten zu indizieren. GiST ist die am häufigsten verwendete und vielseitigste räumliche Indexmethode und bietet eine sehr gute Abfrageleistung. Andere GiST-Implementierungen werden verwendet, um die Suche in allen Arten von unregelmäßigen Datenstrukturen (Integer-Arrays, Spektraldaten usw.) zu beschleunigen, die für eine normale B-Tree-Indexierung nicht geeignet sind. Weitere Informationen finden Sie im PostgreSQL-Handbuch.
Sobald eine Geodatentabelle einige tausend Zeilen überschreitet, sollten Sie einen Index erstellen, um die räumliche Suche in den Daten zu beschleunigen (es sei denn, alle Ihre Suchvorgänge basieren auf Attributen; in diesem Fall sollten Sie einen normalen Index für die Attributfelder erstellen).
Die Syntax, mit der ein GIST-Index auf eine Geometriespalte gelegt wird, lautet:
CREATE INDEX [indexname] ON [tablename] USING GIST ( [geometryfield] );
Die obere Syntax erzeugt immer einen 2D-Index. Um einen n-dimensionalen Index für den geometrischen Datentyp zu erhalten, können Sie die folgende Syntax verwenden:
CREATE INDEX [indexname] ON [tablename] USING GIST ([geometryfield] gist_geometry_ops_nd);
Die Erstellung eines räumlichen Indizes ist eine rechenintensive Aufgabe. Während der Erstellung wird auch der Schreibzugriff auf die Tabelle blockiert. Bei produktiven Systemen empfiehlt sich daher die langsamere Option CONCURRENTLY:
CREATE INDEX CONCURRENTLY [indexname] ON [tablename] USING GIST ( [geometryfield] );
Nachdem ein Index aufgebaut wurde sollte PostgreSQL gezwungen werden die Tabellenstatistik zu sammeln, da diese zur Optmierung der Auswertungspläne verwendet wird:
VACUUM ANALYZE [table_name] [(column_name)];
4.9.2. BRIN Indizes
BRIN steht für "Block Range Index". Es handelt sich um eine allgemeine Indexmethode, die in PostgreSQL 9.5 eingeführt wurde. BRIN ist eine lossy Indexmethode, was bedeutet, dass eine sekundäre Prüfung erforderlich ist, um zu bestätigen, dass ein Datensatz mit einer bestimmten Suchbedingung übereinstimmt (was für alle bereitgestellten räumlichen Indizes der Fall ist). Sie ermöglicht eine viel schnellere Indexerstellung und eine viel geringere Indexgröße bei einer angemessenen Leseleistung. Sein Hauptzweck besteht darin, die Indizierung sehr großer Tabellen auf Spalten zu unterstützen, die eine Korrelation mit ihrer physischen Position innerhalb der Tabelle aufweisen. Zusätzlich zur räumlichen Indizierung kann BRIN die Suche auf verschiedenen Arten von Attributdatenstrukturen (Integer, Arrays usw.) beschleunigen. Weitere Informationen finden Sie im PostgreSQL-Handbuch.
Sobald eine räumliche Tabelle einige tausend Zeilen überschreitet, sollten Sie einen Index erstellen, um die räumliche Suche in den Daten zu beschleunigen. GiST-Indizes sind sehr leistungsfähig, solange ihre Größe den für die Datenbank verfügbaren Arbeitsspeicher nicht übersteigt und Sie sich die Größe des Indexspeichers und die Kosten der Indexaktualisierung beim Schreiben leisten können. Andernfalls kann für sehr große Tabellen der BRIN-Index als Alternative in Betracht gezogen werden.
Ein BRIN-Index speichert die Bounding Box, die alle in den Zeilen enthaltenen Geometrien in einem zusammenhängenden Satz von Tabellenblöcken einschließt, genannt block range. Bei der Ausführung einer Abfrage unter Verwendung des Indexes werden die Blockbereiche gescannt, um diejenigen zu finden, die den Abfragebereich überschneiden. Dies ist nur dann effizient, wenn die Daten physisch so geordnet sind, dass sich die Begrenzungsrahmen für die Blockbereiche minimal überschneiden (und sich im Idealfall gegenseitig ausschließen). Der daraus resultierende Index ist sehr klein, aber in der Regel weniger performant beim Lesen als ein GiST-Index über dieselben Daten.
