15. 空间索引¶
回想一下,空间索引是空间数据库的三个关键特征之一。空间索引,使得大型数据集在空间数据库中的应用成为可能。如果没有索引,任何对空间要素的搜索都需要对数据库中的每条记录进行“顺序遍历”。空间索引就是把空间数据组织成树结构,树可以加速搜索过程以便找到特定的记录。
空间索引是 PostGIS 最大的本领之一。在之前的例子中,构建空间连接需要把每个空间数据表进行比较,这样的性能消耗十分巨大,为了连接两个 10000 条记录的数据表,要进行 100000000 次比较;而使用空间索引的话,最低可以低到 20000 次。
现有的数据已经有空间索引了,为了展示空间索引的表现,先删除空间索引以便比较。
现在我们对 nyc_census_blocks 数据表跑一个 没有 空间索引的查询。
第一步,先 移除 空间索引。
DROP INDEX nyc_census_blocks_geom_idx;
注解
DROP INDEX 表达式移除数据库中现有的索引。更多信息参考 PostgreSQL 文档。
执行命令后,观察 pgAdmin 查询窗口右下角的 “Timing” 面板。这个查询搜索的是每个名称以 “B” 开头的地铁站所在地区。
SELECT count(blocks.blkid)
FROM nyc_census_blocks blocks
JOIN nyc_subway_stations subways
ON ST_Contains(blocks.geom, subways.geom)
WHERE subways.name LIKE 'B%';
count
---------------
46
nyc_census_blocks 数据表很小(大概千把个记录),所以它甚至都不需要索引,这个查询在我的电脑上只用了 300 毫秒。
现在重新添加空间索引并再次运行查询。
CREATE INDEX nyc_census_blocks_geom_idx
ON nyc_census_blocks
USING GIST (geom);
注解
USING GIST 子句告诉 PostgreSQL 在创建索引时,使用通用的索引结构(GIST)。若你在创建索引时,报类似于 ERROR: index row requires 11340 bytes, maximum size is 8191 的错误,你可能就是少写了 USING GIST 子句。
在我的测试机上,查询时间降到了 50 毫秒。你的数据表越大,查询性能提升越明显。
15.1. 空间索引是如何起作用的¶
标准的数据库索引,是根据被索引的列的值去创建树结构的。空间索引略不同,因为数据库并不能索引几何字段的值 —— 也就是几何对象本身,我们改索引要素的范围边界框。
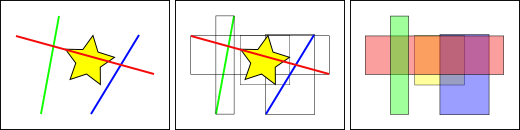
上图中,和黄色星星相交的线的数量是 1,即红色那条线。但是与黄色框相交的范围框有红色和蓝色,共 2 个。
数据库求解 “什么线与黄色星相交” 这个问题,是先用空间索引求解 “什么范围框与黄色范围框相交” 这个问题的(速度非常快),然后才是 “什么线与黄色的星星相交”。上述过程仅对于第一次测试的空间要素而言。
对于数量庞大的数据表,这种索引先行,然后局部精确计算的 “两遍法” 可以在根本上减少查询计算量。
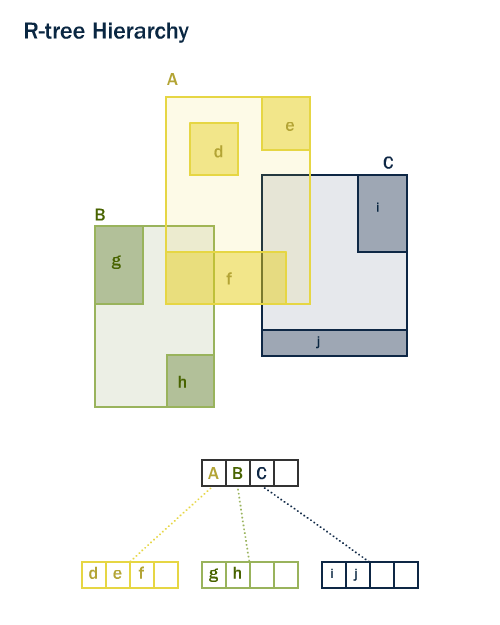
PostGIS 和 Oracle spatial 都用了 “R-Tree” 1 空间索引结构。R-Tree 把数据描述成一簇簇的矩形,它是一种自调整的索引结构,可以自动处理数据的数量、密度和大小等。
15.2. 空间索引函数¶
不是所有函数都会使用空间索引的,如果存在空间索引,那么支持使用空间索引的函数会自动使用它。
前四个是查询中最常用的,ST_DWithin 对于 “一定距离内”、“一定半径内” 的查询是非常重要的,能获得指数级别的查询性能。
未内置索引加速的函数(如常用函数`ST_Relate <http://postgis.net/docs/ST_Relate.html>`_)添加索引支持,需按以下方式增加索引专用子句。
15.3. 仅索引型查询¶
PostGIS 中的大多数常用函数(ST_Contains, ST_Intersects, ST_DWithin`等)自动包含索引过滤器。但某些函数(例如:command:`ST_Relate)不包含索引过滤器。
