30. ラスタ¶
PostGIS は raster という、これまでと別の空間データ型を持っています。ラスタデータはジオメトリデータと同じで 直交座標 と空間参照系を使用します。しかし、ラスタデータはベクタデータと違い、ピクセルとバンドで構成される n次元行列 として表されます。バンドは持っている行列の数を定義します。ピクセルはそれぞれが、バンドに対応する値を格納します。RGB画像のような 3バンドラスタ では、ピクセルはおのおの、赤、緑、青のバンドに対応する三つの値を持ちます。
テレビ画面で見るようなきれいな画像もラスタですが、ラスタは見ても大して楽しくないこともあります。一言で言うと、ラスタは、座標系に固定された、表現したいものを表現できる値を持つ行列です。
ラスタがデカルト空間内に存在するので、ラスタはジオメトリとの相互作用が可能です。PostGIS は、ラスタとジオメトリの両方を入力に取る関数を多数提供しています。一般的なものとしては、下の図に示す ST_Polygon, ST_Envelope, ST_ConvexHull, ST_MinConvexHull です。ラスタをジオメトリにキャストすると、出力はラスタの ST_ConvexHull です。
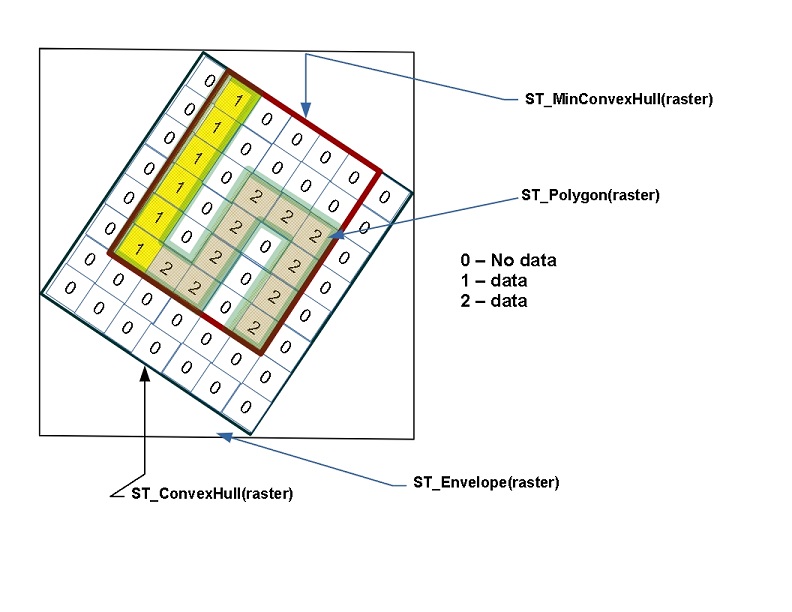
ラスタ形式は一般的に標高データ、気温データ、衛星データ、環境汚染、人口密度、環境危険の発生などを表現する主題データなどを格納するためによく使われます。意味のある座標位置を持つ数値データの格納のためにラスタを使用することができます。ラスタの制限は、特定のバンドの全てのデータについて、数値データタイプが同じでなければならないことだけです。
ラスタデータは PostGIS で何もない状態から作成できますが、PostGIS に同梱されている raster2pgsql コマンドラインツールを使って、様々なフォーマットのラスタデータをロードするのが一般的です。その前に、データベースのラスタ対応を有効にしないといけません。次のようにします:
CREATE EXTENSION postgis_raster;
30.1. ジオメトリからラスタを作る¶
ベクタデータからラスタデータ生成を最初に始め、より刺激的となるラスタソースからデータをロードするアプローチに移ります。ラスタデータが多量に存在し、しばしば様々な政府サイトから無償で入手できます。
次の通り、ST_AsRaster 関数ジオメトリをラスタに変換することから始めます。
CREATE TABLE rasters (name varchar, rast raster);
INSERT INTO rasters(name, rast)
SELECT f.word, ST_AsRaster(geom, width=>150, height=>150)
FROM (VALUES ('Hello'), ('Raster') ) AS f(word)
, ST_Letters(word) AS geom;
CREATE INDEX ix_rasters_rast
ON rasters USING gist(ST_ConvexHull(rast));
上の例で、文字から形成されるジオメトリからテーブル (ラスタ) を CREATE します。PostGIS 3.2 以上の ST_Letters を使います。ラスタはジオメトリに似ていて、空か人デックスを利用できます。ラスタに使われる空間インデックスは、ラスタの凸包ジオメトリを使った関数インデックスを使用します。
次のクエリで便利なラスタのメタデータを見ることができます。データを持つピクセルの数を数える ST_Count 関数と、ラスタの便利な背景情報の全ての種類を提供する ST_MetaData <https://postgis.net/docs/ja/RT_ST_MetaData.html>`_ 関数を使っています。
SELECT name, ST_Count(rast) As num_pixels, md.*
FROM rasters, ST_MetaData(rast) AS md;
name | num_pixels | upperleftx | upperlefty | width | height | scalex | scaley | skewx | skewy | srid | numbands
--------+------------+------------+-------------------+-------+--------+--------------------+---------------------+-------+-------+------+----------
Hello | 13926 | 0 | 77.10000000000001 | 150 | 150 | 1.226888888888889 | -0.5173333333333334 | 0 | 0 | 0 | 1
Raster | 11967 | 0 | 75.4 | 150 | 150 | 1.7226319023207244 | -0.5086666666666667 | 0 | 0 | 0 | 1
(2 rows)
注釈
ラスタ関数の二つのレベルがあります。ST_MetaData などのラスタレベルで動作する関数と、 ST_Count 関数や ST_BandMetaData 関数などのバンドレベルで動作する関数です。PostGISラスタ 関数のうちバンドレベルで動作するものは、ほとんどが一度に 1バンド で動作し、渡したいバンドの番号を 1 と仮定します。
複数バンドのラスタで、1番 以外のバンドで、NODATA値 でないピクセルのカウントを行いたい場合には、ST_Count(rast,2) のように、明示的にバンド番号を与えます。
全てのラスタのピクセル数が 150x150 になっていることに注意して下さい。これは理想的ではありません。ピクセル数を強制するために、ラスタが全方向で押しつぶされることになります。目の前のラスタの醜さを見ることができたらいいのですができません。
30.2. ラスタを raster2pgsql を使ってロードする¶
raster2pgsql は、PostGIS によく同梱されているコマンドラインツールです。Windows 上でスタックビルダの PostGIS Bundle を使っている場合には、C:\Program Files\PostgreSQL\15\bin フォルダ内に raster2pgsql.exe があります。なおフォルダ名の 15 は、実行している PostgreSQL のバージョンによって異なります。
Postgres.App を使用している場合には、他の Postgres.app CLI Tools の中に raster2pgsql があります。
Ubuntu や Debian では、次を実行して下さい
apt install postgis
これで PostGIS コマンドラインツールがインストールされます。PostgreSQL の追加バージョンもインストールされる可能性があります。pg_lsclusters コマンドを使って Degiab/Ubuntu 内のクラスタの一覧を見ることができます。pg_dropcluster コマンドを使って削除できます。
これ以後の演習では、PG Raster Workshop Dataset https://postgis.net/stuff/workshop-data/postgis_raster_workshop.zip 内にある nyc_dem.tif を使用します。ジオメトリ/ラスタの例では、以前の章でロードしたニューヨーク市データも使います。TIFF ファイルのロードの代わりに、pg_restore コマンドラインツールか、pgAdmin の Restore メニューを使って、データベース内の ZIPファイル に含まれる nyc_dem.backup を復元できます。
注釈
このラスタデータは、建物と水面を除いた、海面からの相対高度を表現する 3GB DEM の TIFFデータ である NYC DEM 1-foot Integer をもとにした低解像度版です。
