27. Clustering sobre índices¶
La velocidad máxima a la que las bases de datos pueden recuperar información depende de la velocidad a la que puedan leerla del disco. Las bases de datos pequeñas pueden cargar toda su información en el cache RAM y evitar las limitaciones físicas de los discos, pero para bases de datos grandes el acceso al disco físico será un tope en cuanto a la velocidad de acceso a disco.
Los datos se escriben a disco de forma oportunista, de forma que no hay necesariamente ninguna correlación entre el orden en que se almacenan en disco y la forma en que las aplicaciones accederán a ellos o los organizarán.
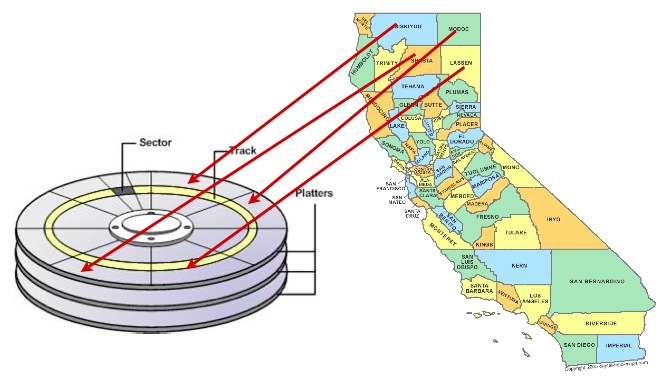
Una forma de acelerar el acceso a los datos es asegurarse de que los registros que probablemente se recuperarán juntos se encuentran en ubicaciones físicas similares en los platos del disco duro. Esto se denomina «agrupación».
El esquema de agrupación adecuado puede ser complicado, pero se aplica una regla general: los índices definen un esquema de ordenación natural para los datos que es similar al patrón de acceso que se utilizará para recuperar los datos.
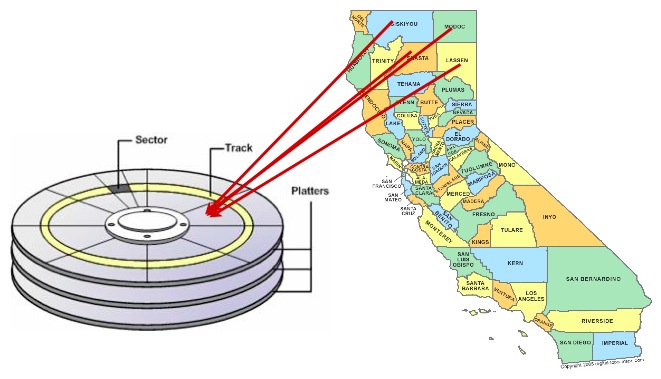
Por ello, ordenar los datos en el disco en el mismo orden que el índice puede proporcionar una ventaja de velocidad en algunos casos.
27.1. Clustering sobre el R-Tree¶
Se suele acceder a los datos espaciales en ventanas correladas espacialmente: piensemos en la ventana de mapa de una aplicación web o de escritorio. Todos los datos en la ventana tienen un valor de localización similar (¡o no estarían dentro de la ventana!)
Así, el clustering basado en un índice espacial tiene sentido para datos espaciales a los que se va a acceder mediante queries espaciales: cosas similares tienden a tener localizaciones similares.
Vamos a hacer un cluster con nuestro nyc_census_blocks basado en su índice espacial:
-- Cluster the blocks based on their spatial index
CLUSTER nyc_census_blocks USING nyc_census_blocks_geom_idx;
El comando re-escribe nyc_census_blocks en el orden definido por el índice espacial nyc_census_blocks_geom_gist. ¿Se percibe una diferencia de velocidad? Quizás no, porque los datos originales puede que tenga ya algún orden espacial preexistente (esto no es raro en los juegos de datos de SIG).
27.2. Disco vs Memoria/SSD¶
La mayoría de las bases de datos modernas funcionan sobre almacenamiento SSD, que es mucho más rápido para accesos aleatorios que los viejos medios discos magnéticos girantes. Además, la mayoría de las bases de datos modernas funcionan sobre datos que son los bastante pequeños para caber en la RAM del servidor de la base de datos, y terminan allí según el «sistema de archivos virtual» del sistema operativo los va cacheando.
¿Es todavía necesario el clustering?
Surprisingly, yes. Keeping records that are «near each other» in space «near each other» in memory increases the odds that related records will move up the servers «memory cache hierarchy» together, and thus make memory accesses faster.
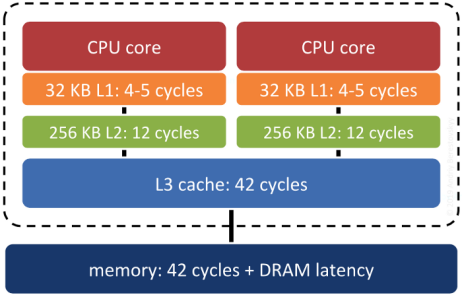
System RAM is not the fastest memory on a modern computer. There are several levels of cache between system RAM and the actual CPU, and the underlying operating system and processor will move data up and down the cache hierarchy in blocks. If the block getting moved up happens to include the piece of data the system will need next… that’s a big win. Correlating the memory structure with the spatial structure is a way in increase the odds of that win happening.
27.3. ¿Importa la Estructura del Índice?¶
En teoría, sí. En la práctica, realmente no. Ya que el índice es una descomposición espacial de los datos «bastante buena», el principal factor que afectará al rendimiento será el orden de las tuplas de la tabla.
La diferencia entre «sin indice» e «índice» normalmente es muy grande y muy medible. La diferencia entre «índice mediocre» y «gran índice» normalmente requiere una medida muy cuidadosa para diferenciar y puede ser muy sensible a la carga de trabajo que se esté testando.
