22. その他の空間結合¶
前のセクションで、ST_Centroid(geometry) 関数と ST_Union([geometry]) 関数と、簡単な例を見ました。このセクションでは、より複雑なことを行います。
22.1. 国勢統計区テーブルの作成¶
ワークショップ内の \data\ ディレクトリは、属性データを含みますがジオメトリを持たないファイル nyc_census_sociodata.sql です。このテーブルはニューヨークの社会経済的なデータである通勤時間、収入、学歴を持ちます。一つだけ問題があります。データは "census tract" (国勢調査統計区) ごとに集約されていて国勢調査統計区の空間データはありません!
このセクションでは次のことを行います
nyc_census_sociodata.sqlテーブルのロード国勢統計区の空間テーブルの生成
空間データへの属性データの結合
新しいデータを使った分析の実行
22.1.1. nyc_census_sociodata.sql のロード¶
pgAdmin の SQLクエリ ウィンドウを開きます
メニューから File->Open を選択し、
nyc_census_sociodata.sqlファイルを指定します"Run Query" ボタンを押します
pgAdmin の "Refresh"ボタン を押すと、テーブルの一覧に
nyc_census_sociodataテーブルが入るようになります
22.1.2. 国勢統計区テーブルの作成¶
前のセクションで見たように "blkid" キーの部分文字列で要約することで、国勢調査細分区から、より高いレベルのジオメトリを構築することができます。国勢統計区を取得するために、"blkid" の最初の11文字によってグループ化を要約する必要があります。
360610001001001 = 36 061 000100 1 001
36 = State of New York
061 = New York County (Manhattan)
000100 = Census Tract
1 = Census Block Group
001 = Census Block
ST_Union 集約関数を使った新テーブルの生成:
-- Make the tracts table
CREATE TABLE nyc_census_tract_geoms AS
SELECT
ST_Union(geom) AS geom,
SubStr(blkid,1,11) AS tractid
FROM nyc_census_blocks
GROUP BY tractid;
-- Index the tractid
CREATE INDEX nyc_census_tract_geoms_tractid_idx
ON nyc_census_tract_geoms (tractid);
22.1.3. 属性データの空間データへの結合¶
国勢調査統計区ジオメトリのテーブルを国勢調査統計区属性データのテーブルに、標準属性結合を使って、結合します
-- Make the tracts table
CREATE TABLE nyc_census_tracts AS
SELECT
g.geom,
a.*
FROM nyc_census_tract_geoms g
JOIN nyc_census_sociodata a
ON g.tractid = a.tractid;
-- Index the geometries
CREATE INDEX nyc_census_tract_gidx
ON nyc_census_tracts USING GIST (geom);
22.1.4. 興味深い質問に答える¶
興味深い質問に答えて下さい! 「大学院の学位を持つ人の数が多い地区の上位10件までのリストを作成して下さい」
SELECT
100.0 * Sum(t.edu_graduate_dipl) / Sum(t.edu_total) AS graduate_pct,
n.name, n.boroname
FROM nyc_neighborhoods n
JOIN nyc_census_tracts t
ON ST_Intersects(n.geom, t.geom)
WHERE t.edu_total > 0
GROUP BY n.name, n.boroname
ORDER BY graduate_pct DESC
LIMIT 10;
欲しい統計データを合計して、最後にそれらを分割します。0 で割らないようにするため、人口が 0 の統計区を取り込みません。
graduate_pct | name | boroname
--------------+-------------------+-----------
47.6 | Carnegie Hill | Manhattan
42.2 | Upper West Side | Manhattan
41.1 | Battery Park | Manhattan
39.6 | Flatbush | Brooklyn
39.3 | Tribeca | Manhattan
39.2 | North Sutton Area | Manhattan
38.7 | Greenwich Village | Manhattan
38.6 | Upper East Side | Manhattan
37.9 | Murray Hill | Manhattan
37.4 | Central Park | Manhattan
注釈
ニューヨークの地理学者は、この高学歴の地区のリストに「フラットブッシュ」があることに疑問を抱きます。答については次のセクションで検討します。
22.2. ポリゴン/ポリゴン結合¶
興味深いクエリ (興味深い質問に答える 内) の中で、地区ごとの集約をどの国勢調査統計区ポリゴンに含ませるかを決めるために ST_Intersects(geometry_a, geometry_b) 関数を使いました。次の質問に繋がります: 地区が二つの町の境界線上にある場合にはどうなりますか? 両方にインタセクトするため、**両方**の統計値に含んでしまいます。
この種の二重カウントを避けるには二つの方法があります:
単純な方法として、それぞれの統計区を**一つの**集約領域だけに収まるようにします (ST_Centroid(geometry) を使います)
複雑な方法として、境界でクロスする統計区を分割します (ST_Intersection(geometry,geometry) を使います)
大学院教育のクエリで二重カウントを回避する単純な手法を使う例を示します:
SELECT
100.0 * Sum(t.edu_graduate_dipl) / Sum(t.edu_total) AS graduate_pct,
n.name, n.boroname
FROM nyc_neighborhoods n
JOIN nyc_census_tracts t
ON ST_Contains(n.geom, ST_Centroid(t.geom))
WHERE t.edu_total > 0
GROUP BY n.name, n.boroname
ORDER BY graduate_pct DESC
LIMIT 10;
このクエリは時間がかかります。というのも、ST_Centroid 関数を全ての統計区について実行しなければならないからです。
graduate_pct | name | boroname
--------------+---------------------+-----------
48.0 | Carnegie Hill | Manhattan
44.2 | Morningside Heights | Manhattan
42.1 | Greenwich Village | Manhattan
42.0 | Upper West Side | Manhattan
41.4 | Tribeca | Manhattan
40.7 | Battery Park | Manhattan
39.5 | Upper East Side | Manhattan
39.3 | North Sutton Area | Manhattan
37.4 | Cobble Hill | Brooklyn
37.4 | Murray Hill | Manhattan
二重カウントを回避すると結果が変わります!
