15. 空間インデックス¶
空間インデックスは空間データベースの主要3機能の一つであることを思い出して下さい。インデックスによって、空間データベースで大きなデータ集合を使えるようになります。インデックスなしでは、地物の検索に、データベースのレコードの全てを「シーケンシャルスキャン」で検索する必要があります。インデックスによって、データを検索木に整理して、特定のレコードを素早く検索できるようにできるので、検索速度が向上します。
空間インデックスは、PostGIS の最大の財産の一つです。かつての例では、空間結合を構築するには、テーブル全体の各レコードを互いに比較していく必要がありました。これは非常にコストがかかります。10,000レコードのテーブルが二つあって、インデックス無しで計算しようとすると 100,000,000 回の比較が必要となります。対してインデックスでは 20,000 回まで下がる可能性があります。
データロードファイルには、全てのテーブルに対する空間インデックスが既に含まれているので、インデックスの効果を示すには、まずインデックスを削除する必要があります。
nyc_census_blocks テーブル上で空間インデックス**なしで**クエリを実行してみましょう。
最初に、インデックスを**削除します**。
DROP INDEX nyc_census_blocks_geom_idx;
注釈
DROP INDEX 文で、既存のインデックスをデータベースシステムから削除します。詳細については、PostgreSQLの 文書 をご覧下さい。
pgAdmin のクエリウィンドウの右下隅にある "Timing" メーターを見て、次を実行して下さい。クエリは、"B" で始まる地下鉄駅を含む街区を特定するために、統計調査街区を一つ一つ探索していきます。
SELECT count(blocks.blkid)
FROM nyc_census_blocks blocks
JOIN nyc_subway_stations subways
ON ST_Contains(blocks.geom, subways.geom)
WHERE subways.name LIKE 'B%';
count
---------------
46
nyc_census_blocks テーブルは非常に小さい (数千レコードのみ) ので、インデックス無しでも、クエリは、こちらのコンピュータ上では、 300ミリ秒 しかかかりませんでした。
空間インデックスを追加しなおして、クエリをもう一度実行します。
CREATE INDEX nyc_census_blocks_geom_idx
ON nyc_census_blocks
USING GIST (geom);
注釈
"USING GiST" 句で、PostgreSQLに、インデックス作成時に汎用インデックス構造 (Generic Index STructure) を使うように指示を出しています。インデックス作成時に``ERROR: index row requires 11340 bytes, maximum size is 8191`` のようなエラーを受け取った場合には、"USING GiST" 句の追加を怠った可能性があります。
こちらのコンピュータでは 50ミリ秒 に低下します。より大きなテーブルでは、インデックス付きのクエリの相対的な速度向上が、より大きくなります。
15.1. どのように空間インデックスが動作するか¶
標準のデータベースインデックスは、インデックス化されるカラムの値に基づいて階層ツリーを生成します。空間インデックスは少し違います。ジオメトリの地物自体のインデックス化することができず、代わりに地物のバウンディングボックスについてインデックス化します。
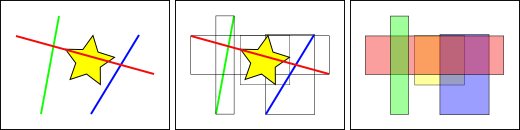
上の図では、黄色の星とインタセクトするラインの数は、赤いラインの**一つ**です。しかし、黄色のボックスとインタセクトする地物のバウンディングボックスは、赤いラインと青いラインの**二つ**です。
