27. Кластеризація індексів¶
Бази даних можуть отримувати інформацію лише так швидко, як швидко вони можуть зчитувати її з диска. Невеликі бази даних повністю поміщаються в кеш оперативної пам’яті (RAM) і таким чином обходять обмеження фізичного диска, але для великих баз даних доступ до фізичного диска стає вузьким місцем у швидкості доступу до даних.
Дані записуються на диск за можливістю, тому немає обов’язкової кореляції між порядком зберігання даних на диску і тим, як вони будуть доступні або організовані в додатках.
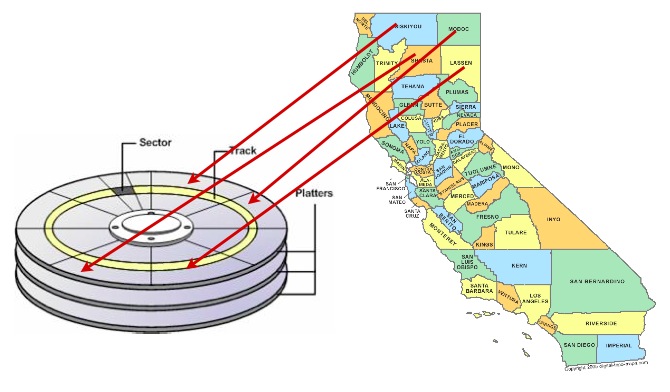
Один зі способів прискорити доступ до даних — гарантувати, що записи, які, ймовірно, будуть отримані разом у одному наборі результатів, розташовані у схожих фізичних місцях на пластинах жорсткого диска. Це називається «кластеризацією».
Вибір правильної схеми кластеризації може бути складним, але існує загальне правило: індекси визначають природний порядок даних, який схожий на патерн доступу, що буде використовуватись для отримання даних.
Через це впорядкування даних на диску в тому ж порядку, що й індекс, може в деяких випадках забезпечити прискорення роботи.
27.1. Кластеризація на основі R-Tree¶
Просторові дані зазвичай отримують доступ у просторово корельованих вікнах: уявіть собі вікно карти у веб або настільному додатку. Всі дані у вікні мають схожі координати (інакше вони б не були у цьому вікні!)
Отже, кластеризація на основі просторового індексу має сенс для просторових даних, які будуть доступні через просторові запити: схожі об’єкти зазвичай розташовані близько один до одного.
Давайте виконаємо кластеризацію таблиці ``nyc_census_blocks ``на основі їх просторового індексу:
-- Cluster the blocks based on their spatial index
CLUSTER nyc_census_blocks USING nyc_census_blocks_geom_idx;
Ця команда переписує таблицю nyc_census_blocks у порядку, визначеному просторовим індексом nyc_census_blocks_geom_gist. Чи відчуєте ви різницю у швидкості? Можливо, ні, бо початкові дані могли вже мати певне просторове впорядкування (це не рідкість у наборах даних GIS).
27.2. Диск проти ОЗП/SSD¶
Більшість сучасних баз даних працюють на SSD-накопичувачах, які значно швидші при випадковому доступі, ніж старі магнітні диски з обертанням. Також більшість сучасних баз даних працюють із даними, які достатньо малі, щоб поміститися в оперативну пам’ять сервера бази даних, і в кінцевому результаті там опиняються завдяки кешуванню віртуальної файлової системи операційної системи.
Чи кластеризація все ще потрібна?
Surprisingly, yes. Keeping records that are «near each other» in space «near each other» in memory increases the odds that related records will move up the servers «memory cache hierarchy» together, and thus make memory accesses faster.
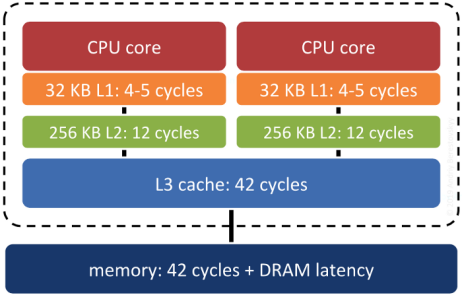
System RAM is not the fastest memory on a modern computer. There are several levels of cache between system RAM and the actual CPU, and the underlying operating system and processor will move data up and down the cache hierarchy in blocks. If the block getting moved up happens to include the piece of data the system will need next… that’s a big win. Correlating the memory structure with the spatial structure is a way in increase the odds of that win happening.
27.3. Чи має значення структура індексу?¶
Теоретично — так. Насправді ж — не дуже. Поки індекс є «досить хорошим» просторовим поділом даних, основним чинником продуктивності буде порядок розташування рядків у таблиці.
Різниця між «відсутністю індексу» і «наявністю індексу» зазвичай величезна та легко вимірювана. Різниця між «посереднім індексом» і «відмінним індексом» зазвичай потребує дуже ретельного вимірювання і може сильно залежати від навантаження, яке тестується.