raster2pgsql ツールは、ESRIシェープファイル を PostGIS ジオメトリ/ジオグラフィテーブルにロードする代わりに、GDAL が対応するラスタフォーマットをラスタテーブルにロードするところが違いますが、 shp2gpsql と似ています。shp2pgsql のように、ソースデータの空間参照系ID (SRID) を渡すことができます。shp2pgsql と違い、適切なメタデータを持っているソースデータに対しては空間参照系を推測できます。
全ての可能性のあるスイッチに関する完全な情報は raster2pgsqlオプション にあります。
他の:command:raster2pgsql が提供する特筆すべきですが、ここでは紹介しないオプションには次のものがあります:
ソースの SRID を表示する能力。代わりに raster2pgsql の推測スキルに頼ることになります。
`nodata`値 を設定する機能で、指定しない場合には raster2pgsql はファイルから推測を試みます。
データベース外ラスタのロード機能。
現在のフォルダにある全ての TIFFファイル をロードし、オーバビューを生成するには、以下を実行します。
raster2pgsql -d -e -l 2,3 -I -C -M -F -Y -t 256x256 *.tif nyc_dem | psql -d nyc
-d テーブルが既に存在している場合には削除します
上のコマンドは、トランザクションでコミットする代わりにすぐにロードを実行するために -e を使います
-C ラスタ制約を設定します。raster_columns が情報を表示するのに便利です。範囲制約を除外するために -x を使っても構いません。範囲制約はチェックに時間がかかったり、テーブル内の将来のロードを妨げ制約です。
-M ロード後に VACUUM と ANALYZE を実行して、クエリプランナの統計情報を改善します
-Y 50個のバッチで COPY を使用します。PostGIS 3.3 以上では、-Y 1000 とすると、COPY を 1000のバッチにすることができますし、もっと大きい値にすることができます。早くなる半面、使用メモリも多くなります。
-l 2,3 オーバビューテーブルを作成します。この例の場合では o_2_ncy_dem と o_3_nyc_dem が作成されます。これは、データ表示に便利です。
-I 空間インデックスを生成します
-F ファイル名を追加します。単一の TIFF ファイルしかない場合には、これはちょっと無意味です。複数のファイルをロードする場合には、各行がどのファイルから来たデータかを知るのに便利です。
-t ブロックサイズを指定します。使用サイズの最適値が分からない場合には、代わりに -t auto を使うと、raster2pgsql は TIFF ファイルと同じタイリングを使うことに注意して下さい。出力で、どのブロックサイズが選択されるかが分かります。巨大サイズになったり奇妙な値になる場合にはキャンセルして下さい。元のファイルのサイズは 300x7 ですが、理想的ではありません。
psql を使って、生成した SQL をデータベース上で実行します。そうでなくファイルにダンプしたい場合には > nyc_dem.sql を使います。
この例では、TIFF ファイルが一つしかないので、*.tif でなく、 完全なファイル名を指定できます。ファイルがカレントディレクトリに無い場合には、フォルダパスに *.tif を付けて指定することもできます。
注釈
Windows を使用していて、フォルダの参照が必要な場合には、C:/workshop/*.tif のように、ドライブレターを必ず含めて下さい。
PostGIS の専門用語で ラスタタイル と ラスタ を、いくぶん交換可能な語として聞くことがあると思います。ラスタタイルは本当は、今ロードしたニューヨーク市 DEMデータ のような大きなラスタのサブセットであるラスタカラム内の特定のラスタに対応するものです。これは、大きなラスタファイルからラスタが PostGIS にロードされる時に、このラスタを管理できるようにするために多数の行に切り刻まれるためです。それぞれの行のそれぞれのラスタは大きなラスタの一部です。それぞれのタイルは、指定したブロックサイズで示される同じサイズの領域をカバーします。悲しむべきことに、ラスタは PostgreSQL TOAST の 1GB 制限にひっかかり、TOASTからの復元処理が遅いこともあり、適切なパフォーマンスの達成や保存のために、切り刻まなければなりません。
30.3. ブラウザでのラスタ表示¶
pgAdmin と psql は、PostGISラスタ を表示する機構を持っていませんが、二つの選択肢があります。小さめのラスタの場合には、PostGIS ラスタ出力関数 に出ている ST_AsPNG や ST_AsGDALRaster といったものを含む一連の PostGIS ラスタ関数を使って、PNG 等のウェブフレンドリなラスタフォーマットで出力するのが最も簡単です。ラスタが大きくなるにつれて、表示に非常によく使われている QGIS のようなツールを使うか、他のラスタフォーマットにエクスポートする gdal_translate などの GDAL ファミリのコマンドラインツールを使うかに進むことになると思います。ただし、PostGIS ラスタは分析のために作られたものであって、見栄えのする画像を生成するためのものでないことは忘れないでください。
デフォルトでは、全ての異なるラスタタイプの出力が無効になっていることに注意して下さい。利用可能にするには、ドライバの全てまたは一部を有効にする必要があります。詳細は GDALラスタドライバの有効化 をご覧下さい。
SET postgis.gdal_enabled_drivers = 'ENABLE_ALL';
データベースサーバへの接続のたびにこれを実行したくない場合には、次のようにするとデータベースレベルで設定できます:
ALTER DATABASE nyc SET postgis.gdal_enabled_drivers = 'ENABLE_ALL';
新規のデータベースへの接続では、この設定が使われます。
下のクエリを実行して、出力をコピーしてブラウザのアドレスバーにペーストします。
SELECT 'data:image/png;base64,' ||
encode(ST_AsPNG(rast),'base64')
FROM rasters
WHERE name = 'Hello';

ここまでに作成されたラスタについては、バンド数を指定しませんし、地球との関係も定義しません。このため、ラスタが不明な空間参照系 (0) になります。
ラスタの外骨格はジオメトリと考えることができます。ジオメトリのエンベロープに入ったマトリクスです。便利な分析を行うには、空間のプロットを表現するピクセル (矩形) が欲しいので、ラスタのジオリファレンスが必要です。
ST_AsRaster は多数のオーバーロードを持ちます。前の例では、最も単純な実装を使い、 8BUI で 1 バンドのデフォルト引数を使い、NO DATA を 0 にしました。他の形式を使う必要がある場合には、名前付き引数による呼出し文法を使って、誤って思ってたものと違う形式を呼び出したり、**関数が一意でない**エラーが発生したりしないようにするべきです。
空間参照系を持つジオメトリから開始する場合には、同じ空間参照系を持つラスタで終わります。この次の例では、明るく元気のある色の単語をニューヨークに落とします。幅と高さの代わりにピクセルスケールを使用して、ラスタのピクセルサイズが空間の 1メートル × 1メートル になるようにします。
INSERT INTO rasters(name, rast)
SELECT f.word || ' in New York' ,
ST_AsRaster(geom,
scalex => 1.0, scaley => -1.0,
pixeltype => ARRAY['8BUI', '8BUI', '8BUI'],
value => CASE WHEN word = 'Hello' THEN
ARRAY[10,10,100] ELSE ARRAY[10,100,10] END,
nodataval => ARRAY[0,0,0], gridx => NULL, gridy => NULL
) AS rast
FROM (
VALUES ('Hello'), ('Raster') ) AS f(word)
