5. 加载空间数据¶
PostGIS 受到各种库和应用程序的支持,提供了许多加载数据的选项。
我们首先将从数据库备份文件中加载我们的工作数据,然后使用常见工具审查加载不同GIS数据格式的标准方法。
5.1. 加载备份文件¶
在 PgAdmin 浏览器中,右键单击 nyc 数据库图标,然后选择 还原... 选项。
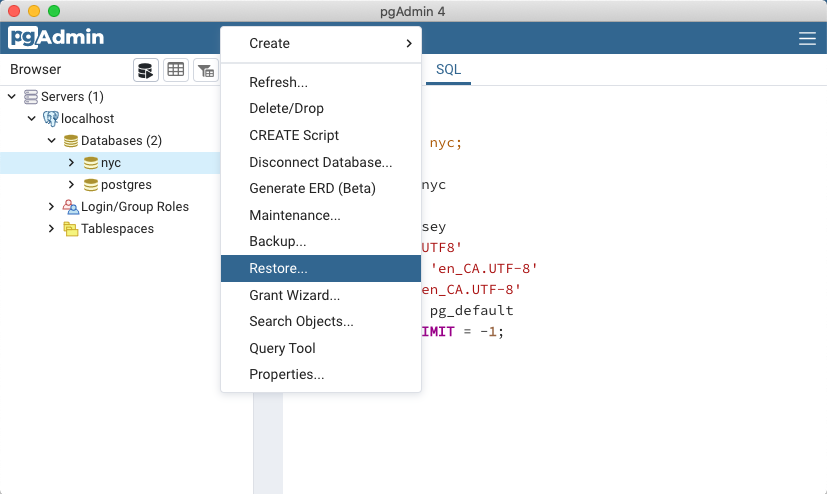
Browse to the location of your workshop data data directory (available in the workshop data bundle), and select the
nyc_data.backupfile.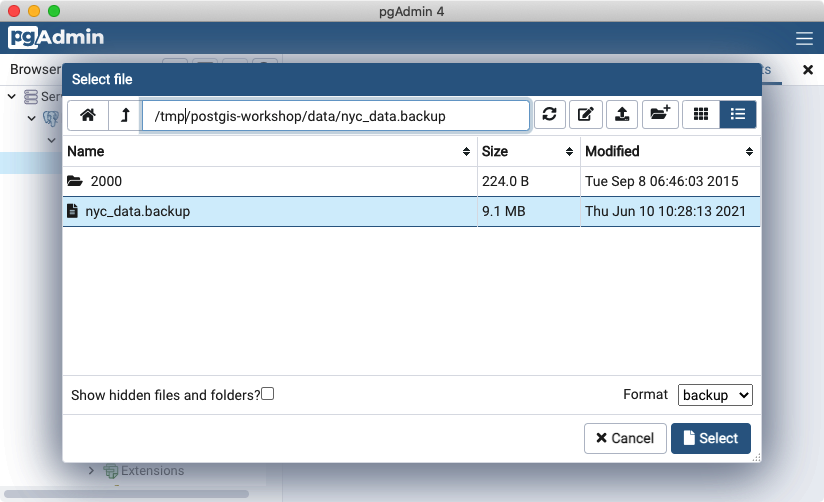
点击**还原选项**标签,滚动到**不保存**部分,将**所有者**切换到**是**。
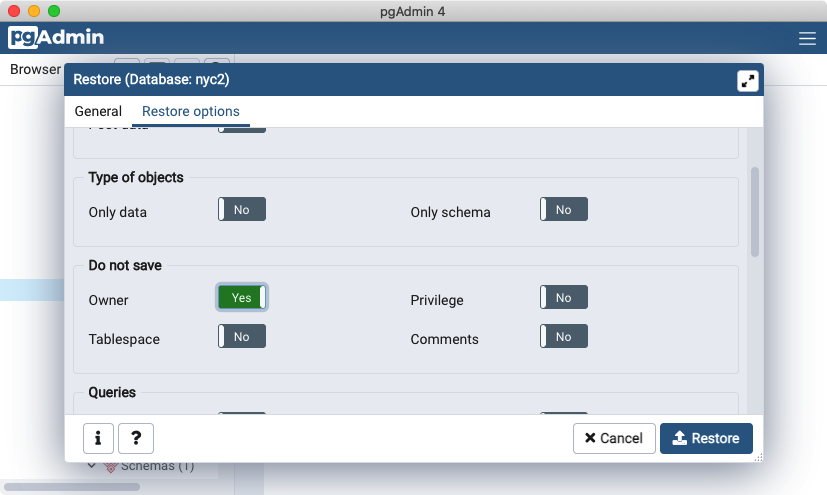
点击**还原**按钮。数据库还原应该会在没有错误的情况下完成。
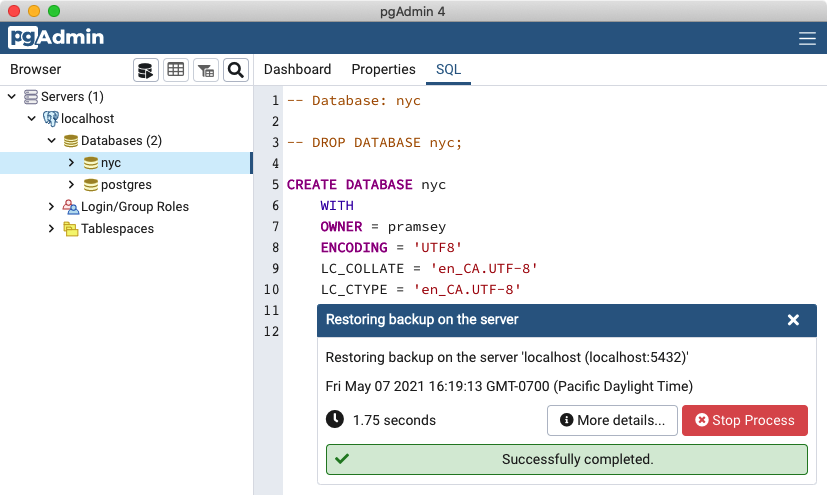
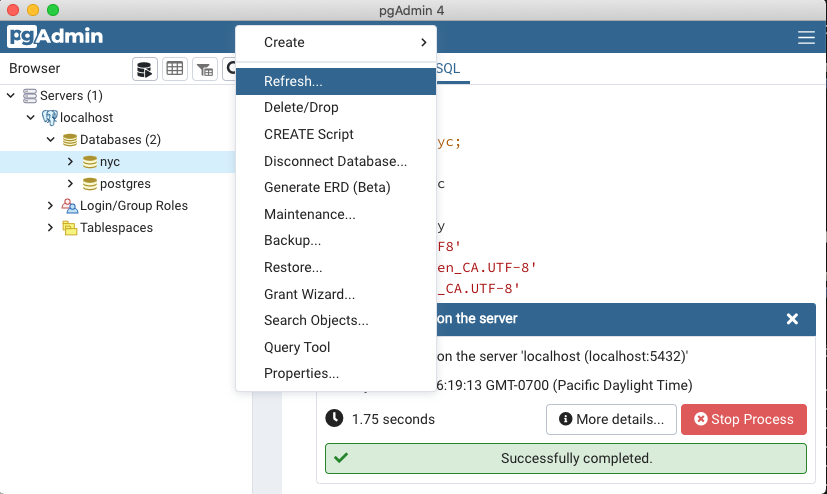
在加载完成后,右键单击**nyc**数据库,然后选择**刷新**选项以更新客户端有关数据库中存在哪些表的信息。
注解
如果您想要练习从本地空间格式加载数据,而不是使用刚刚介绍的PostgreSQL数据库备份文件,接下来的几个部分将引导您通过使用各种命令行工具和QGIS DbManager加载。请注意,如果您已经使用pgAdmin加载了数据,可以跳过这些部分。
5.2. 使用ogr2ogr加载数据¶
:file:`ogr2ogr`是一个命令行实用程序,用于在GIS数据格式之间进行转换,包括常见文件格式和常见空间数据库。
- Windows:
可以从 GIS Internals 下载ogr2ogr的构建版本。
ogr2ogr包含在 QGIS安装包 中,并可以通过OSGeo4W Shell访问 -
ogr2ogr的构建版本可以从 MS4W 下载。
- MacOS:
如果您安装了 Postgres.app ,那么您会在
/Applications/Postgres.app/Contents/Versions/*/bin目录中找到ogr2ogr。若已安装 HomeBrew ,可通过安装 gdal 软件包获取
ogr2ogr工具
- Linux:
如果您从软件包安装了QGIS,:file:`ogr2ogr`应该已经安装并在您的PATH上,作为**gdal**或**libgdal**软件包的一部分。
PostGIS的工作数据目录包含一个:file:`2000/`子目录,其中包含来自2000年人口普查的shape文件,这些文件已被2010年人口普查的数据所淘汰。我们可以使用这些文件来练习数据加载,以避免与使用备份文件已加载的数据发生名称冲突。在执行这些说明时,请确保在shell中位于:file:`2000/`子目录中:
export PGPASSWORD=mydatabasepassword
与在连接字符串中传递密码不同,我们将密码放在环境中,这样在运行命令时它不会在进程列表中可见。
