40. 高度なジオメトリ構築¶
ここまで、``nyc_subway_stations``レイヤは多数の興味深い例を提供してきました。しかし、次の図の通り、印象深いものがあります:
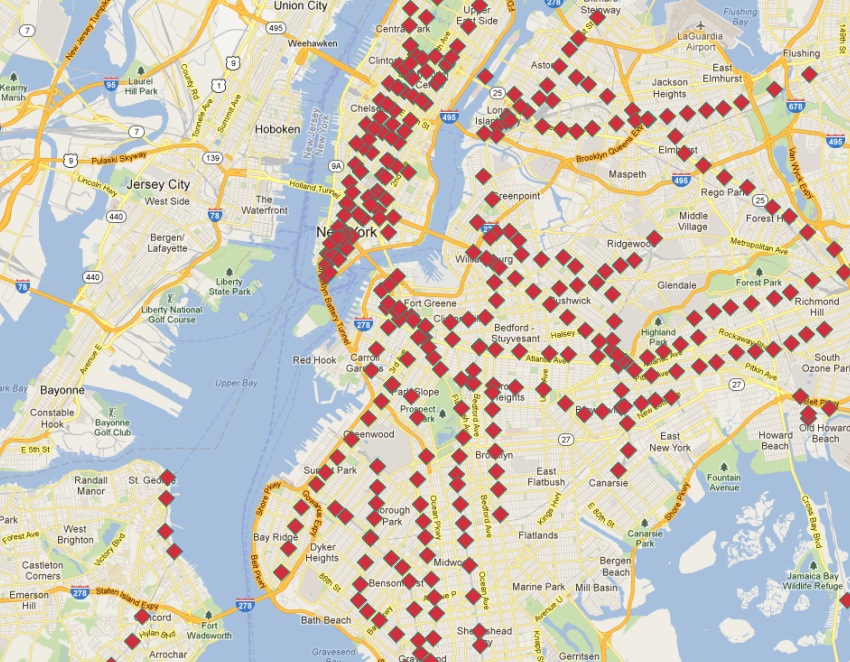
全ての駅のデータベースですが、経路の簡単な可視化ができません! 本章ではPostgreSQLとPostGISの高度な機能を使って、地下鉄駅のポイントレイヤから新しい経路レイヤを構築します。
ここでの作業は、次に示す二つの問題のため特に難しくなっています:
``nyc_subway_stations``の``routes``カラムには、行ごとに重複する経路識別子があり、複数経路で出現する可能性のある駅がテーブルに一度しか出現しません。
先の問題と関連しますが、駅テーブルには経路の順序情報がありません。特定のルート上の全ての駅が発見できても、属性を使って電車が駅を通る順番を決定することができません。
二つ目の問題は、一つ目より大変です: 経路の点の集合が順序付けされていない場合に、どのようにして実際の経路と合致するように順序付けをするかです。
'Q'列車の停車駅は次の通りです:
SELECT s.gid, s.geom
FROM nyc_subway_stations s
WHERE (strpos(s.routes, 'Q') <> 0);
この図では、停車駅のラベルに一意の値を取る主キー``gid``を使っています。
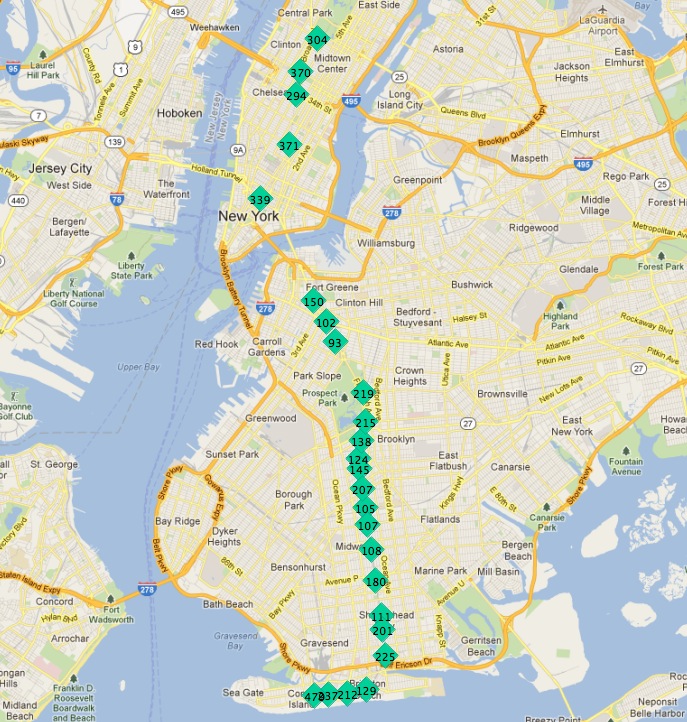
末端駅の一つから出発したとして、戦場の次の駅は常に最短であるようです。前に発見された駅を検索対象から外す限り処理を繰り返すことができます。
このようなデータベース内の反復ルーチンの実行には二つの方法があります:
共通テーブル式 (Common Table Expression, CTE)は、実行に関数定義が費用である長所があります。最北の停車駅 (``gid``は304)から始めた'Q'列車の経路の計算のためのCTEを示します。
WITH RECURSIVE next_stop(geom, idlist) AS (
(SELECT
geom,
ARRAY[gid] AS idlist
FROM nyc_subway_stations
WHERE gid = 304)
UNION ALL
(SELECT
s.geom,
array_append(n.idlist, s.gid) AS idlist
FROM nyc_subway_stations s, next_stop n
WHERE strpos(s.routes, 'Q') != 0
AND NOT n.idlist @> ARRAY[s.gid]
ORDER BY ST_Distance(n.geom, s.geom) ASC
