27. インデックスでのクラスタリング¶
データベースの情報取得速度はディスクからの情報取得速度と同じです。小さいデータベースは RAM キャッシュに全体を入れて、物理ディスクの制約から自由になりますが、大きなデータベースでは、物理ディスクへのアクセスがディスクアクセス速度に制限をかけることになります。
データは都合のいいようにディスクに書き込まれます。ディスクに格納されているデータの並び順と、アプリケーションによるアクセスや整理の方法との関係は、重要ではありません。
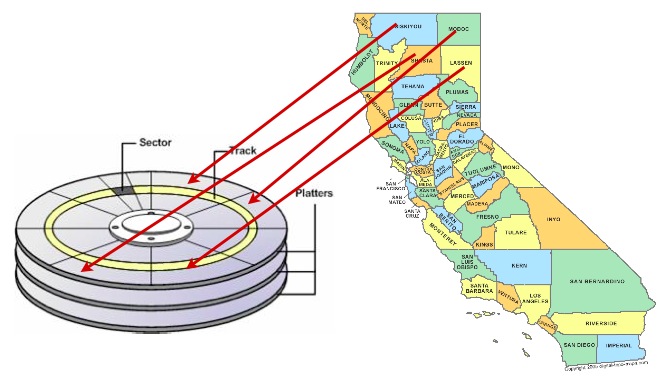
データアクセス速度向上の一つの方法に、同じ結果集合を得る際に一緒に取得されそうなレコードを、ハードディスクの円盤上で物理的に近い位置に置くというのがあります。これは「クラスタリング」と呼ばれます。
正しいクラスタリングの枠組みは扱いにくいこともありますが、一般的な規則が適用します:インデックスは、データの取得に使われるアクセスパターンに似た、自然なデータ並び順の枠組みを定義します。
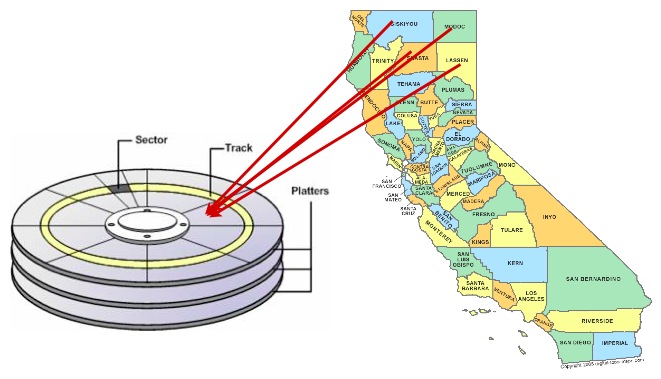
このため、ディスク上のデータの並べ替えをインデックスと同じにすると、速度が向上する場合があります。
27.1. R木でのクラスタリング¶
空間データは空間的に相関するウィンドウ内でアクセスされる傾向にあります。ウェブやデスクトップのアプリケーションにおける地図のウィンドウを考えてみて下さい。ウィンドウ内のデータの全ては、位置を示す値としては似ています (似ていないならウィンドウ内にありません!)
空間インデックスに基づくクラスタリングは、空間クエリがアクセスする空間データにとって理にかなっています。似た物は似た位置を持ちます。
空間インデックスに基づく nyc_census_blocks のクラスタリングを行いましょう:
-- Cluster the blocks based on their spatial index
CLUSTER nyc_census_blocks USING nyc_census_blocks_geom_idx;
コマンドは、nyc_census_blocks を、空間インデックス nyc_census_blocks_geom_gist で定義される並び順に書き換えます。速度差が感じられるでしょうか? 感じられないかも知れません。元のデータは既に既存の空間の並び順を持っていたからかも知れないからです (GISデータセットで珍しいことではありません)。
27.2. ディスク対メモリ/SSD¶
最近のデータベースの多くは SSD ストレージを使っています。ランダムアクセスにおいては、古い回転磁性体よりもずっと早いです。最近のデータベースの多くは、データベースサーバの RAM に収まるぐらい十分に小さいデータ上で実行されていて、オペレーティングシステムの仮想ファイルシステムがデータをキャッシュするにつれて、そこに落ち着きます。
クラスタリングはなお重要なのでしょうか?
Surprisingly, yes. Keeping records that are "near each other" in space "near each other" in memory increases the odds that related records will move up the servers "memory cache hierarchy" together, and thus make memory accesses faster.

System RAM is not the fastest memory on a modern computer. There are several levels of cache between system RAM and the actual CPU, and the underlying operating system and processor will move data up and down the cache hierarchy in blocks. If the block getting moved up happens to include the piece of data the system will need next... that's a big win. Correlating the memory structure with the spatial structure is a way in increase the odds of that win happening.
27.3. インデックス構造は重要ですか?¶
理論的には、そうです。実際には、そうではありません。インデックスが「かなり良い」空間分解であるなら、パフォーマンスを決める主な要因はテーブルのタプルの順序になります。
「インデックスなし」と「インデックスあり」との間の違いは、一般的には大きく、計測は問題なく可能です。「平凡なインデックス」と「素晴らしいインデックス」との差では、見定めるのには非常に慎重な測定が必要で、この差は、テストしている仕事量に対して非常に敏感になることがあります。
