15. Indexación espacial¶
Como se ha visto, los índices son una de las tres funcionalidades clave de una base de datos espacial. Los índices hacen que sea posible usar una base de datos espacial para conjuntos de datos grandes. Sin los índices, cualquier búsqueda de un elemento requeriría un «escáner secuencial» de cada registro en la base de datos. El indexado acelera la búsqueda organizando los datos en un árbol de búsqueda que puede ser atravesado rápidamente para encontrar un registro concreto.
Los índices espaciales son uno de los grandes valores de PostGIS. En el ejemplo anterior, realizar uniones espaciales requiere comparar la una con la otra ambas tablas completas. Esto puede ser muy costoso: unir dos tablas de 10.000 registros cada una requerirá 100.000.000 comparaciones; con índices el coste podría ser tan bajo como 20.000 comparaciones.
Nuestro fichero de carga de datos ya contiene índices espaciales para todas las tablas, por lo que para demostrar la eficacia de los índices, vamos a eliminarlos primero.
Lancemos una query sobre nyc_census_blocks sin nuestro índice espacial.
El primer paso es eliminar el índice.
DROP INDEX nyc_census_blocks_geom_idx;
Nota
La sentencia DROP INDEX elimina un índice ya existente de la base de datos. Para más información, mirar la documentación de PostgreSQL.
Ahora, fíjate en el medidor «Timing» en la esquina inferior derecha de la ventana de consultas de pgAdmin y ejecuta lo siguiente. Nuestra consulta busca a través de cada uno de los bloques del censo para identificar los bloques que contienen paradas de metro que empiezen por la letra «B».
SELECT count(blocks.blkid)
FROM nyc_census_blocks blocks
JOIN nyc_subway_stations subways
ON ST_Contains(blocks.geom, subways.geom)
WHERE subways.name LIKE 'B%';
count
---------------
46
La tabla nyc_census_blocks es muy pequeña (solo unos pocos miles de registros) así que, incluso sin un índice, la consulta solo tarda 300 ms en mi ordenador de pruebas.
Ahora añadimos el índice espacial de nuevo y volvemos a lanzar la consulta.
CREATE INDEX nyc_census_blocks_geom_idx
ON nyc_census_blocks
USING GIST (geom);
Nota
La cláusula USING GIST le dice a PostgreSQL que use la estructura general de índices (GIST, por sus siglas en inglés) para construir el índice. Si sale un error parecido a ERROR: index row requires 11340 bytes, maximum size is 8191 al crear el índice, lo más probable es que no se haya añadido la cláusula USING GIST.
En mi ordenador de pruebas el tiempo baja hasta los 50 ms. Cuanto más grande sea la tabla, mayor será la mejora en la velocidad relativa de una consulta que utiliza un índice.
15.1. Cómo funcionan los Índices Espaciales¶
Los índices de las bases de datos estándar crean un árbol jerárquico basado en los valores de la columna que se está indexando. Los índices espaciales son un poco diferentes –no pueden indexar los elementos geográficos, si no que indexan las cajas de los mismos.
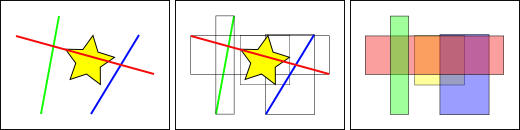
En la figura anterior, el número de líneas que intersectan la estrella amarilla es una, la línea roja. Pero las cajas envolventes de las entidades que intersectan la caja amarilla son dos, la roja y la azul.
La forma en que la base de datos responde de una forma eficiente a la pregunta «¿qué lineas intersecan con la estrella amarilla?» es responder primero «¿qué cajas intersecan con la caja amarilla?» usando el índice (lo cual es muy rápido) y entonces hace el cálculo exacto de «¿qué lineas intersecan con la estrella amarilla?» sólo con aquellas que han sido devueltas de la primera consulta.