LIMIT 1)
)
SELECT geom, idlist FROM next_stop;
CTEは、次の二つのものを結合しています:
一つ目は、式の開始点を確立するものです。初期ジオメトリを得て、訪問した駅の識別子の配列を"gid" 304 (経路の端点)の行で初期化します。
二つ目は、それ以上の行がなくなるまでの繰り返しです。繰り返し毎に、前回の繰り返しの時の値を、"next_stop"への自己参照から取得します。訪問済みリスト (NOT n.idlist @> ARRAY[s.gid])に追加していないQ線 (strpos(s.routes,'Q'))上の全ての駅を探し、前のポイントからの距離で並べ替えを施し、最初の行を得ます (最短になります)。
再帰的CTE自体以外にも、ここで仕様される高度なPostgreSQL配列機能がいくつかあります:
私たちは配列を使用しています! PostgreSQLは任意型の配列をサポートしています。この場合、整数配列がありますが、ジオメトリ配列や他のPostgreSQL型の配列を作ることができます。
訪問した駅の識別子の配列の構築に array_append を使います。
Q列車の駅のうちどれが訪問済みかを見つけるのに、配列演算子 @> (「配列に含まれる」)を使います。@> 演算子は両側がARRAYである必要があるので、個々の "gid" 番号をARRAY[]構文で1要素の配列にする必要があります。
クエリを実行する時、見つかった順 (順路順)で個々のジオメトリと、既に訪問した駅識別子の一覧とが得られます。ジオメトリをPostGISの集約関数 ST_MakeLine に与えると、ジオメトリ集合を与えられた順序の単一の線に変換して出力しあmす。
WITH RECURSIVE next_stop(geom, idlist) AS (
(SELECT
geom,
ARRAY[gid] AS idlist
FROM nyc_subway_stations
WHERE gid = 304)
UNION ALL
(SELECT
s.geom,
array_append(n.idlist, s.gid) AS idlist
FROM nyc_subway_stations s, next_stop n
WHERE strpos(s.routes, 'Q') != 0
AND NOT n.idlist @> ARRAY[s.gid]
ORDER BY ST_Distance(n.geom, s.geom) ASC
LIMIT 1)
)
SELECT ST_MakeLine(geom) AS geom FROM next_stop;
次のようになります:
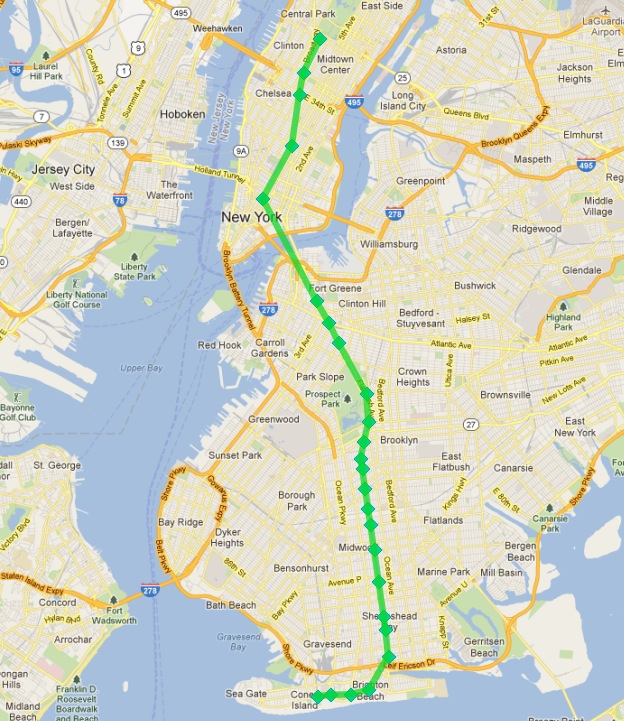
成功!