Die Erstellung eines BRIN-Index ist wesentlich weniger rechenintensiv als die Erstellung eines GiST-Index. In der Regel ist ein BRIN-Index zehnmal schneller zu erstellen als ein GiST-Index für dieselben Daten. Und da ein BRIN-Index nur eine Bounding Box für jeden Bereich von Tabellenblöcken speichert, benötigt er in der Regel bis zu tausendmal weniger Plattenplatz als ein GiST-Index.
Sie können die Anzahl der Blöcke wählen, die in einem Bereich zusammengefasst werden sollen. Wenn Sie diese Zahl verringern, wird der Index größer, bietet aber wahrscheinlich eine bessere Leistung.
Damit BRIN effektiv ist, sollten die Tabellendaten in einer physischen Reihenfolge gespeichert werden, die die Überlappung der Blöcke minimiert. Es kann sein, daß die Daten bereits entsprechend sortiert sind (z.B. wenn sie aus einem anderen Datensatz geladen wurden, der bereits räumlich sortiert ist). Andernfalls kann dies durch Sortieren der Daten nach einem eindimensionalen räumlichen Schlüssel erreicht werden. Eine Möglichkeit, dies zu tun, besteht darin, eine neue Tabelle zu erstellen, die nach den Geometriewerten sortiert ist (was in neueren PostGIS-Versionen eine effiziente Hilbert-Kurvenordnung verwendet):
CREATE TABLE table_sorted AS SELECT * FROM table ORDER BY geom;
Alternativ können die Daten an Ort und Stelle sortiert werden, indem ein GeoHash als (temporärer) Index verwendet und anhand dieses Indexes eine Gruppierung vorgenommen wird:
CREATE INDEX idx_temp_geohash ON table
USING btree (ST_GeoHash( ST_Transform( geom, 4326 ), 20));
CLUSTER table USING idx_temp_geohash;
Die Syntax für die Erstellung eines BRIN-Index für eine Spalte geometry lautet:
CREATE INDEX [indexname] ON [tablename] USING BRIN ( [geome_col] );
Mit der obigen Syntax wird ein 2D-Index erstellt. Um einen 3D-dimensionalen Index zu erstellen, verwenden Sie diese Syntax:
CREATE INDEX [indexname] ON [tablename]
USING BRIN ([geome_col] brin_geometry_inclusion_ops_3d);
Sie können auch einen 4D-dimensionalen Index erhalten, indem Sie die 4D-Operatorklasse verwenden:
CREATE INDEX [indexname] ON [tablename]
USING BRIN ([geome_col] brin_geometry_inclusion_ops_4d);
Die obigen Befehle verwenden die Standardanzahl von Blöcken in einem Bereich, die 128 beträgt. Um die Anzahl der zusammenzufassenden Blöcke in einem Bereich anzugeben, verwenden Sie folgende Syntax
CREATE INDEX [indexname] ON [tablename]
USING BRIN ( [geome_col] ) WITH (pages_per_range = [number]);
Beachten Sie, dass ein BRIN-Index nur einen Indexeintrag für eine große Anzahl von Zeilen speichert. Wenn Ihre Tabelle Geometrien mit einer gemischten Anzahl von Dimensionen speichert, ist es wahrscheinlich, dass der resultierende Index eine schlechte Leistung hat. Sie können diese Leistungseinbußen vermeiden, indem Sie die Operatorklasse mit der geringsten Anzahl von Dimensionen der gespeicherten Geometrien wählen
Der Datentyp geography wird für die BRIN-Indizierung unterstützt. Die Syntax für die Erstellung eines BRIN-Index für eine Geografiespalte lautet:
CREATE INDEX [indexname] ON [tablename] USING BRIN ( [geog_col] );
Mit der obigen Syntax wird ein 2D-Index für geografische Objekte auf dem Sphäroid erstellt.