, ST_SetSRID(
ST_Translate(ST_Letters(word),586467,4504725), 26918
) AS geom;
これを見ると、押しつぶされていない色付きのジオメトリが見えます。
SELECT 'data:image/png;base64,' ||
encode(ST_AsPNG(rast),'base64')
FROM rasters
WHERE name = 'Hello in New York';

Raster についても同じにします:
SELECT 'data:image/png;base64,' ||
encode(ST_AsPNG(rast),'base64')
FROM rasters
WHERE name = 'Raster in New York';

それ以上に、次を実行して
SELECT name, ST_Count(rast) As num_pixels, md.*
FROM rasters, ST_MetaData(rast) AS md;
ニューヨークのエントリのメタデータを確認します。メートル単位のニューヨーク州平面の空間参照系を持っています。また、スケールも同じです。それぞれの単位は 1x1メートル ですので、Raster という単語の幅は Hello よりも広くなります。
name | num_pixels | upperleftx | upperlefty | width | height | scalex | scaley | skewx | skewy | srid | numbands
-------------------+------------+------------+-------------------+-------+--------+--------------------+---------------------+-------+-------+-------+----------
Hello | 13926 | 0 | 77.10000000000001 | 150 | 150 | 1.226888888888889 | -0.5173333333333334 | 0 | 0 | 0 | 1
Raster | 11967 | 0 | 75.4 | 150 | 150 | 1.7226319023207244 | -0.5086666666666667 | 0 | 0 | 0 | 1
Hello in New York | 8786 | 586467 | 4504802.1 | 184 | 78 | 1 | -1 | 0 | 0 | 26918 | 3
Raster in New York | 10544 | 586467 | 4504800.4 | 258 | 76 | 1 | -1 | 0 | 0 | 26918 | 3
(4 rows)
30.4. ラスタ空間カタログテーブル¶
ジオメトリ型やジオグラフィ型と同じように、ラスタはデータベース内のすべてのラスタカラムを表示するカタログの集合を持っています。raster_columns と raster_overviews があります。
30.4.1. raster_columns¶
raster_columns は geometry_columns と geography_columns の兄弟のようなもので、同等以上のデータが提供されますが、ラスタカラム用です。
SELECT *
FROM raster_columns;
テーブルを調べると、次のことが分かります:
r_table_catalog | r_table_schema | r_table_name | r_raster_column | srid | scale_x | scale_y | blocksize_x | blocksize_y | same_alignment | regular_blocking | num_bands | pixel_types | nodata_values | out_db | extent | spatial_index
----------------+----------------+--------------+-----------------+------+---------+---------+-------------+-------------+----------------+------------------+-----------+-------------+---------------+--------+--------+---------------
nyc | public | rasters | rast | 0 | | | | | f | f | | | | | | t
nyc | public | nyc_dem | rast | 2263 | 10 | -10 | 256 | 256 | t | f | 1 | {16BUI} | {NULL} | {f} | | t
nyc | public | o_2_nyc_dem | rast | 2263 | 20 | -20 | 256 | 256 | t | f | 1 | {16BUI} | {NULL} | {f} | | t
nyc | public | o_3_nyc_dem | rast | 2263 | 30 | -30 | 256 | 256 | t | f | 1 | {16BUI} | {NULL} | {f} | | t
(4 rows)
rasters テーブルについては、ほんとどの情報が記入されていない残念な行になってしまっています。
ジオメトリとジオグラフィと違い、ラスタは型修飾子に対応していません。型修飾子はスペースが限られ過ぎていて、型識別子に入るものよりも重要なプロパティがあります。
ラスタは、そのかわりに制約に依存していて、これらの制約をビューの一部として読み取ります。
raster2pgsql を使ってロードしたテーブルの他の行を見て下さい。 -C スイッチをを使ったので、raster2pgsql は、TIFF から読み取った情報や、ユーザが渡した情報によって、SRID の制約と他の情報を付加しました。-l で作られたオーバビューテーブル o_2_nyc_dem と o_3_nyc_dem も同じです。
テーブルに制約を追加してみましょう。
SELECT AddRasterConstraints('public'::name, 'rasters'::name, 'rast'::name);
そうすると、ラスタデータが混乱して何も制約できないという通知を大量に浴びます。raster_columns をもう一度見ると、rasters の行の多くが空のままと言う、さきほどと同じ残念な話のままになっています。
制約を適用するには、テーブルの全てのラスタが少なくとも一つの規則で制約できる必要があります。
これは可能かも知れません。嘘をついて、全てのデータがニューヨーク州平面座標系にあることにしましょう。
UPDATE rasters SET rast = ST_SetSRID(rast,26918)
WHERE ST_SRID(rast) <> 26918;
SELECT AddRasterConstraints('public'::name, 'rasters'::name, 'rast'::name);
SELECT r_table_name AS t, r_raster_column AS c, srid,
blocksize_x AS bx, blocksize_y AS by, scale_x AS sx, scale_y AS sy,
ST_AsText(extent) AS e
FROM raster_columns
WHERE r_table_name = 'rasters';
あ、進捗しましたね:
t | c | srid | bx | by | sx | sy | e
----------+------+-------+-----+-----+----+----+------------------------------------------
rasters | rast | 26918 | 150 | 150 | | | POLYGON((0 -0.90000000000..
