29. Пошук найближчого сусіда¶
29.1. Що таке пошук найближчого сусіда?¶
Часто задається просторовий запит: «що є найближчим <кандидат-елемент> до <елемент запиту>?»
На відміну від пошуку за відстанню, пошук «найближчого сусіда» не включає жодних обмежень щодо відстані, на якій можуть знаходитися геометрії-кандидати. Будуть прийняті об’єкти, що знаходяться на будь-якій відстані, якщо вони є найближчими.
PostgreSQL вирішує проблему найближчого сусіда, вводячи оператор «order by distance» (<->), який змушує базу даних використовувати індекс для прискорення сортування набору результатів. За допомогою оператора «order by distance» запит на найближчого сусіда може повернути «N найближчих об’єктів», просто додавши сортування та обмеживши набір результатів до N записів.
Оператор «order by distance» працює як для геометричних, так і для географічних типів. Єдина відмінність між цими двома типами полягає у значенні відстані, що повертається. Для геометрії <-> повертає той самий результат, що і ST_Distance, який залежить від одиниць виміру використовуваної системи просторових координат. Для географії повертається значення відстані по сфері, а не більш точна сфероїдальна відстань, яку повертає ST_Distance(geography,geography).
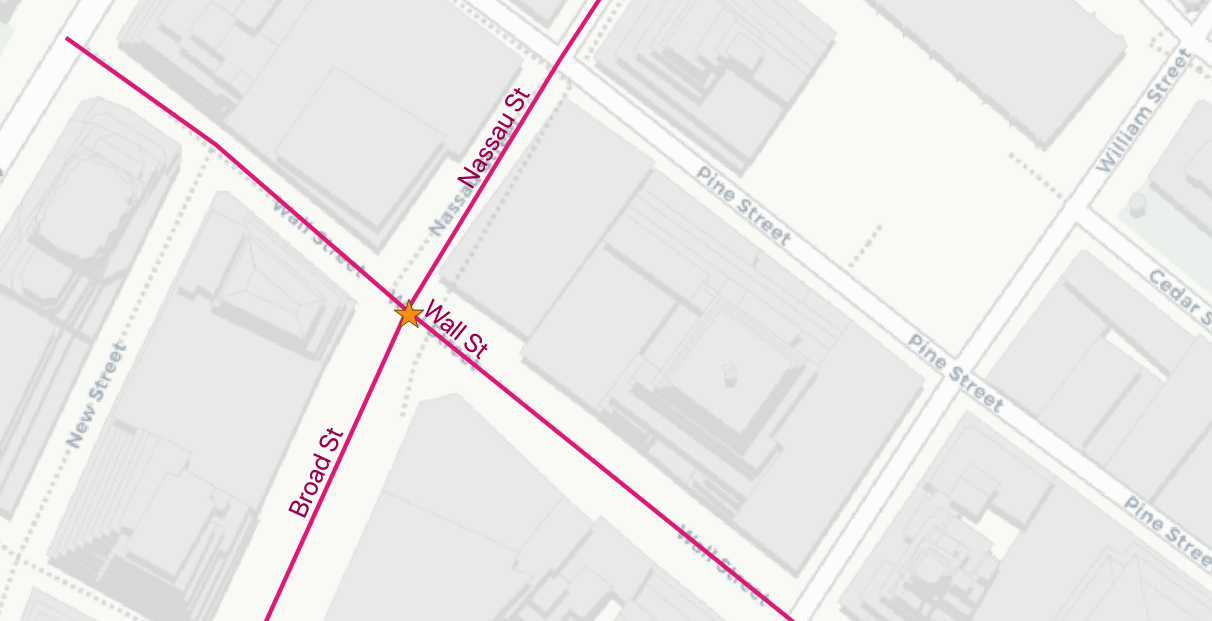
Ось 3 найближчі вулиці до станції метро «Broad St»:
-- Get the geometry of Broad St
SELECT ST_AsEWKT(geom, 1)
FROM nyc_subway_stations
WHERE name = 'Broad St';
SRID=26918;POINT(583571.9 4506714.3)
-- Plug the geometry into a nearest-neighbor query
SELECT streets.gid, streets.name,
ST_Transform(streets.geom, 4326),
streets.geom <-> 'SRID=26918;POINT(583571.9 4506714.3)'::geometry AS dist
FROM
nyc_streets streets
ORDER BY
dist
LIMIT 3;
gid | name | dist
-------+-----------+--------------------
17385 | Wall St | 0.749987508809928
17390 | Broad St | 0.8836306235191059
17436 | Nassau St | 1.3368280241070414
Як ми можемо бути впевнені, що отримуємо запит з індексом? Варто перевірити вихідні дані EXPLAIN для запиту найближчого сусіда, оскільки можна отримати правильні відповіді з неіндексованого SQL, а відсутність індексу може бути непомітною, доки розмір таблиць не збільшиться.
Це вивід команди EXPLAIN, зверніть увагу на сканування індексу під час виконання операції сортування (order by):
QUERY PLAN
---------------------------------------------------------------------------------
Limit (cost=0.28..79.58 rows=3 width=31)
-> Index Scan using nyc_streets_geom_idx on nyc_streets streets
(cost=0.28..504685.12 rows=19091 width=31)
Order By:
(geom <-> '0101000020266900000EEBD4CF27CF2141BC17D69516315141'::geometry)
29.2. З’єднання найближчих сусідів¶
Оператор сортування з підтримкою індексу має один суттєвий недолік: він працює лише з одним геометричним літералом з одного боку оператора. Це підходить для пошуку об’єктів, найближчих до одного запитного об’єкта, але не допомагає для просторового з’єднання, де мета — знайти найближчого сусіда для кожного об’єкта з повного набору кандидатів.
На щастя, у мові SQL є можливість виконувати запит багаторазово в циклі — це LATERAL join <https://medium.com/kkempin/postgresqls-lateral-join-bfd6bd0199df>_.
Тут ми знайдемо найближчу вулицю до кожної станції метро:
SELECT subways.gid AS subway_gid,
subways.name AS subway,
streets.name AS street,
streets.gid AS street_gid,
streets.geom::geometry(MultiLinestring, 26918) AS street_geom,
streets.dist
FROM nyc_subway_stations subways
CROSS JOIN LATERAL (
SELECT streets.name, streets.geom, streets.gid, streets.geom <-> subways.geom AS dist
FROM nyc_streets AS streets
ORDER BY dist
LIMIT 1
) streets;
Зверніть увагу, що CROSS JOIN LATERAL працює як внутрішня частина циклу, керованого таблицею метро. Кожен запис із таблиці метро по черзі передається в латеральний підзапит, тож ви отримуєте найближчий результат для кожного запису метро.
План виконання показує цикл по станціях метро та сортування з підтримкою індексу всередині циклу, саме там, де це потрібно:
QUERY PLAN
-------------------------------------------------------------------------
Nested Loop (cost=0.28..13140.71 rows=491 width=37)
-> Seq Scan on nyc_subway_stations subways
(cost=0.00..15.91 rows=491 width=46)
-> Limit
(cost=0.28..1.71 rows=1 width=170)
-> Index Scan using nyc_streets_geom_idx on nyc_streets streets
(cost=0.28..27410.12 rows=19091 width=170)
Order By: (geom <-> subways.geom)