ただし二つの問題があります:
私たちは一つの地下鉄の経路を計算しただけです。全ての経路を計算したいのです。
クエリには*先験的*知識の一部である、順路を構築する探索アルゴリズムのシードとして機能する初期の駅の識別子が含まれています。
先に難しい問題から挑戦してみましょう。ある順路の最初の駅を、順路を作る駅の集合を、目で見たり手計算をしたりせずに出してみましょう。
Q列車の停車駅は始点として使うことができます。順路の終着駅の特徴は何でしょうか?
一つの答えが「最も北と南にある駅です」となります。しかしながら、Q列車が西から東に走ると想像してみましょう。条件は維持されるでしょうか?
終着駅の最も方向と関係の薄い特徴は「順路の中央から最も遠い駅です」。この特徴を使うと、順路が南北あるいは東西に進んでも問題にならず、程度の差はありますが一方向に進みます。特に終着駅ではそうなります。
終了点を算定する100%のヒューリスティックは存在しないので、2番目の規則を試してみましょう。
注釈
「中央から最も遠い」規則の明らかな失敗例は、ロンドンなどにある環状線です。幸運なことにニューヨークにはそのような路線はないのです!
あらゆる順路の終着駅を計算するには、どういう順路が存在するかをまず計算しなくてはいけません。別個の順路を見つけていきます。
WITH routes AS (
SELECT DISTINCT unnest(string_to_array(routes,',')) AS route
FROM nyc_subway_stations ORDER BY route
)
SELECT * FROM routes;
二つの高度なPostgreSQL配列関数を使っていることにご注意ください:
**string_to_array**は文字列を取り、区切り文字を使って配列に分割します。PostgreSQLは配列をサポートします が要素はどの型でも対応できます。ですから、文字列配列を構築できますし、この例の後半で見ることになりますが、ジオメトリとジオグラフィの配列も構築できます。
**unnest**は、配列を取り、配列の個々の要素の新しい行を構築します。一つの行に埋め込まれた「水平」配列を取り、要素ごとの値の行を持つ「垂直」配列に変換する効果を持ちます。
結果は一意の地下鉄順路識別子のリストです。
route
-------
1
2
3
4
5
6
7
A
B
C
D
E
F
G
J
L
M
N
Q
R
S
V
W
Z
(24 rows)
この結果を``nyc_subway_stations``テーブルに結合して、順路ごとに駅の行を持つ新しいテーブルを作ることで構築できます。
WITH routes AS (
SELECT DISTINCT unnest(string_to_array(routes,',')) AS route
FROM nyc_subway_stations ORDER BY route
),
stops AS (
SELECT s.gid, s.geom, r.route
FROM routes r
JOIN nyc_subway_stations s
ON (strpos(s.routes, r.route) <> 0)
)
SELECT * FROM stops;
gid | geom | route
-----+----------------------------------------------------+-------
2 | 010100002026690000CBE327F938CD21415EDBE1572D315141 | 1
3 | 010100002026690000C676635D10CD2141A0ECDB6975305141 | 1
20 | 010100002026690000AE59A3F82C132241D835BA14D1435141 | 1
22 | 0101000020266900003495A303D615224116DA56527D445141 | 1
...etc...