(1 row)
制限できることが多いほど、値が入ったカラムの数が多くなり、ラスタ内のタイルの全てにおいて可能な操作も増えます。全ての制約を提供したくない場合もあることに注意して下さい。
たとえば、ラスタテーブルにより多くのデータを入れ込む計画があったとします。範囲制約を設定すると、全てのラスタがその範囲内に存在する必要があるので、この制約を飛ばしたくなるでしょう。
30.4.2. raster_overviews¶
ラスタオーバビューのカラムは raster_columns メタデータカタログ内と、他のメタデータカタログである raster_overviews 内との両方にあります。オーバビューは、たいていは高ズームレベル時の表示の速度向上に使われます。精度は低いけれども生のラスタテーブルに適用するよりずっと高速に統計情報を提供して、エンベロープ解析を素早く返すためにも使われます。
オーバビューを調べるには次を実行します:
SELECT *
FROM raster_overviews;
そすると、次のような出力が得られます:
o_table_catalog | o_table_schema | o_table_name | o_raster_column | r_table_catalog | r_table_schema | r_table_name | r_raster_column | overview_factor
----------------+----------------+--------------+-----------------+-----------------+----------------+--------------+-----------------+-----------------
nyc | public | o_2_nyc_dem | rast | nyc | public | nyc_dem | rast | 2
nyc | public | o_3_nyc_dem | rast | nyc | public | nyc_dem | rast | 3
(2 rows)
raster_overviews テーブルは overview_factor と親テーブルの名前を提供しているだけです。この情報の全ては raster2pgsql のオーバビューに関する命名規則によって自分で考えられたはずです。
overview_factor で、その行の親に対する解像度が分かります。overview_factor が 2 の場合には、2x2 = 4 タイルが、ひとつの overview_2 タイルに当てはまります。同様に overview_factor が 3 の場合には、overview_3 タイルに、元のタイルの 2x2x2 = 8 タイルが押し込まれます。
30.5. 一般的なラスタ関数¶
postgis_raster エクステンションは 100超 の関数から選択できます。PostGIS ラスタ機能は PostGIS ジオメトリ対応にならってパターン化されています。ラスタとジオメトリの間の関数の、意味のある重複があります。ジオメトリ世界で等価な関数で一般的なものとしては、ST_Intersects, ST_SetSRID, ST_SRID, ST_Union, ST_Intersection, and ST_Transform があります。
これらの重複する関数に加えて、ラスタ間やラスタとジオメトリ間で重複する && 演算子があります。ジオメトリと連携して動作する関数やラスタに特化した関数なども多数用意されています。
領域の再構成として ST_Union のような関数が必要になります。動作が遅くなるため、解析に必要なピクセルが増えるほど、ラスタを解析に必要な領域でのクリッピングで、動作速度を上げるための関数 ST_Clip が必要になります。
最後に、解析対象範囲を含むラスタタイルを拡大するには ST_Intersects または && が必要です。&& 演算子の処理速度は ST_Intersects. より早いです。どちらもラスタ空間インデックスの利点を得ることができます。後のセクションでは、これらの基本関数と他のラスタ関数やジオメトリ関数とを併用しますが、そに移動する前に、これらの基本関数について説明します。
30.5.1. ST_Union によるラスタの結合¶
ラスタ用の ST_Union 関数は、ジオメトリ用 ST_Union と同じで、ラスタの集合から単一ラスタに集約します。しかしながら、ジオメトリ用と同じで、全てのラスタを結合できるわけではありませんが、ラスタ結合の規則は、ジオメトリ結合の規則よりも複雑です。ジオメトリの場合には、必要なことは、同じ空間参照系であることだけですが、ラスタはそれだけでは不十分です。
試そうとするなら次のようにします:
SELECT ST_Union(rast)
FROM rasters;
簡潔に次のエラーの罰を受けることになります:
ERROR: rt_raster_from_two_rasters: The two rasters provided do not have the same alignment SQL state: XX000 (エラー: rt_raster_from_two_rasters: 与えられた二つのラスタは同じアラインメントを持っていません SQL state: XX000)
この貴重なラスタとの結合を妨げる「同じアライメントのもの」というのは何ですか?
ラスタを結合するには、言ってみれば、ラスタを同じグリッド上にあるようにする必要があります。つまり、同じピクセルサイズ、同じ向き (スキュー)、同じ空間参照系、同じピクセル数を持たなければなりません。また、ピクセルは互いに切り込んではなりません。これは、地球上で同じピクセルグリッドを共有してはならないということです。
同じクエリだけど、慎重にニューヨーク上に置くようにしたもので試してみます。
また同じエラーが出ました。同じ空間参照系で、同じピクセルサイズなのに、それでも不十分なのです。グリッドがオフになっているためです。
左上の座標をほんの少しずらしてから再度試してみます。ピクセルサイズが整数なのでグリッド開始位置が整数なら、ピクセルは互いに切り込んでしまうことはありません。
UPDATE rasters SET rast = ST_SetUpperLeft(rast,
ST_UpperLeftX(rast)::integer,
ST_UpperLeftY(rast)::integer)
WHERE name LIKE '%New York';
SELECT ST_Union(rast ORDER BY name)
FROM rasters
WHERE name LIKE '%New York%';
ほらほら、動きましたよ。次のようなものが表示されます:

注釈
ラスタが同じアラインメントにならない理由が不明な場合には、ST_SameAlignment が使えます。2個のラスタまたはラスタの集合を比較して、同じアラインメントを持つかどうかを教えてくれます。通知が有効なら、NOTICE で、問題のラスタの何がおかしいかを教えてくれます。ST_NotSameAlignmentReason は、NOTICE の代わりとして、理由を出力してくれます。ただし、一度に2個のラスタでしか動作しません。
ST_Union(raster) ラスタ関数が ST_Union(geometry) ジオメトリ関数と大きく異なる点の一つとして、uniontype という引数が使用できることです。この引数は、指定していない場合のデフォルトでは LAST と設定されていて、ラスタのピクセル値がオーバラップする時は **最後の**ラスタピクセルを使います。一般的な規則として、NODATA になっているバンドのピクセルは無視されます。
PostgreSQL のほとんどの集約関数と同じで、前の例で行ったように、関数呼び出しの一部として :command:'ORDER BY'句 を配置できます。並び順を指定すると、どのラスターを優先するかを制御できます。そのため、前の例では Raster がアルファベット順で最後であるため、Raster が Hello より優先されました。
注意して下さい。並び順を入れ替えると:
SELECT ST_Union(rast ORDER BY name DESC)
FROM rasters
WHERE name LIKE '%New York%';

Hello が Raster より優先されます。"Hello" が最後にオーバレイされるためです。