请注意在Windows上,您将需要使用`set`而不是`export`。
ogr2ogr \
-nln nyc_census_blocks_2000 \
-nlt PROMOTE_TO_MULTI \
-lco GEOMETRY_NAME=geom \
-lco FID=gid \
-lco PRECISION=NO \
Pg:"dbname=nyc host=localhost user=pramsey port=5432" \
nyc_census_blocks_2000.shp
为了更清晰可见,这些行使用````显示,但在您的shell上应该写在一行上。
:file:`ogr2ogr`有**大量**的选项,而我们在这里只使用了其中的一小部分。下面是对该命令的逐行解释。
ogr2ogr \
可执行文件的名称!您可能需要确保可执行文件的位置在您的`PATH`中,或者根据您的设置使用完整的可执行文件路径。
-nln nyc_census_blocks_2000 \
**nln**选项代表“新图层名称”,并设置将在目标数据库中创建的表名称。
-nlt PROMOTE_TO_MULTI \
**nlt**选项代表“新图层类型”。特别是对于shape文件输入,新图层类型通常是“多部分几何”,因此系统需要事先告知使用“MultiPolygon”而不是“Polygon”作为几何类型。
-lco GEOMETRY_NAME=geom \
-lco FID=gid \
-lco PRECISION=NO \
lco 选项代表“图层创建选项”。不同的驱动程序具有不同的创建选项,我们在这里使用了 PostgreSQL驱动程序 的三个选项。
**GEOMETRY_NAME**设置几何列的列名。我们倾向于使用"geom"而不是默认值,以使我们的表与研讨会中的标准列名匹配。
**FID**设置主键列名。同样,我们更喜欢使用"gid",这是研讨会中使用的标准。
**PRECISION**控制数字字段在数据库中的表示方式。在加载shape文件时,默认情况下使用数据库的“numeric”类型,这更精确,但有时比“integer”和“double precision”等简单数值类型更难处理。我们使用"NO"来关闭"numeric"类型。
Pg:"dbname=nyc host=localhost user=pramsey port=5432" \
在 ogr2ogr 中,参数的顺序大致是:可执行文件,然后是选项,然后是**目标**位置,然后是**源**位置。因此,这是目标,我们PostgreSQL数据库的连接字符串。 "Pg:" 部分是驱动程序名称,然后 connection string 包含在引号中(因为它可能包含嵌入的空格)。
nyc_census_blocks_2000.shp
在这种情况下,源数据集是我们要读取的shape文件。通过在这里放置连接字符串,然后跟随图层名称列表,可以在一次调用中读取多个图层,但在这种情况下,我们只有一个要加载的shape文件。
5.3. 什么是Shapefiles?¶