順路ごとの全ての駅を集めてマルチポイントにしたうえで、マルチポイントの重心を計算することで、中心点を得ることができます。
WITH routes AS (
SELECT DISTINCT unnest(string_to_array(routes,',')) AS route
FROM nyc_subway_stations ORDER BY route
),
stops AS (
SELECT s.gid, s.geom, r.route
FROM routes r
JOIN nyc_subway_stations s
ON (strpos(s.routes, r.route) <> 0)
),
centers AS (
SELECT ST_Centroid(ST_Collect(geom)) AS geom, route
FROM stops
GROUP BY route
)
SELECT * FROM centers;
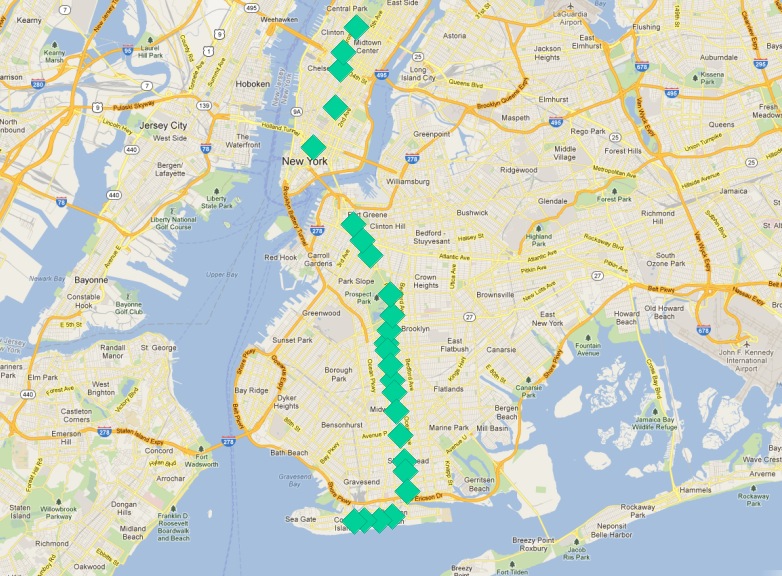
Q列車の停車駅のコレクションの中心点は次のようになります:
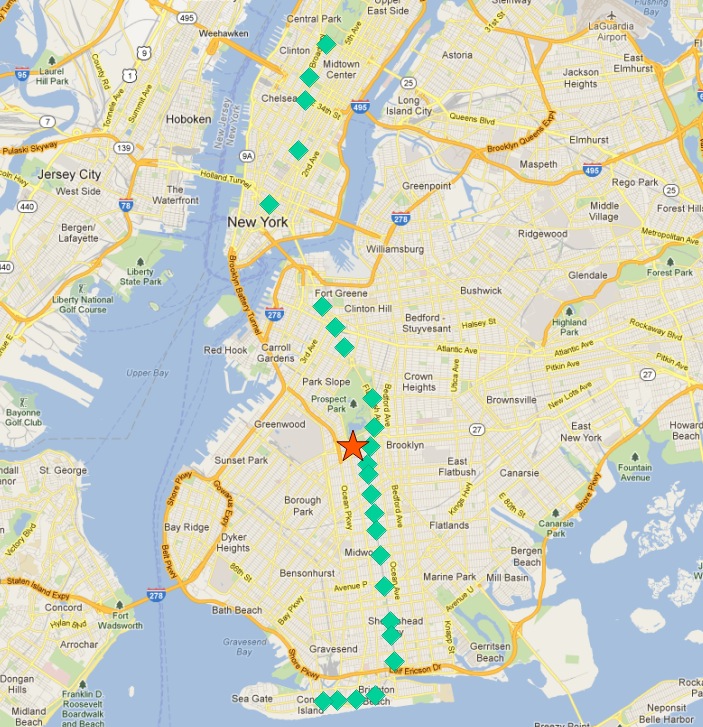
最も北で終着駅となる駅は、中心から最も遠い駅でもあります。順路ごとに最も遠いポイントを計算してみましょう。
WITH routes AS (
SELECT DISTINCT unnest(string_to_array(routes,',')) AS route
FROM nyc_subway_stations ORDER BY route
),
stops AS (
SELECT s.gid, s.geom, r.route
FROM routes r
JOIN nyc_subway_stations s
ON (strpos(s.routes, r.route) <> 0)
),
centers AS (
SELECT ST_Centroid(ST_Collect(geom)) AS geom, route
FROM stops
GROUP BY route
),
stops_distance AS (
SELECT s.*, ST_Distance(s.geom, c.geom) AS distance
FROM stops s JOIN centers c
ON (s.route = c.route)
ORDER BY route, distance DESC
),
first_stops AS (
SELECT DISTINCT ON (route) stops_distance.*
FROM stops_distance
)
SELECT * FROM first_stops;
今回は二つのサブクエリを追加しました:
stops_distance は、順路の中心の点を駅テーブルに結合し、駅と順路ごとの中心との距離を計算します。結果に対してレコードが順路ごとのかたまりで出力され、最も遠い駅を、かたまりの最初のレコードとするよう並べ替えを行っています。
first_stops は、かたまりごとの最初のレコードの取得だけを行って stops_distance の出力をフィルタリングします。stops_distance に最初のレコードが最も遠いレコードとなるよう並べ替えているため、それが個々の地下鉄の順路を構築するための開始シードとして使う駅となります。
現在、全ての順路を知っていて、かつ、おおよそで順路ごとのどの駅から開始されるかを知っています。これで順路の線を生成する準備ができました!