Derzeit wird nur "Einschlussunterstützung" geboten, d. h. nur die Operatoren && , ~ und @ können für die 2D-Fälle verwendet werden (sowohl für die Geometrie als auch für die Geographie ), und nur der Operator &&& für 3D-Geometrien. Derzeit gibt es keine Unterstützung für kNN-Suchen.
Ein wichtiger Unterschied zwischen BRIN und anderen Indexarten ist, daß die Datenbank den Index nicht dynamisch pflegt. Änderungen an räumlichen Daten in der Tabelle werden einfach an das Ende des Indexes angehängt. Dies führt dazu, daß die Leistung der Indexsuche mit der Zeit abnimmt. Der Index kann durch Ausführen eines VACUUM oder durch Verwendung einer speziellen Funktion brin_summarize_new_values(regclass) aktualisiert werden. Aus diesem Grund eignet sich BRIN vor allem für Daten, die nur gelesen werden oder sich nur selten ändern. Weitere Informationen finden Sie im Handbuch.
Zusammenfassung der Verwendung von BRIN für räumliche Daten:
-
Der Indexaufbau ist sehr schnell und die Indexgröße ist sehr klein.
-
Die Indexabfragezeit ist langsamer als bei GiST, kann aber immer noch sehr akzeptabel sein.
-
Erfordert, dass die Tabellendaten in einer räumlichen Reihenfolge sortiert werden.
-
Erfordert manuelle Indexpflege.
-
Am besten geeignet für sehr große Tabellen mit geringer oder gar keiner Überschneidung (z. B. Punkte), die statisch sind oder sich nur selten ändern.
-
Effektiver für Abfragen, die eine relativ große Anzahl von Datensätzen zurückgeben.
4.9.3. SP-GiST Indizes
SP-GiST steht für "Space-Partitioned Generalized Search Tree" und ist eine generische Form der Indizierung für mehrdimensionale Datentypen, die partitionierte Suchbäume wie Quad-Trees, K-D-Trees und Radix-Trees unterstützt (Tries). Das gemeinsame Merkmal dieser Datenstrukturen ist, dass sie den Suchraum wiederholt in Partitionen unterteilen, die nicht gleich groß sein müssen. Neben der räumlichen Indizierung wird SP-GiST zur Beschleunigung von Suchvorgängen bei vielen Arten von Daten verwendet, wie z. B. Telefon-Routing, IP-Routing, Teilstringsuche usw. Weitere Informationen finden Sie im PostgreSQL-Handbuch.
Wie GiST-Indizes sind auch SP-GiST-Indizes verlustbehaftet, da sie die Bounding Box speichern, die räumliche Objekte umschließt. SP-GiST-Indizes können als eine Alternative zu GiST-Indizes betrachtet werden.
Sobald eine Geodatentabelle einige tausend Zeilen überschreitet, kann es sinnvoll sein einen SP-GIST Index zu erzeugen, um die räumlichen Abfragen auf die Daten zu beschleunigen. Die Syntax zur Erstellung eines SP-GIST Index auf eine "Geometriespalte" lautet:
CREATE INDEX [indexname] ON [tablename] USING SPGIST ( [geometryfield] );
Die obere Syntax erzeugt einen 2D-Index. Ein 3-dimensionaler Index für den geometrischen Datentyp können Sie mit der 3D Operatorklasse erstellen:
CREATE INDEX [indexname] ON [tablename] USING SPGIST ([geometryfield] spgist_geometry_ops_3d);
Die Erstellung eines räumlichen Indizes ist eine rechenintensive Aufgabe. Während der Erstellung wird auch der Schreibzugriff auf die Tabelle blockiert. Bei produktiven Systemen empfiehlt sich daher die langsamere Option CONCURRENTLY:
CREATE INDEX CONCURRENTLY [indexname] ON [tablename] USING SPGIST ( [geometryfield] );
Nachdem ein Index aufgebaut wurde sollte PostgreSQL gezwungen werden die Tabellenstatistik zu sammeln, da diese zur Optmierung der Auswertungspläne verwendet wird:
VACUUM ANALYZE [table_name] [(column_name)];
Ein SP-GiST Index kann Abfragen mit folgenden Operatoren beschleunigen:
-
<<, &<, &>, >>, <<|, &<|, |&>, |>>, &&, @>, <@, and ~=, für 2-dimensionale Iindices,
-
&/&, ~==, @>>, and <<@, für 3-dimensionale Indices.
kNN Suche wird zurzeit nicht unterstützt.