你可能会问自己 --“什么是这个shapefile?”“Shapefile”通常指的是具有相同前缀名称(例如nyc_census_blocks)的一组文件,包括``.shp``、.shx、.dbf``和其他扩展名。实际上,shapefile 特指具有.shp``扩展名的文件。然而,仅有``.shp``文件是不完整的,如果没有必需的支持文件,就不能进行分发。
必需的文件:
.shp—shape格式;要素的几何信息本身.shx—shape索引格式;要素几何的位置索引.dbf—属性格式;每个形状的列属性,使用dBase III格式
可选文件包括:
.prj—投影格式;坐标系和投影信息,一个使用众所周知的文本格式描述投影的纯文本文件
`shp2pgsql`实用程序通过将形状数据从二进制数据转换为一系列SQL命令,使其在PostGIS中可用,并然后在数据库中运行这些命令以加载数据。
5.4. 使用shp2pgsql加载数据¶
:file:`shp2pgsql`将Shape文件转换为SQL。它是PostGIS代码库的一部分,并随PostGIS软件包一起提供。如果您在计算机上本地安装了PostgreSQL,您可能会发现:file:`shp2pgsql`已经与其一起安装,并且位于安装目录的可执行文件目录中。
与:file:`ogr2ogr`不同,:file:`shp2pgsql`不直接连接到目标数据库,它只是生成与输入shape文件等效的SQL。用户需要通过"管道"将SQL传递到数据库,或者将SQL保存到文件中,然后加载它。
以下是一个加载相同数据的示例调用:
export PGPASSWORD=mydatabasepassword
shp2pgsql \
-D \
-I \
-s 26918 \
nyc_census_blocks_2000.shp \
nyc_census_blocks_2000 \
| psql dbname=nyc user=postgres host=localhost
以下是对该命令的逐行解释。
shp2pgsql \
可执行程序!它读取源数据文件,并生成可以重定向到文件或通过管道传递给:file:`psql`以直接加载到数据库中的SQL。
-D \
**D**标志告诉程序生成“dump格式”,这比默认的“insert格式”加载速度要快得多。
-I \
I 标志告诉程序在加载完成后在表上创建空间索引。
-s 26918 \
**s**标志告诉程序数据的“空间参考标识符(SRID)”是什么。此研讨会的源数据全部在“UTM 18”中,其SRID为**26918**(见下文)。
nyc_census_blocks_2000.shp \
要读取的源shape文件。
nyc_census_blocks_2000 \
创建目标表时要使用的表名。
| psql dbname=nyc user=postgres host=localhost
该实用程序生成一个SQL流。"|"运算符将该流作为输入传递给:file:`psql`数据库终端程序。:file:`psql`的参数只是目标数据库的连接字符串。
5.5. SRID 26918?是什么?¶
大多数导入过程都是不言自明的,但即使是经验丰富的GIS专业人员也可能会在**SRID**上遇到问题。
“SRID”代表“空间参考标识符”。它定义了我们数据的地理坐标系和投影的所有参数。SRID很方便,因为它将地图投影的所有信息(可能相当复杂)打包成一个单一的数字。