22.2.1. Flatbush はどうでしょう?¶
特にフラットブッシュ地区はリストから外れました。テーブル内のフラットブッシュ地区の地図を詳しく見ると理由が分かります。
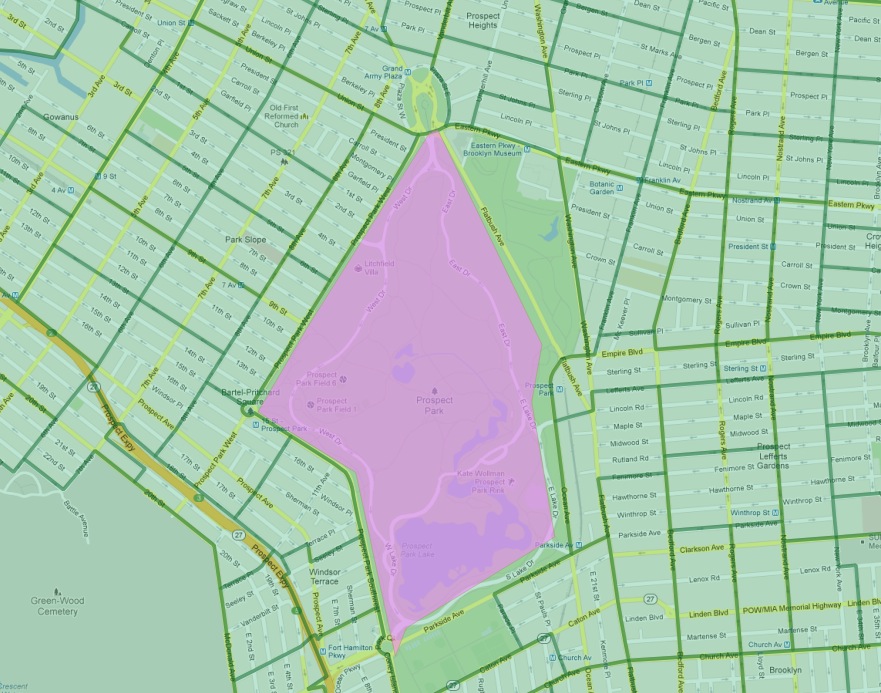
データソースで定義されている通り、プロスペクト公園だけしかないので、従来の意味ではフラットブッシュは本当の地区とは言えません。この領域における国勢調査統計区は、当然のことですが、住民は 0 です。しかし、地区境界は公園の北側に隣接する高級な国勢調査統計区の一つ (高級になったパークスロープ) を削ります。ポリゴン/ポリゴンテストを使用すると、この一つの統計区が空っぽのフラットブッシュに追加され、非常に高いスコアになりました。
22.3. 大きな半径距離の結合¶
「地下鉄駅近く (500m以内) の人と、そうでない人との通勤時間がどれぐらい違うか?」と聞いてみたいですね。
しかしながら、この質問は、複数の地下鉄駅の 500m 圏内に入る人が多数出るという、二重カウントの問題に行き当たります。ニューヨークの人口を比較します:
SELECT Sum(popn_total)
FROM nyc_census_blocks;
8175032
ニューヨーク市内の、地下鉄駅から 500m 圏内にいる人の人口は、次の通りです:
SELECT Sum(popn_total)
FROM nyc_census_blocks census
JOIN nyc_subway_stations subway
ON ST_DWithin(census.geom, subway.geom, 500);
10855873
地下鉄に近い人の人口が、全体の人口を超えてしまっています! 明らかに、この単純な SQL では、大きな二重カウントのエラーを犯しています。バッファリングされた地下鉄の図を見ると、問題点が分かってきます。
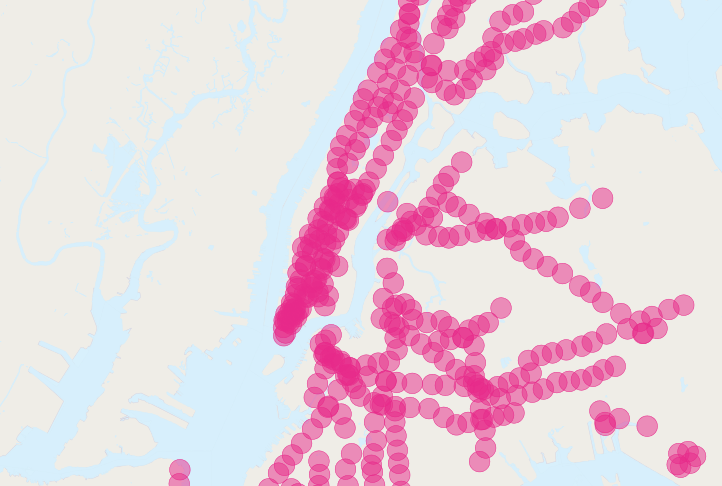
クエリの集約部分に渡す前に、重複しない統計調査細分区だけを持つようにすることで解決できます。クエリを、重複しない細分区を探すサブクエリと、答を返す集約クエリにくるまれたサブクエリとに分割することで、実現できます:
WITH distinct_blocks AS (
SELECT DISTINCT ON (blkid) popn_total
FROM nyc_census_blocks census
JOIN nyc_subway_stations subway
ON ST_DWithin(census.geom, subway.geom, 500)
)
SELECT Sum(popn_total)
FROM distinct_blocks;
5005743
この方がいいです! 地下鉄駅から 500m 圏内 (徒歩約 5-7 分) の人口はニューヨーク市の半分です。