ただし、最初に、再帰的CTE式を、パラメータ付きで呼び出すことができる関数に変換する必要があります。
CREATE OR REPLACE function walk_subway(integer, text) returns geometry AS
$$
WITH RECURSIVE next_stop(geom, idlist) AS (
(SELECT
geom AS geom,
ARRAY[gid] AS idlist
FROM nyc_subway_stations
WHERE gid = $1)
UNION ALL
(SELECT
s.geom AS geom,
array_append(n.idlist, s.gid) AS idlist
FROM nyc_subway_stations s, next_stop n
WHERE strpos(s.routes, $2) != 0
AND NOT n.idlist @> ARRAY[s.gid]
ORDER BY ST_Distance(n.geom, s.geom) ASC
LIMIT 1)
)
SELECT ST_MakeLine(geom) AS geom
FROM next_stop;
$$
language 'sql';
そうして、実行準備が整います!
CREATE TABLE nyc_subway_lines AS
-- Distinct route identifiers!
WITH routes AS (
SELECT DISTINCT unnest(string_to_array(routes,',')) AS route
FROM nyc_subway_stations ORDER BY route
),
-- Joined back to stops! Every route has all its stops!
stops AS (
SELECT s.gid, s.geom, r.route
FROM routes r
JOIN nyc_subway_stations s
ON (strpos(s.routes, r.route) <> 0)
),
-- Collects stops by routes and calculate centroid!
centers AS (
SELECT ST_Centroid(ST_Collect(geom)) AS geom, route
FROM stops
GROUP BY route
),
-- Calculate stop/center distance for each stop in each route.
stops_distance AS (
SELECT s.*, ST_Distance(s.geom, c.geom) AS distance
FROM stops s JOIN centers c
ON (s.route = c.route)
ORDER BY route, distance DESC
),
-- Filter out just the furthest stop/center pairs.
first_stops AS (
SELECT DISTINCT ON (route) stops_distance.*
FROM stops_distance
)
-- Pass the route/stop information into the linear route generation function!
SELECT
ascii(route) AS gid, -- QGIS likes numeric primary keys
route,
walk_subway(gid, route) AS geom
FROM first_stops;
-- Do some housekeeping too
ALTER TABLE nyc_subway_lines ADD PRIMARY KEY (gid);
最終テーブルをQGISで可視化すると次のようになります:
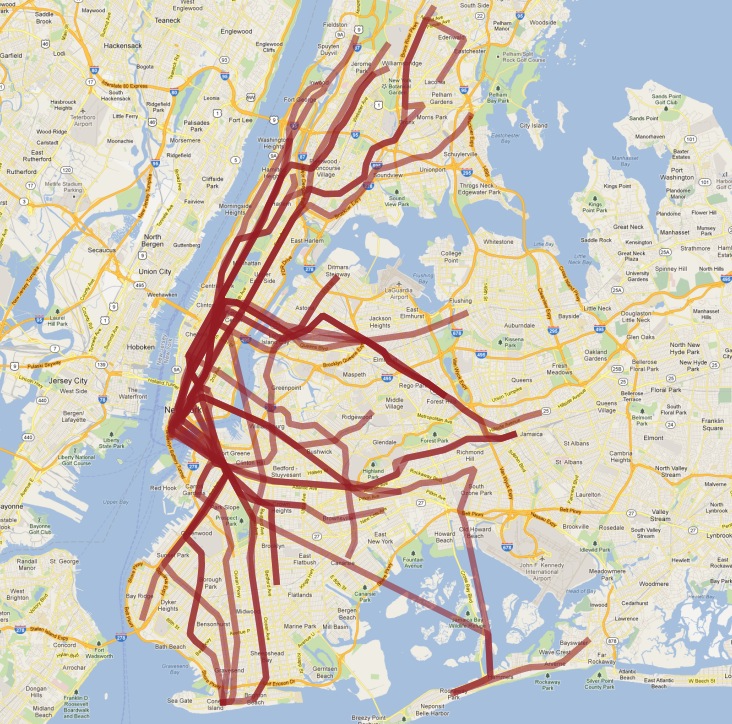
いつものように、データの単純な理解では問題があります:
実は二つの 'S' (短距離の「シャトル」)列車がマンハッタンとロックウエイにあり、どちらも 'S' と呼ばれるので、これをつなげてしまっています。
'4'列車 (と他少数の列車) は一つの線の終着駅がが二つの終端に分割され、「一つの線になる」仮定が壊れ、結果の終わりに、おかしなフックがあります。
うまくいけば、この例で、PostgreSQLとPostGISの高度な機能の組み合わせである複雑なデータ処理を味わってもらえます。