FIRST 結合タイプは LAST の逆です。
ただし、LAST は正しい操作とは限らないことがあります。ラスタが二つの異なる機材から二つの異なる観測を表現したと考えます。デバイスは同じものを計測して、パスが交差する時、どちらが正しいかが分からないので、代わりに結果の MEAN (平均値) を取りたくなります。次のようにします:
SELECT ST_Union(rast, 'MEAN')
FROM rasters
WHERE name LIKE '%New York%';
ほらほら、動きましたよ。次のようなものが表示されます:

どちらを優先するかを決めずに、二つを混ぜ合わせています。MEAN 結合タイプの場合には、結果が重なり合うピクセル値の平均値を取るため、並び順を決定する意味がありません。
ジオメトリについては、ジオメトリはベクタなので、その地点にあるかないかの他に値がありません。このため、二つのベクタがインタセクトする時に、これらのベクタがどう結合するかに関して、あいまいな点はありません。
ラスタ版の ST_Union の隠していた機能として、全てのバンドを返すべきか、いくつかのバンドを返すべきかのアイデアです。どのバンドを結合するかを指定しない場合には、 ST_Union は同じバンド番号同士を結合して、LAST 結合戦略を採用します。複数のバンドがある場合には、これはやりたいことと違うようになるかもしれません。もしかしたら、結合したいというのが、2番目のバンドだけかもしれません。この場合には、緑バンドにピクセル数が必要です。
SELECT ST_BandPixelType(ST_Union(rast, 2, 'COUNT'))
FROM rasters
WHERE name LIKE '%New York%';
st_bandpixeltype
------------------
32BUI
(1 row)
COUNT 結合タイプの場合には、値の入っているピクセルをカウントして、その値を返します。結果は常に 32BUI です。SQL で COUNT を実行する時と同じです。結果は常に bigint型 で、大きな数のカウントに対応できます。
その他の場合には、バンドのピクセルタイプは変更されず、値がタイプの境界を超えると、最大値または丸められた値になります。なぜ、ある場所でインタセクトするピクセル数を数えたいのでしょう。たとえば、警察小隊と逮捕事件とを表現するラスタがあるとします。ピクセルごとの値は、異なる逮捕理由を表現している可能性があります。しかし、今は地域ごとの逮捕の統計を作成しているところなので逮捕件数のみに注目しています。
もしくは、全てのバンドをやりたいけど、他の戦略が欲しい場合もあるかも知れません。
SELECT ST_Union(rast, ARRAY[(1, 'MAX'),
(2, 'MEAN'),
(3, 'RANGE')]::unionarg[])
FROM rasters
WHERE name LIKE '%New York%';
ST_Union 関数の unionarg[] の形式を使ってもバンドの順序変更が可能です。
30.5.2. ラスタを ST_Intersects の助を得てクリッピングする¶
ST_Clip 関数は、PostGISラスタ で最も幅広く使われる関数の一つです。主な理由としては、調査や操作が必要なピクセルが増えると、処理速度が落ちるためです。ST_Clip はラスタを必要な領域にクリップして、操作をその領域のみに分離できます。
この関数は、ジオメトリの能力を利用して、ラスタ分析を助けるという点においても特徴的です。ピクセル数を減らすために ST_Union は、まずラスタごとに必要な領域にクリッピングするよう操作します。
SELECT ST_Union( ST_Clip(r.rast, g.geom) )
FROM rasters AS r
INNER JOIN
ST_Buffer(ST_Point(586598, 4504816, 26918), 100 ) AS g(geom)
ON ST_Intersects(r.rast, g.geom)
WHERE r.name LIKE '%New York%';
この例では、連携して動作するいくつかの関数を紹介しています。使われている ST_Intersects 関数は postgis_raster でパッケージされている関数で、二つのラスタをインタセクトを見るか、一つのラストと一つのジオメトリとのインタセクトを見ることができます。ジオメトリ版 ST_Intersects と同じで、ラスタ版 ST_Intersects は、ラスタテーブルやジオメトリテーブルにある空間インデックスの利点を利用できます。
注釈
デフォルトでは ST_Clip は、重心がジオメトリとインタセクトしないピクセルを除外します。これは、大きなピクセルではイライラすることになりますし、そうでなくて、重心に限らずどの部分であってもジオメトリに接触するピクセルを使える方が好まれるかも知れません。PostGIS 3.5 で touched 引数が導入されました。ST_Clip(r.rast, g.geom) を ST_Clip(r.rast, g.geom, touched => true) に置き換えてみましょう。じゃじゃーん、どのようにでもジオメトリとインタセクトするピクセルが使われます。
30.6. ラスタのジオメトリへの変換¶
ラスタはジオメトリに簡単に変換できます。
30.6.1. ST_Polygonのよるラスタのポリゴン¶
前の例から始めます。ただし、<https://postgis.net/docs/ja/RT_ST_Polygon.html>`_ 関数を使ってポリゴンに変換します。
SELECT ST_Polygon(ST_Union( ST_Clip(r.rast, g.geom) ))
FROM rasters AS r
INNER JOIN
ST_Buffer(ST_Point(586598, 4504816, 26918), 100 ) AS g(geom)
ON ST_Intersects(r.rast, g.geom)
WHERE r.name LIKE '%New York%';
ここで pgAdmin のジオメトリビューアをクリックすると、何の特殊な操作もなく、これを見ることができます。素晴らしいですね。
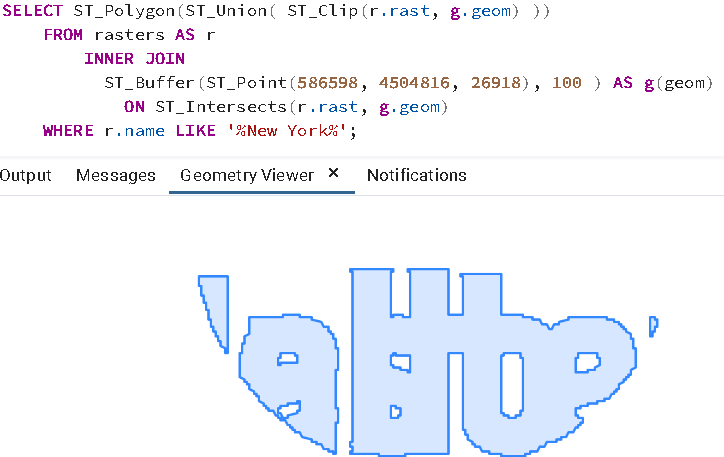
ST_Polygon は、値を持つ (NODATA値になっていない) ピクセルの全てを考慮に入れて、ジオメトリに変換します。他の多くの関数のように、ST_Polygon は 1バンド だけを対象にします。バンドが指定されていない場合には、最初のバンドだけを対象にします。
30.6.2. ST_PixelAsPolygons によるラスタのピクセルの四角形¶
もう一つの良く使われる関数は ST_PixelAsPolygons です。クリッピングを施さないままの大きなラスタに対して ST_PixelAsPolygons をあまり使うべきではありません。ピクセルごとの行が数百万行できてしまうためです。
ST_PixelAsPolygons は geom, x, y からなるテーブルを返します。ここで、x がラスタのカラム番号、y が行番号です。
ST_PixelAsPolygons は、他の一度に 1バンド で動作するラスタ関数と似ていて、バンドが指定されていない場合には、1番バンド で動作します。デフォルトでは値を持つピクセルだけが返されます。
SELECT gv.*
FROM rasters AS r
CROSS JOIN LATERAL ST_PixelAsPolygons(rast) AS gv
WHERE r.name LIKE '%New York%'
LIMIT 10;
出力:
また、ジオメトリビューアを使って調べると、次のようになります:
バンドの全てのピクセルが必要な場合には、次のようなことを行う必要があります。この例は前のものと違うことに注意して下さい。
1. Setting exclude_nodata_value to make sure all pixels are returned so that our sets of calls return the same number of rows. The rows out of the function will be naturally in the same order.