「どのラインが黄色い星とインタセクトするか」という質問にデータベースが効率的に答える方法は、最初にインデックスを使って (非常に速いです) 「どのボックスが黄色いボックスとインタセクトするのか」という質問に答え、その後に、「どのラインが黄色い星とインタセクトするか」の確実な計算を、**最初のテストによって返された地物だけについて**行います。
大きなテーブルでは、近似的なインデックスの評価を行ってから、確実なテストを実行する「二つの関門」システムによって、クエリの答を得るのに必要な計算量を大幅に減らすことができます。
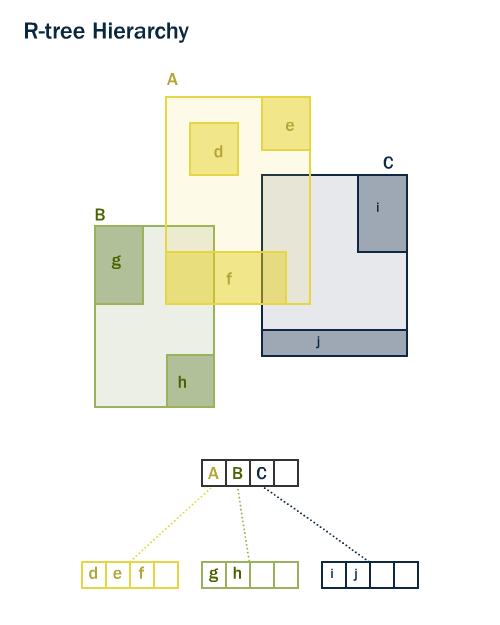
PostGIS と Oracle Spatial は、どちらも「R木」[#RTree]_ 空間インデックス構造を持っています。R木はデータを長方形に分割し、さらに小さな長方形に分割し、さらに文化地していきます。可変データ密度、オブジェクトの異なるオーバラップ量、オブジェクトサイズを自動的に処理する自己調整インデックス構造です。
15.2. 空間インデックス関数¶
空間インデックスが有効な時に自動的に空間インデックスを使用する関数は一部だけです。
最初の4関数はクエリで最も一般的に使われます。ST_DWithin は、インデックスからパフォーマンスを向上させつつ「距離内」「半径内」を求めるクエリにおいて非常に重要です。
このリストに無い関数 (ST_Relate が最も一般的です) へのインデックスによる高速化機能を追加するには、インデックスのみの句を追加します。下のようにします。
15.3. インデックスだけのクエリ¶
PostGIS で一般的に使用される関数の多く (ST_Contains, ST_Intersects, ST_DWithin, etc) は、インデックスフィルタを自動的に実行します。しかし、インデックスフィルタを実行しない関数もあります (例 ST_Relate)。
インデックスを使った (かつフィルタリングなしの) バウンディングボックス検索を実行するには、&& 演算子を使います。ジオメトリでは = 演算子が「同じ値である」を意味するのと同じように、&& 演算子は「バウンディングボックスがオーバラップするか接触している」を意味します。
West Village`の人口について、インデックスのみのクエリと正確なクエリとを比較してみましょう。:command:`&& を使ったインデックスのみのクエリは次のように見えます:
SELECT Sum(popn_total)
FROM nyc_neighborhoods neighborhoods
JOIN nyc_census_blocks blocks
ON neighborhoods.geom && blocks.geom
WHERE neighborhoods.name = 'West Village';
49821
同じクエリで、より確実な ST_Intersects 関数を使ってみましょう。
SELECT Sum(popn_total)
FROM nyc_neighborhoods neighborhoods
JOIN nyc_census_blocks blocks
ON ST_Intersects(neighborhoods.geom, blocks.geom)
WHERE neighborhoods.name = 'West Village';
26718
より少ない答になりました。一つ目のクエリでは、地区のバウンディングボックスが隣の地区のバウンディングボックスとインタセクトする地区について合計しましたが、二つ目のクエリでは、地区が隣の地区とインタセクトする地区のみについて合計しました。
15.4. 分析¶
PostgreSQL クエリプランナは、クエリの評価にインデックスを使うべきか使わないべきかをインテリジェントに選択します。直感に反して、インデックス検索は必ず速くなるわけではありません。検索がテーブルのすべてのレコードを返そうとしたり、レコードごとの取得でインデックス木を横断するような場合には、はじめからテーブル全体をシーケンシャルスキャンするよりも実際には遅くなる場合があります。