要使用索引(且不进行过滤)进行边界框搜索,请使用 &&`运算符。对于几何图形, :command:`&& 运算符意味着“边界框重叠或接触”,就像对于数字 = 运算符意味着“值相同”一样。
让我们将“West Village”人口的仅索引查询与更精确的查询进行比较。使用 :command:`&&`我们的仅索引查询如下所示:
SELECT Sum(popn_total)
FROM nyc_neighborhoods neighborhoods
JOIN nyc_census_blocks blocks
ON neighborhoods.geom && blocks.geom
WHERE neighborhoods.name = 'West Village';
49821
现在让我们使用更精确的 ST_Intersects 函数执行相同的查询。
SELECT Sum(popn_total)
FROM nyc_neighborhoods neighborhoods
JOIN nyc_census_blocks blocks
ON ST_Intersects(neighborhoods.geom, blocks.geom)
WHERE neighborhoods.name = 'West Village';
26718
答案要少得多!第一个查询总结了其边界框与邻域边界框相交的每个块;第二个查询仅总结了与邻域本身相交的那些块。
15.4. 分析¶
PostgreSQL 查询规划器智能地选择何时使用或不使用索引来评估查询。与直觉相反,进行索引搜索并不总是更快:如果搜索要返回表中的每条记录,则遍历索引树以获取每条记录实际上会比从头开始顺序读取整个表慢。
了解查询矩形的大小不足以确定查询是否会返回大量记录或少量记录。下面,红色方块很小,但会返回比蓝色方块更多的记录。
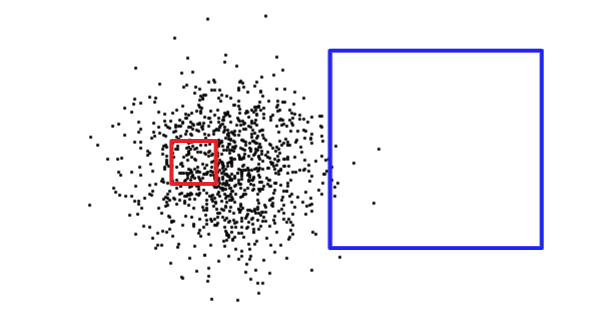
为了弄清楚它正在处理什么情况(读取表的一小部分与读取表的大部分),PostgreSQL 保留有关每个索引表列中数据分布的统计信息。默认情况下,PostgreSQL 会定期收集统计信息。但是,如果您在短时间内大幅更改表的内容,则统计信息将不是最新的。
为了确保统计信息与您的表内容匹配,明智的做法是在表中加载和删除批量数据后运行 ANALYZE 命令。这迫使统计系统收集所有索引列的数据。
ANALYZE 命令要求 PostgreSQL 遍历该表并更新其用于查询计划估计的内部统计信息(稍后将讨论查询计划分析)。
ANALYZE nyc_census_blocks;
15.5. 垃圾回收¶
值得强调的是,仅仅创建索引并不足以让 PostgreSQL 有效地使用它。每当对表发出大量 UPDATE、INSERT 或 DELETE 时,都必须执行 VACUUMing。该 ``VACUUM``命令要求 PostgreSQL 回收因更新或删除记录而留下的表页中任何未使用的空间。
清理对于数据库的高效运行至关重要,因此 PostgreSQL 默认提供“自动清理”功能。
Autovacuum 根据活动级别确定的合理时间间隔对表进行真空处理(恢复空间)和分析(更新统计信息)。虽然这对于高度事务性数据库至关重要,但不建议在添加索引或批量加载数据后等待 autovacuum 运行。每当执行大批量更新时,您应该手动运行``VACUUM`` 。
可以根据需要单独执行数据库的清理和分析。发出 VACUUM 命令不会更新数据库统计信息;同样,发出``ANALYZE``命令将不会恢复未使用的表行。这两个命令都可以针对整个数据库、单个表或单个列运行。
VACUUM ANALYZE nyc_census_blocks;
15.6. 函数列表¶
geometry_a && geometry_b:若 A 的范围框覆盖了 B 的,则返回 TRUE.
geometry_a = geometry_b:在 PostGIS 2.4 之前,如果 A 的边界框与 B 相同,则返回 TRUE。从 PostGIS 2.4 开始,只有当 A 的geometry 与 B 完全相同时,才返回 TRUE。
geometry_a ~= geometry_b:如果 A 的边界框等于 B 的边界框,则返回 TRUE。
ST_Intersects(geometry_a, geometry_b):若 Geometries 对象或 Geography 对象存在 “空间相交”,即有任意部分重叠,返回 TRUE,否则返回 FALSE.
脚注