2. Using the PostgreSQL ROWS FROM constructor , and aliasing each set of columns from our function output with names. So for example the band 1 columns (geom, val, x, y) are renamed to g1, v1, x1, x2
SELECT pp.g1, pp.v1, pp.v2, pp.v3
FROM rasters AS r
CROSS JOIN LATERAL
ROWS FROM (
ST_PixelAsPolygons(rast, 1, exclude_nodata_value => false ),
ST_PixelAsPolygons(rast, 2, exclude_nodata_value => false),
ST_PixelAsPolygons(rast, 3, exclude_nodata_value => false )
) AS pp(g1, v1, x1, y1,
g2, v2, x2, y2,
g3, v3, x3, y3 )
WHERE r.name LIKE '%New York%'
AND ( pp.v1 = 0 OR pp.v2 > 0 OR pp.v3 > 0) ;
注釈
これらの例では、何をすべきか明示するため CROSS JOIN LATERAL を使っています。これらは返り値を返す全ての関数ですから、 CROSS JOIN LATERAL を "," の短縮形に置き換えられます。次の一群の例では "," を使います
30.6.3. ST_DumpAsPolygons でポリゴンをダンプする¶
ラスタは追加で geomval と呼ばれる複合型の導入もしています。geomval をジオメトリとラスタの子孫と考えて下さい。この型は、ジオメトリを含み、ピクセル値を含みます。
ラスタ関数には geomval を返すものが複数あります。
一般的に使用される geomval を返す関数に ST_DumpAsPolygons があります。同じ値を持つ連続したピクセルの集合をポリゴンとして返します。また、デフォルトでは、オーバライドしない限り、バンド 1 をチェックするだけで、NODATA 値を排除しません。この例では、バンド 2 からのポリゴンだけを選んでいます。値へのフィルタの適用も可能です。ほとんどのユーズケースでは、ST_DumpAsPolygons の方が、ST_PixelAsPolygons よりも良い選択肢となります。返される行がはるかに少なくなるからです。
これは "Raster" という文字に対応するポリゴンを 6行 出力するものです。
SELECT gv.geom , gv.val
FROM rasters AS r,
ST_DumpAsPolygons(rast, 2) AS gv
WHERE r.name LIKE '%New York%'
AND gv.val = 100;
この関数は、ポリゴンを形成する同じ値を持つ連続したピクセル集合を探すので、単一ジオメトリを返さないことに注意して下さい。全ての値が同じであっても、連続しているわけではありません。

値でグループ化を行って結合するのが、より複雑なジオメトリを減らす一般的なアプローチです。
SELECT ST_Union(gv.geom) AS geom , gv.val
FROM rasters AS r,
ST_DumpAsPolygons(rast, 2) AS gv
WHERE r.name LIKE '%New York%'
GROUP BY gv.val;
これで "Raster" と "Hello" の単語に対応する 2行 が返されます。
30.7. 統計¶
ラスタに関する理解に最も重要なものは、ラスタは配列にデータを格納する統計ツールであることで、画面上で見栄えを良くすることができるのは、たまたまです。
統計関数の一覧は、ラスタバンド統計情報と解析 にあります。
30.7.1. ST_SummaryStatsAgg と ST_SummaryStats¶
集合またはラスタの全ての統計処理が必要な場合には ST_SummaryStatsAgg に手を伸ばすことになります。
このクエリは約 10 秒かかり、テーブル全体の要約を表示します:
SELECT (ST_SummaryStatsAgg(rast, 1, true, 1)).* AS sa
FROM o_3_nyc_dem;
出力:
count | sum | mean | stddev | min | max
-----------+------------+------------------+------------------+-----+-----
246794100 | 4555256024 | 18.4577184948911 | 39.4416860598687 | 0 | 411
(1 row)
ここから、多数のピクセルがあり、最大標高が 411フィート であることが分かります。
オーバビューを構築して、最大値、最小値、平均値の荒い見積もりが必要な場合には、オーバビューの一つを使用します。次のクエリは、前の結果と同じような最小値、最大値、平均値を荒く見積もりますが、10秒かかった計算を1秒で済みます。
SELECT (ST_SummaryStatsAgg(rast, 1, true, 1)).* AS sa
FROM o_3_nyc_dem ;
この少しの情報から、さらなる質問が可能となります。
30.7.2. ST_Histogram¶
テーブル全体ではなく特定の領域の統計が必要となるのが一般的です。この場合には、古くからの友人である ST_Intersects と ST_Clip とを併用することになります。集約関数の形式を持たないラスタ統計関数も必要になる場合には、ST_Union も仲間に入ってもらう必要があるでしょう。
この次の例では、別の統計関数の ST_Histogram <https://postgis.net/docs/ja/RT_ST_Histogram.html>`_ を使います。これは、集約関数の形式を持っていなくて、特定の形式では集合を返します。前の例で必要とした領域と同じ領域を使いますが、ジオメトリ版 ST_Transform でニューヨーク州平面メートルのジオメトリをニューヨーク州平面フィートのラスタに変換する必要もあります。ラスタでなくジオメトリを投影変換する方が、ほぼ常に変換性能がよくなり、ジオメトリが一つだけの場合には、間違いなく性能がよくなります。
SELECT (ST_Quantile( ST_Union( ST_Clip(r.rast, g.geom) ), ARRAY[0.25,0.50,0.75, 1.0] )).*
FROM nyc_dem AS r
INNER JOIN
ST_Transform(
ST_Buffer(ST_Point(586598, 4504816, 26918), 100 ),
2263) AS g(geom)
ON ST_Intersects(r.rast, g.geom);
上のクエリは60ミリ秒未満で終了し、次の出力を得ます。
quantile | value
----------+-------
0.25 | 52
0.5 | 57
0.75 | 68
1 | 78
(4 rows)
30.8. 派生ラスタの生成¶
PostGIS ラスタには多数のラスタ編集関数が梱包されています。これらの関数は編集にも派生ラスタデータセットの生成にも使えます。ラスタエディタ と ラスタ管理 とのリストにあります。
30.8.1. ST_Transform によるラスタの座標変換¶
使用しているデータのほとんどはニューヨーク州平面メートル (SRID: 26918) ですが、DEM ラスタデータセットはニューヨーク州平面フィート (SRID: 2263) です。面倒が最も少ないワークフローとして、中核データセットが同じ空間参照系上にあることが必要です。
ラスタ版 ST_Transform はこの作業に最も適した関数です。
ニューヨーク州平面メートルでの新しいニューヨーク市 DEM データセットを生成するために、次の操作を行います:
CREATE TABLE nyc_dem_26918 AS
WITH ref AS (SELECT ST_Transform(rast,26918) AS rast
FROM nyc_dem LIMIT 1)
SELECT r.rid, ST_Transform(r.rast, ref.rast) AS rast, r.filename
FROM nyc_dem AS r, ref;
筆者のシステムでは 約1.5分 かかりました。より大きなデータセットでは、より長い時間がかかります。