4.9.4. Abstimmung der Indexverwendung
Normalerweise beschleunigen Indizes unsichtbar den Datenzugriff: Sobald ein Index erstellt ist, entscheidet der PostgreSQL-Abfrageplaner automatisch, wann er verwendet wird, um die Abfrageleistung zu verbessern. Es gibt jedoch einige Situationen, in denen der Planer nicht entscheidet, vorhandene Indizes zu verwenden, so dass Abfragen am Ende langsame sequenzielle Scans anstelle eines räumlichen Indexes verwenden.
Wenn Sie feststellen, dass Ihre räumlichen Indizes nicht verwendet werden, können Sie einige Dinge tun:
-
Prüfen Sie den Abfrageplan und stellen Sie sicher, dass Ihre Abfrage tatsächlich das berechnet, was Sie brauchen. Ein fehlerhafter JOIN, der entweder vergessen wurde oder sich auf die falsche Tabelle bezieht, kann unerwartet mehrfach Tabellendatensätze abrufen. Um den Abfrageplan zu erhalten, führen Sie ihn mit
EXPLAINvor der Abfrage aus. -
Stellen Sie sicher, dass Statistiken über die Anzahl und die Verteilungen der Werte in einer Tabelle gesammelt werden, um dem Abfrageplaner bessere Informationen für Entscheidungen über die Indexnutzung zu liefern. VACUUM ANALYZE berechnet beides.
Sie sollten Ihre Datenbanken auf jeden Fall regelmäßig leeren. Viele PostgreSQL-DBAs lassen VACUUM regelmäßig als Cron-Job außerhalb der Spitzenzeiten laufen.
-
Wenn das Vakuumieren nicht hilft, können Sie den Planer vorübergehend zwingen, die Indexinformationen zu verwenden, indem Sie den Befehl SET ENABLE_SEQSCAN TO OFF; verwenden. Auf diese Weise können Sie überprüfen, ob der Planer überhaupt in der Lage ist, einen indexbeschleunigten Abfrageplan für Ihre Abfrage zu erstellen. Sie sollten diesen Befehl nur zur Fehlersuche verwenden; im Allgemeinen weiß der Planer besser als Sie, wann Indizes verwendet werden sollten. Nachdem Sie Ihre Abfrage ausgeführt haben, vergessen Sie nicht, SET ENABLE_SEQSCAN TO ON; auszuführen, damit der Planer bei anderen Abfragen normal arbeitet.
-
Wenn SET ENABLE_SEQSCAN TO OFF; Ihre Abfrage schneller laufen lässt, ist Ihr Postgres wahrscheinlich nicht auf Ihre Hardware abgestimmt. Wenn Sie feststellen, dass der Planer die Kosten für sequentielle und Index-Scans falsch einschätzt, versuchen Sie, den Wert von
RANDOM_PAGE_COSTinpostgresql.confzu reduzieren, oder verwenden Sie SET RANDOM_PAGE_COST TO 1.1;. Der Standardwert fürRANDOM_PAGE_COSTist 4.0. Versuchen Sie, ihn auf 1,1 (für SSD) oder 2,0 (für schnelle Magnetplatten) zu setzen. Wenn Sie den Wert verringern, wird der Planer mit größerer Wahrscheinlichkeit Index-Scans verwenden. -
Wenn SET ENABLE_SEQSCAN TO OFF; Ihrer Abfrage nicht hilft, verwendet die Abfrage möglicherweise ein SQL-Konstrukt, das der Postgres-Planer noch nicht optimieren kann. Es kann möglich sein, die Abfrage so umzuschreiben, dass der Planner sie verarbeiten kann. Zum Beispiel kann eine Subquery mit einem Inline-SELECT keinen effizienten Plan erzeugen, kann aber möglicherweise mit einem LATERAL JOIN umgeschrieben werden.
Weitere Informationen finden Sie im Postgres-Handbuch im Abschnitt Query Planning.