7. 単純なSQL¶
SQL ("Structured Query Language") は、リレーショナルデータベースにおいて、問合せ、更新を行う手段です。データベースの生成の地点で、みなさんは既に SQL を見ています。思い返してみましょう:
SELECT postgis_full_version();
これはデータベースに関する問合せでした。現時点では既にデータをロードしています。SQL でデータの問合せを実行してみましょう! たとえば、
「ニューヨーク市内の全ての地区の名前を知りたい」
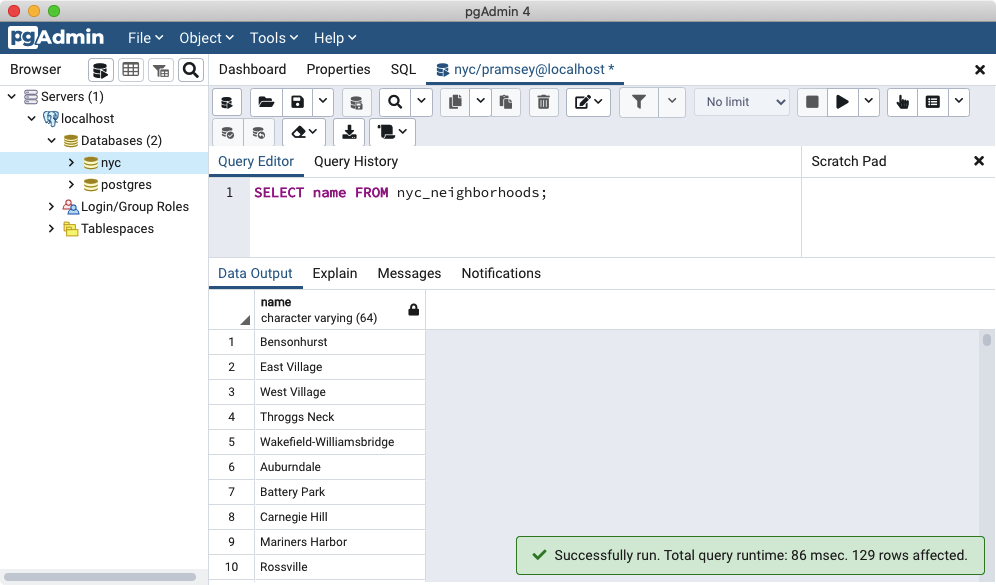
"Query Tool" ボタンをクリックして、pgAdmin の SQLクエリウィンドウを開きます。

クエリウィンドウに次のクエリを入力して
SELECT name FROM nyc_neighborhoods;
最後に Execute Query ボタン (緑の三角形) をクリックします。

クエリは数秒 (数ミリ秒) 間実行されて、129 件の結果が返ります。
しかし、ここで何が起こったのでしょう? これを理解するために、SQL の四つの「動詞」から始めましょう、
SELECT, クエリに応答して行を返しますINSERT, 新しい行をテーブルに追加しますUPDATE, テーブルの既存の行に変更を加えますDELETE,テーブルから行を削除します
空間関数を使うテーブルの問合せでは、使うのはほとんど "SELECT" だけになります。
7.1. SELECT クエリ¶
SELECTクエリは一般的に次の形式になります:
SELECT some_columns FROM some_data_source WHERE some_condition;
注釈
"SELECT" の全てのパラメータの概要については、PostgresSQL 文書 をご覧下さい。
"some_columns" は、カラム名またはカラム値の半数のいずれかです。"some_data_source" は、単一のテーブルか、二つのテーブルをキーまたは条件で結合した複合テーブルです。"some_condition" は、返される行数を制限するフィルタです。
「ブルックリンの全ての地区の名前を知りたい」
nyc_neighborhoods テーブルに話を戻します。テーブルはニューヨーク市の全ての地区を持っていますが、ブルックリン内の地区だけを求めています。
SELECT name
FROM nyc_neighborhoods
WHERE boroname = 'Brooklyn';
クエリは、さらに短く、数秒 (数ミリ秒) で終わり、23件の結果を返します。
時々、関数をクエリの結果に適用する必要があります。例を挙げます、
「ブルックリンの全ての地区の名前の文字数を知りたい」
幸運なことに、PostgreSQL には、文字列長を得る char_length(string). という関数があります。
SELECT char_length(name)
FROM nyc_neighborhoods
WHERE boroname = 'Brooklyn';
私たちはしばしば、結果の個々の行よりも、全体の統計値の方に興味を持ちます。ここで、地区ごとの名前の長さを知ることより、地区名の長さの平均値の方に興味を持っているとします。ここで使う関数は複数の行を引数に取り、単一の結果を返すもので、「集約」関数と呼ばれます。
PostgrSQL は、平均値を求める avg() や、標準偏差を求める stddev() などといった汎用的な一連の組込集約関数を持っています。
「ブルックリンの全地区の名前の文字数の平均値と標準偏差を知りたい」
SELECT avg(char_length(name)), stddev(char_length(name))
FROM nyc_neighborhoods
WHERE boroname = 'Brooklyn';
avg | stddev
---------------------+--------------------
11.7391304347826087 | 3.9105613559407395
最後の例での集約関数は、結果集合の全ての行に適用されました。もし結果集合全体をより小さなグループにして集計を実行したい場合には、どうするでしょうか。その場合には、"GROUP BY"句 を追加します。集約関数はしばしば、1以上のカラムによる結果セットのグループ化のために "GROUP BY"句 を追加しなければなりません。
「ニューヨーク市の、行政区ごとの地区の名前の文字数の平均値を知りたい」
SELECT boroname, avg(char_length(name)), stddev(char_length(name))
FROM nyc_neighborhoods
GROUP BY boroname;
出力結果に "boroname" (行政区名) カラムが含まれているので、どの統計がどの行政区に適用されるかの判断ができます。集約クエリでは、(a) グループ句のメンバーか、または (b) 集約関数かのカラムだけを出力できます。
boroname | avg | stddev
---------------+---------------------+--------------------
Brooklyn | 11.7391304347826087 | 3.9105613559407395
Manhattan | 11.8214285714285714 | 4.3123729948325257
The Bronx | 12.0416666666666667 | 3.6651017740975152
Queens | 11.6666666666666667 | 5.0057438272815975
Staten Island | 12.2916666666666667 | 5.2043390480959474
7.2. 関数リスト¶
avg(expression): 数値カラムの値の平均を返す PostgreSQL 集約関数。
char_length(string): 文字列の文字数を返すPostgreSQL 文字列関数。
avg(expression): 入力値の標準偏差を返す PostgreSQL 集約関数。