前述の例ではラスタ版 ST_Transform の二つの形式を使いました。一つ目は、全てのタイルが同じアラインメントを持つことを保証するために、他のラスタタイルを変換するために使用される参照ラスタを得ました。二つ目の ST_Transform は、SRID と全てのピクセルの解像度とブロックサイズが参照ラスタから得るので、入力 SRID を引数に取らないことに注意して下さい。 ST_Transform(rast, srid) の形式を使った場合には、全てのラスタが異なるアラインメントで現れ、ST_Union のような操作を適用できなくなる可能があります。
前述の ST_Transform のアプローチの唯一の問題は、投影変換を実行する時に、変換されたものはしばしば他のタイル上に存在することになります。上の出力をラスタの凸包の出力で詳細に見ると、次の例では、境界まわりでオーバラップができて、イライラします。
SELECT rast::geometry
FROM nyc_dem_26918
ORDER BY rid
LIMIT 100;
次に pgAdmin で見たものを示します:

30.8.2. ST_MakeEmptyCoverage を使ってタイルラスタを作成する¶
少し遅くなりますが、より良いアプローチは、 'ST_MakeEmptyCoverage <https://postgis.net/docs/ja/RT_ST_MakeEmptyCoverage.html>'_を使用して独自のカバレッジタイル構造を最初から定義し、新しいタイルごとに交差するタイルを見つけ、これらを ST_Union してから 'ST_Transform(ref, ST_Union...)' を使用して各タイルを作成します。
このため、以前に学習したかなりの数の関数を使用します。
DROP TABLE IF EXISTS nyc_dem_26918;
CREATE TABLE nyc_dem_26918 AS
SELECT ROW_NUMBER() OVER(ORDER BY t.rast::geometry) AS rid,
ST_Union(ST_Clip( ST_Transform( r.rast, t.rast, 'Bilinear' ), t.rast::geometry ), 'MAX') AS rast
FROM (SELECT ST_Transform(
ST_SetSRID(ST_Extent(rast::geometry),2263)
, 26918) AS geom
FROM nyc_dem
) AS g, ST_MakeEmptyCoverage(tilewidth => 256, tileheight => 256,
width => (ST_XMax(g.geom) - ST_XMin(g.geom))::integer,
height => (ST_YMax(g.geom) - ST_YMin(g.geom))::integer,
upperleftx => ST_XMin(g.geom),
upperlefty => ST_YMax(g.geom),
scalex => 3.048,
scaley => -3.048,
skewx => 0., skewy => 0., srid => 26918) AS t(rast)
INNER JOIN nyc_dem AS r
ON ST_Transform(t.rast::geometry, 2263) && r.rast
GROUP BY t.rast;
前のと同じ演習を繰り返します:
SELECT rast::geometry
FROM nyc_dem_26918
ORDER BY rid
LIMIT 100;
ここで pgAdmin で見るとオーバラップがなくなりました:

筆者のシステムでは実行時間は 10分 未満ですみ、3879 行を返しました。テーブルの生成の後、通常の空間インデックス、主キー、制約を追加する作業を行うことになります。次のようにします:
ALTER TABLE nyc_dem_26918
ADD CONSTRAINT pk_nyc_dem_26918 PRIMARY KEY(rid);
CREATE INDEX ix_nyc_dem_26918_st_convexhull_gist
ON nyc_dem_26918 USING gist( ST_ConvexHull(rast) );
SELECT AddRasterConstraints('nyc_dem_26918'::name, 'rast'::name);
ANALYZE nyc_dem_26918;
このデータセットでは 2分 以内で済みます。
30.8.3. ST_CreateOverview でオーバビューテーブルを作る¶
元のデータセットと同じで、いくつかの処理の効率を良くするのにオーバビューテーブルがあると便利です。ST_CreateOverview はこの目的に適した関数です。raster2pgsql のロード中にオーバビューを生成しなかった場合や、より多くのオーバビューが必要になった場合のオーバビュー生成にも ST_CreateOverview を使うことができます。
このコードを使って、元のデータに対して行ったように、レベル 2 とレベル 3 のオーバビューを作ります。
SELECT ST_CreateOverview('nyc_dem_26918'::regclass, 'rast', 2);
SELECT ST_CreateOverview('nyc_dem_26918'::regclass, 'rast', 3);
この処理は残念なことに時間がかかります。行が増えるほど長時間になるので辛抱して下さい。このデータセットで、オーバビュー係数が 2 で 約3-5分、3 で 1分 かかりました。
ST_CreateOverView 関数も必要な制限も追加するので、raster_columns と raster_overviews とのカタログ内に完全な詳細情報が付いたカラムが出現します。インデックスの追加は行わず、rid カラムも追加しません。rid カラムは、編集のために主キーが必要となるまでは、おそらく不要です。インデックスは多分必要になります。インデックスは次のようにして生成します:
CREATE INDEX ix_o_2_nyc_dem_26918_st_convexhull_gist
ON o_2_nyc_dem_26918 USING gist( ST_ConvexHull(rast) );
CREATE INDEX ix_o_3_nyc_dem_26918_st_convexhull_gist
ON o_3_nyc_dem_26918 USING gist( ST_ConvexHull(rast) );
注釈
ST_CreateOverview には、サンプリング法を指定する任意引数があります。指定しない場合には、デフォルトで使われ、一般的に計算が最速ですが、理想的ではないことがある 最近傍 (NearestNeighbor) を使います。なお、リサンプリング法は本稿の範囲外です。
30.9. ラスタとジオメトリとのインタセクトした領域¶
ラスタとジオメトリのインタセクトした領域を計算するのに一般的に使われる二つの関数があります。ラスタとジオメトリのインタセクトした領域をラスタで返す ST_Clip は既に見ていますが、もう一つあります。ポイントデータについては、最も一般的に使われるのが ST_Value で、次に、ラスタを返したり geomval 集合を返したりと複数のオーバロードを持つ ST_Intersection があります。
30.9.1. あるポイントジオメトリのピクセル値¶
いくつかの特別なポイントジオメトリにインタセクトする場所に基づいて、ラスタから値を返す必要がある場合には、ST_Value を使うか、相対的に最近傍となる値を得る ST_NearestValue を使います。
SELECT g.geom, ST_Value(r.rast, g.geom) AS elev
FROM nyc_dem_26918 AS r
INNER JOIN
(SELECT id, geom
FROM nyc_homicides
WHERE weapon = 'gun') AS g
ON r.rast && g.geom;
この例では、2444行 を返すのに 1秒 かかりました。&& の代わりに ST_Intersects を使った場合には、3秒 かかりました。ST_Intersects が遅いのは、ピクセルごとのチェックで追加の再チェックを行うためです。全てのポイントがラスタ集合のデータで表現され、ラスタがカバレッジ (オーバラップしないラスタタイルの連続的な集合) を表現することを期待する場合には、&& が一般的に速くなる選択肢です。
ラスタデータが高密度でないか、ラスタがオーバラップしている (異なる観測結果を同時に表現している) か、スキューしている (軸に沿っていない) かのいずれかの場合には、ST_Intersects に誤検出を除かせるのは、利点があります。