Para tablas grandes, este sistema de «dos pasos» de evaluar el índice aproximado primero y después determinar el resultado exacto puede reducir de una forma drástica los cálculos necesarios para responder a una consulta.
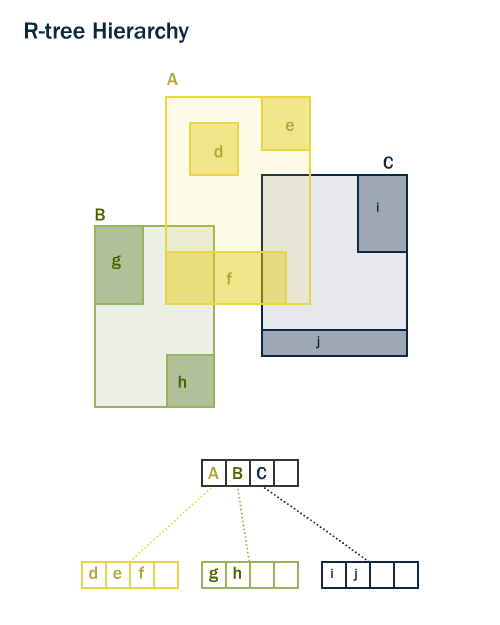
Tanto PostGIS como Oracle Spatial comparten la misma estructura de índice espacial R-Tree» 1. Los R-Trees separan los datos en rectángulos, y sub-rectángulos y sub-sub-rectángulos, etc. Es una estructura de índices autoajustable que automáticamente maneja densidades de datos variables, distintas cantidades de superposiciones de objetos y tamaños de objeto.
15.2. Funciones con Indexación Espacial¶
Sólo una parte de las funciones usan un índices espacial de forma automática, en caso de estar disponible.
Los cuatro primeros son los más utilizados en consultas y ST_DWithin es muy importante para hacer consultas tipo «dentro de una distancia» o «dentro de un radio» consiguiendo un rendimiento óptimo por el índice.
Para añadir aceleración por índices a otras funciones que no están en esta lista (la más habitual, ST_Relate) hay que añadir una clausula de indexación como la descrita debajo.
15.3. Consultas solo con índice¶
La mayoría de las funciones usadas comunmente en PostGIS (ST_Contains, ST_Intersects, ST_DWithin, etc) incluyen un filtrado por índice automáticamente. Pero algunas funciones (p. ej.: ST_Relate) no incluyen este filtrado.
Para hacer una búsqueda por bounding-box usando el índice (y sin filtrado), usa el operador &&. Para geometrías, el operador && significa «las cajas envolventes se superponen o se tocan» de la misma forma en que para números el operador = significa «los valores son iguales».
Comparemos una consulta solo con índice para la población de “West Village” con una consulta más exacta. Usando && nuestra consulta solo con índice se ve así:
SELECT Sum(popn_total)
FROM nyc_neighborhoods neighborhoods
JOIN nyc_census_blocks blocks
ON neighborhoods.geom && blocks.geom
WHERE neighborhoods.name = 'West Village';
49821
Ahora, hagamos la misma consulta usando la función ST_Intersects, que es más exacta.
SELECT Sum(popn_total)
FROM nyc_neighborhoods neighborhoods
JOIN nyc_census_blocks blocks
ON ST_Intersects(neighborhoods.geom, blocks.geom)
WHERE neighborhoods.name = 'West Village';
26718
¡Una respuesta mucho menor! La primera consulta sumó todos los bloques cuya caja envolvente intersecta la caja envolvente del vecindario; la segunda consulta solo sumó aquellos bloques que intersectan el vecindario mismo.
15.4. Analizando¶
El planificador de consultas de PostgreSQL elige de forma inteligente cuándo usar o no usar índices para evaluar una consulta. Contraintuitivamente, no siempre es más rápido hacer una búsqueda con índice: si la búsqueda va a devolver todos los registros de la tabla, recorrer el árbol del índice para obtener cada registro será en realidad más lento que leer secuencialmente toda la tabla desde el principio.
