27. 索引聚类¶
数据库的查询速度受限于磁盘读取性能。小型数据库可完全载入内存缓存,从而规避物理磁盘的瓶颈;但对于大型数据库而言,物理磁盘的I/O速度将成为数据访问的关键制约因素。
数据写入磁盘的顺序具有随机性,因此磁盘存储顺序与应用程序访问或组织方式之间不存在必然关联。
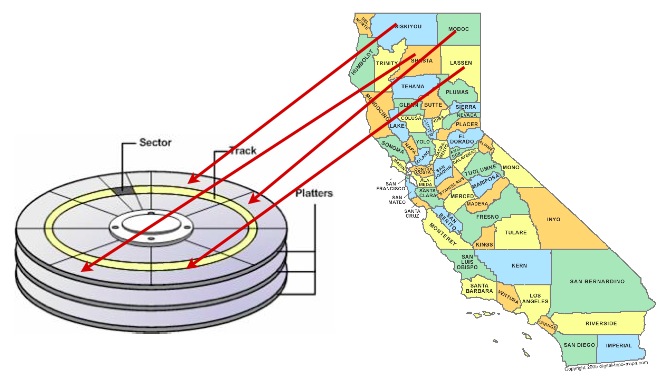
提升数据访问速度的一种有效方法是通过"聚类"(Clustering)技术,确保可能被同时检索的记录在物理磁盘上相邻存储。
选择合适的聚类方案可能较为复杂,但有一条通用原则:索引定义了数据的自然排序方式,这种排序应与数据检索时的访问模式相匹配。
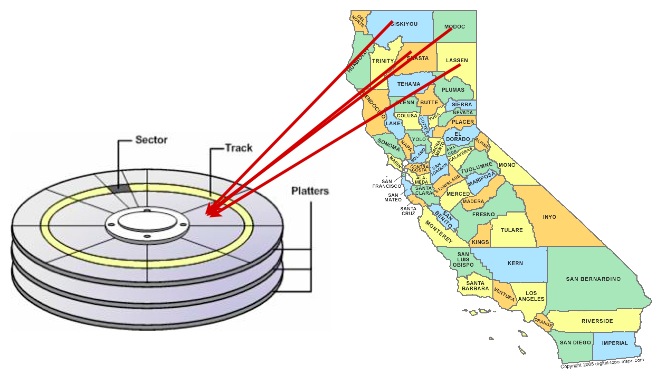
因此,将磁盘上的数据按照索引顺序存储,在某些情况下可获得查询加速效果。
27.1. 基于R-Tree的聚类¶
空间数据的访问往往具有空间相关性:例如网页或桌面应用中的地图窗口。窗口内的所有数据都具有相似的地理位置特征(否则就不会出现在该窗口中!)
因此,基于空间索引的聚类操作特别适合将通过空间查询访问的数据——因为具有相似特征的对象往往位置也相近。
基于空间索引对``nyc_census_blocks``进行聚类操作:
-- Cluster the blocks based on their spatial index
CLUSTER nyc_census_blocks USING nyc_census_blocks_geom_idx;
该命令会按照空间索引``nyc_census_blocks_geom_gist``定义的顺序重写``nyc_census_blocks``表数据。您可能感知不到速度差异——因为原始数据可能已具备一定的空间预排序(这在GIS数据集中较为常见)。
27.2. 磁盘存储 vs 内存/固态存储¶
现代数据库普遍采用固态硬盘(SSD)存储,其随机访问速度远胜传统机械硬盘。此外,当代数据库处理的数据量通常足够小,可完全载入数据库服务器的内存空间,并最终通过操作系统"虚拟文件系统"进行缓存。
空间索引聚类是否仍有必要?
Surprisingly, yes. Keeping records that are "near each other" in space "near each other" in memory increases the odds that related records will move up the servers "memory cache hierarchy" together, and thus make memory accesses faster.
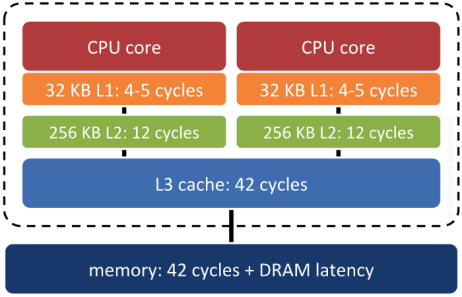
System RAM is not the fastest memory on a modern computer. There are several levels of cache between system RAM and the actual CPU, and the underlying operating system and processor will move data up and down the cache hierarchy in blocks. If the block getting moved up happens to include the piece of data the system will need next... that's a big win. Correlating the memory structure with the spatial structure is a way in increase the odds of that win happening.
27.3. 索引结构是否影响性能?¶
理论上可行,但实际效果有限。只要索引能对数据实现「基本合理」的空间分解,查询性能的主要决定因素仍是表数据的物理存储顺序。
"无索引"与"有索引"的性能差异通常非常显著且易于量化,而"普通索引"与"优化索引"的差距往往需要精细测试才能辨别,且对具体工作负载高度敏感。