30.9.2. ST_Intersection ラスタスタイル¶
ST_Intersection を使って、二つのジオメトリのインタセクトした領域を計算できるのと同じように、ラスタ版 ST_Intersection を使って、二つのラスタのインタセクトした領域を計算することができます。
このケダモノから得られるのは、二つの異なる種類のものです:
ジオメトリとラスタとのインタセクトでは、geomval 結果の集合を得ます。一つの場合もありますが、ほとんどの場合が複数です。
二つのラスタのインタセクトで、単一の raster が戻ります。
ラスタのインタセクトとジオメトリのインタセクトの両方で絶対的なルールとして、両方とも同じ空間参照系を持たなければならない、というものがあります。ラスタ対ラスタでは、そのうえ、同じアラインメントを持つ必要もあります。
みなさんが興味を持つかもしれない質問に答える例があります。標高データを 5個 の区分に分けると、どの標高範囲が、銃による死者数が最多でしょうか? 前の統計の要約から、ニューヨーク市の標高データセットの最低値が 0 で最高値が 411 というのを知っているので、width_bucket 関数の呼出しのための最小値と最大値に使うことができます。
SELECT ST_Transform(ST_Union(gv.geom),4326) AS geom ,
MIN(gv.val) AS min_elev, MAX(gv.val) AS max_elev,
count(g.id) AS count_guns
FROM nyc_dem_26918 AS r
INNER JOIN nyc_homicides AS g
ON ST_Intersects(r.rast, g.geom)
CROSS JOIN
ST_Intersection( g.geom,
ST_Clip(r.rast,ST_Expand(g.geom, 4) )
) AS gv
WHERE g.weapon = 'gun'
GROUP BY width_bucket(gv.val, 0, 411, 5)
ORDER BY width_bucket(gv.val, 0, 411, 5);
殺人事件と標高との間に重要な相関があるでしょうか? おそらくありません。
ラスタ / ラスタ のインタセクト領域を見てみましょう:
SELECT ST_Intersection(r1.rast, 1, r2.rast, 1, 'BAND1')
FROM nyc_dem_26918 AS r1
INNER JOIN
rasters AS r2 ON ST_Intersects(r1.rast,1, r2.rast, 1);
得られたのは NULL を含む二つの行です。PostgreSQL に NOTICE を設定すると、次のようになります:
NOTICE: The two rasters provided do not have the same alignment. Returning NULL (二つの与えられたラスタは同じアラインメントではありません。NULLを返します)
これを修正するために、ST_Resample を使って、一方のラスタをもう一方のラスタに揃えることができます。
SELECT ST_Intersection(r1.rast, 1,
ST_Resample( r2.rast, r1.rast ), 1,
'BAND1')
FROM nyc_dem_26918 AS r1
INNER JOIN
rasters AS r2 ON ST_Intersects(r1.rast,1, r2.rast, 1);
これを一つの統計レコードにまとめましょう
SELECT (
ST_SummaryStatsAgg(
ST_Intersection(r1.rast, 1,
ST_Resample( r2.rast, r1.rast ), 1, 'BAND1'),
1, true)
).*
FROM nyc_dem_26918 AS r1
INNER JOIN
rasters AS r2 ON ST_Intersects(r1.rast,1, r2.rast, 1);
出力は次の通りです:
count | sum | mean | stddev | min | max
-------+-------+-----------------+------------------+-----+-----
2075 | 99536 | 47.969156626506 | 9.57974836865737 | 33 | 62
(1 row)
30.10. 地図代数関数¶
地図代数は、ピクセル値に対して計算を行うことができるという考えです。前に説明した ST_Union 関数と ST_Intersection 関数は、地図代数の特に高速なケースです。ご自身のすごい数学の定義が可能になりますが能率が犠牲になる ST_MapAlgebra 関数ファミリがあります。
一般に ST_MapAlgebra に飛びつきがちですが、これは、名前の聞こえが良くて、洗練されているように感じるからなのでしょう。「地図代数関数を使ってるよ」と言いたくない人はいないでしょう。筆者のアドバイスとしては、ショットガンを引き抜く前に、他の関数も調査して下さい。あなたの人生がよりシンプルになり、あなたの能率が 100倍 良くなりますし、あなたのコードが短くなります。
ST_MapAlgebra を紹介する前に、地図代数 (Map Algebra) 関数ファミリに該当して、一般的に ST_MapAlgebra より能率的な他の関数を調べます。
30.10.1. ST_Reclass を使ったラスタの再分類¶
見落とされがちな地図代数関数に ST_Reclass があります。この関数は、物陰に隠れて、その秘めた能力と速度を見出してくれる人を待っています。
ST_Reclass は何をするのでしょう? 名前が示すように、最小範囲の計算に基づいてピクセル値を再分類します。
ニューヨーク市のデモをもう一度見てみましょう。おそらく、標高が 1) 低い、2) 中間、3) 高い、4) 非常に高い、に分類することだけに気を配ることになります。411種 の値までは不要で、4種 で充分です。そんなわけで再分類をやってみましょう。
分類方式は 再分類式 で制御します。
WITH r AS ( SELECT ST_Union(newrast) As rast
FROM nyc_dem_26918 AS r
INNER JOIN ST_Buffer(ST_Point(586598, 4504816, 26918), 1000 ) AS g(geom)
ON ST_Intersects( r.rast, g.geom )
CROSS JOIN ST_Reclass( ST_Clip(r.rast,g.geom), 1,
'[0-10):1, [10-50):2, [50-100):3,[100-:4','4BUI',0) AS newrast
)
SELECT SUM(ST_Area(gv.geom)::numeric(10,2)) AS area, gv.val
FROM r, ST_DumpAsPolygons(rast) AS gv
GROUP BY gv.val
ORDER BY gv.val;
出力は次のようになります:
area | val
------------+-----
6754.04 | 1
1753117.51 | 2
1355232.37 | 3
1848.75 | 4
(4 rows)
これが望ましい分類方式であるなら、ST_Reclass を使って各タイルを再計算して、新しいテーブルを作ることができることになります。
30.10.2. ST_ColorMap でラスタに色を付ける¶
ST_ColorMap 関数は、ピクセル値を再分類する地図代数関数のひとつです。ただし、この関数ではバンドが生成されます。DEM のような単一バンドのラスタを視覚的に表現できる 3バンド か 4バンド のラスタに変換します。
カラーマップの作成に手間を掛けたくない場合には、次のように組込カラーマップを使うことができます。
SELECT ST_ColorMap( ST_Union(newrast), 'bluered') As rast
FROM nyc_dem_26918 AS r
INNER JOIN
ST_Buffer(
ST_Point(586598, 4504816, 26918), 1000
) AS g(geom)
ON ST_Intersects( r.rast, g.geom)
CROSS JOIN ST_Clip(rast, g.geom) AS newrast;
次のようになります:
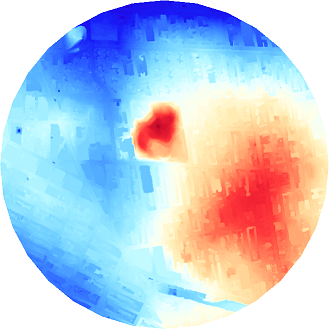
色が青いほど標高が低く、色が赤いほど標高が高くなっています。