您可以通过在在线数据库中查找来查看我们研讨会地图投影的定义,
或者直接在PostGIS中使用查询到``spatial_ref_sys``表。
SELECT srtext FROM spatial_ref_sys WHERE srid = 26918;
注解
PostGIS的``spatial_ref_sys``表是一个符合:term:`OGC`标准的表,定义了数据库中已知的所有空间参考系统。随PostGIS一起提供的数据列出了超过3000个已知的空间参考系统以及在它们之间进行转换/重投影所需的详细信息。
在两种情况下,您都会看到**26918**空间参考系统的文本表示(在此进行了漂亮的打印以提高清晰度):
PROJCS["NAD83 / UTM zone 18N",
GEOGCS["NAD83",
DATUM["North_American_Datum_1983",
SPHEROID["GRS 1980",6378137,298.257222101,AUTHORITY["EPSG","7019"]],
AUTHORITY["EPSG","6269"]],
PRIMEM["Greenwich",0,AUTHORITY["EPSG","8901"]],
UNIT["degree",0.01745329251994328,AUTHORITY["EPSG","9122"]],
AUTHORITY["EPSG","4269"]],
UNIT["metre",1,AUTHORITY["EPSG","9001"]],
PROJECTION["Transverse_Mercator"],
PARAMETER["latitude_of_origin",0],
PARAMETER["central_meridian",-75],
PARAMETER["scale_factor",0.9996],
PARAMETER["false_easting",500000],
PARAMETER["false_northing",0],
AUTHORITY["EPSG","26918"],
AXIS["Easting",EAST],
AXIS["Northing",NORTH]]
如果您打开数据目录中的``nyc_neighborhoods.prj``文件,您将看到相同的投影定义。
您从本地机构(如纽约市)接收到的数据通常会以“state plane”或“UTM”为标志的本地投影。我们的投影是“Universal Transverse Mercator (UTM) Zone 18 North”或EPSG:26918。
5.6. 要尝试的事情:使用QGIS查看数据¶
QGIS 是一个桌面GIS查看器/编辑器,用于快速查看数据。您可以查看多种数据格式,包括平面shape文件和PostGIS数据库。其图形界面使得对数据进行轻松探索、简单测试和快速样式设置成为可能。
尝试使用这个软件连接到您的PostGIS数据库。该应用程序可从 https://qgis.org 下载
首先,您会想要创建到PostGIS数据库的连接,使用菜单 Layer->Add Layer->PostGIS Layers->New,然后填写提示。一旦您建立了连接,您可以通过点击连接并选择要显示的表来添加图层。