Saber el tamaño del rectángulo de la consulta no es suficiente para determinar si una consulta devolverá un número grande o pequeño de registros. Abajo, el cuadrado rojo es pequeño, pero devolverá muchos más registros que el cuadrado azul.
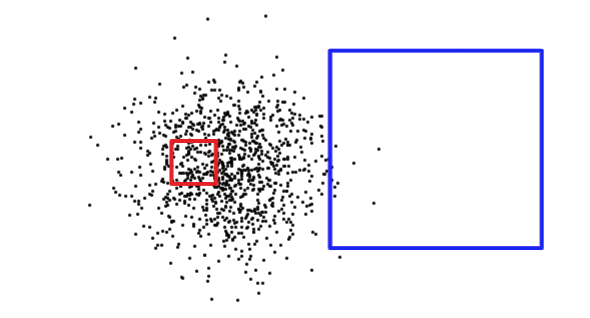
Para determinar con qué situación se enfrenta (leer una pequeña parte de la tabla versus leer una gran porción de la tabla), PostgreSQL mantiene estadísticas sobre la distribución de datos en cada columna indexada de la tabla. Por defecto, PostgreSQL recopila estadísticas de forma regular. Sin embargo, si cambias dramáticamente el contenido de tu tabla en un corto periodo de tiempo, las estadísticas no estarán actualizadas.
Para asegurarte de que las estadísticas coincidan con el contenido de tu tabla, es recomendable ejecutar el comando ANALYZE después de cargas masivas de datos y eliminaciones en tus tablas. Esto fuerza al sistema de estadísticas a recopilar datos de todas tus columnas indexadas.
El comando ANALYZE le pide a PostgreSQL recorrer la tabla y actualizar sus estadísticas internas usadas para la estimación de planes de consulta (el análisis de planes de consulta se discutirá más adelante).
ANALYZE nyc_census_blocks;
15.5. Vacuuming¶
Vale la pena enfatizar que simplemente crear un índice no es suficiente para permitir que PostgreSQL lo use de manera efectiva. Se debe realizar VACUUM siempre que se ejecuten un gran número de UPDATEs, INSERTs o DELETEs contra una tabla. El comando VACUUM le pide a PostgreSQL recuperar cualquier espacio no usado en las páginas de la tabla dejado por actualizaciones o eliminaciones de registros.
El vacuuming es tan crítico para la ejecución eficiente de la base de datos que PostgreSQL proporciona una facilidad de «autovacuum» predeterminada.
Autovacuum tanto vacía (recupera espacio) como analiza (actualiza estadísticas) tus tablas en intervalos razonables determinados por el nivel de actividad. Aunque esto es esencial para bases de datos altamente transaccionales, no es recomendable esperar una ejecución de autovacuum después de añadir índices o cargar datos masivamente. Siempre que se realice una actualización en lote grande, debes ejecutar manualmente VACUUM.
Vacuuming y analizar la base de datos pueden realizarse por separado según sea necesario. Ejecutar el comando VACUUM no actualizará las estadísticas de la base de datos; del mismo modo, ejecutar un comando ANALYZE no recuperará filas de tabla no usadas. Ambos comandos pueden ejecutarse contra toda la base de datos, una sola tabla o una sola columna.
VACUUM ANALYZE nyc_census_blocks;
15.6. Lista de funciones¶
geometry_a && geometry_b: Devuelve TRUE si la caja envolvente de A se superpone con la de B.
geometry_a = geometry_b: Antes de PostGIS 2.4 devuelve TRUE si la caja envolvente de A es la misma que la de B. A partir de la versión 2.4 devuelve TRUE solo si la geometría de A es la misma que la de B.
geometry_a ~= geometry_b: Devuelve TRUE si la caja envolvente de A es igual a la caja envolvente de B.
ST_Intersects(geometry_a, geometry_b): Devuelve TRUE si las geometrías/geografías «intersectan espacialmente» (comparten alguna porción del espacio) y FALSE si no lo hacen (son disjuntas).
Nota al pie