クエリ矩形のサイズを知るだけでは、クエリが多数または少数のレコードを返すかとうかを知るには十分ではありません。次に示す図で、赤の四角形は小さいですが、青の四角形より多くのレコードを返します。
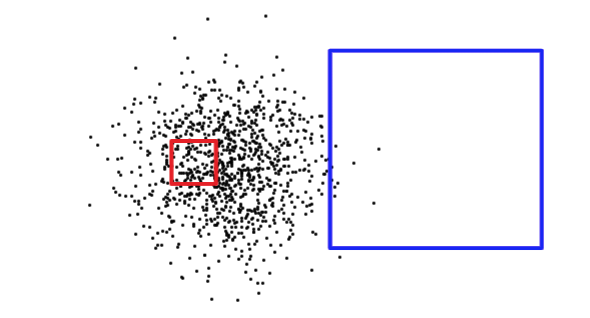
どの状況を取り扱うのか (テーブルの小さい部分を読むか、大きい部分を読むか)を算定するために、PostgreSQLは、インデックスの付けられたカラムごとに、データの分散に関する統計情報を保持します。デフォルトでは、PostgreSQLは定期的に統計情報を収集します。しかしながら、短期間にテーブルの中身が劇的に変化する時には、統計情報は更新されません。
統計情報がテーブル内容と合致するようにするために、一括データ読み込みや一括削除の後に"ANALYZE"コマンドを実行するのが賢明です。これにより、統計情報システムが全てのインデックス付きカラムのデータを収集するよう強制されます。
"ANALYZE"コマンドはPostgreSQLにテーブルを横断して、クエリプランの推定に使われる内部の統計情報を更新するよう求めます (クエリプランの解析については後で議論します)。
ANALYZE nyc_census_blocks;
15.5. VACUUMの実行¶
インデックスを作るだけではPostgreQLがインデックスを効果的に使えるようになるには十分ではないことは、強調すべきところです。VACUUM実行には、いつでも膨大なUPDATE、INSERT、DELETEがテーブルに対して発行する必要があります。"VACUUM"コマンドはPostgreSQLに、テーブルページ内にあある、UPDATEやDELETEによって放置されて使っていない領域を取り戻すよう求めます。
VACUUM実行は効率的なデータベースの実行に非常に重要ですので、PostgreSQLはデフォルトで「自動VACUUM」機能を提供しています。
自動VACUUMは、活動水準によって決定される適切な時間間隔で、テーブル上でVACUUM (領域回復)と分析 (統計情報の更新)の両方を行います。これがトランザクションの多いデータベースには不可欠ですが、インデックス追加やデータの一括読み込みの後に実行される自動VACUUMを待つのはお勧めしません。大規模なバッチ更新が実行されたときはいつでも、"VACUUM"の手動実行を行うべきです。
VACUUM実行とデータベースの分析は、必要に応じて個別に実行できます。"VACUUM"コマンドの発行では、データベースの統計情報は更新されません。同様に、"ANALYZE"コマンドの発行では未使用の領域が回復されません。両方のコマンドはデータベース全体、単一のテーブル、または単一のカラムに対して実行できます。
VACUUM ANALYZE nyc_census_blocks;
15.6. 関数リスト¶
geometry_a && geometry_b: AのバウンディングボックスとBのバウンディングボックスがオーバラップする場合にはTRUEを返します。
geometry_a = geometry_b: PostGIS 2.4より前では、AのバウンディングボックスとBのバウンディングボックスと同じ場合にはTRUEを返します。2.4以降では、AのジオメトリがBと同じ場合にのみTRUEを返します。
geometry_a = geometry_b: AのバウンディングボックスとBのバウンディングボックスと等価である場合にはTRUEを返します。
ST_Intersects(geometry_a, geometry_b): ジオメトリ/ジオグラフィが「空間的にインタセクトする」 - (空間の任意部分を共有する)場合にはTRUEを返し、そうでない(接続されていない、Disjoint)場合にはFALSEを返します。
脚注
