38. PostgreSQLのバックアップとレストア¶
PostgreSQLデータベースのバックアップの方法が多数あり、どれを選ぶかはデータベースをどう使うかに大きく依存しています。
比較的静的なデータベースでは、基本的に、定期的なデータのスナップショットを取るのに pg_dump/pg_restore ツールが使えます。
データが頻繁に変更される場合には、「オンラインバックアップ」の枠組みを使います。更新の継続的なアーカイブを安全な場所に保存できます。
オンラインバックアップは、特に PostgreSQL 9.0 以上では `高可用性<http://www.postgresql.org/docs/current/static/high-availability.html>`_ のレプリケーションと待機システムの基礎となります。
38.1. データのレイアウト¶
PostgreSQL スキーマ で説明した通り、生成データが常に分割されたスキーマに格納されているようにすることが、データ管理において非常に重要な ベストプラクティス となります。次に二つの理由を示します:
個々にバックアップする場合ではテーブルの一覧の管理を行いますが、スキーマ内のデータのバックアップとレストアの方がずっと単純です。
データテーブルを "public" スキーマから除外することで、ソフトウェアアップグレード で説明している通り、ずっと簡単なアップグレードが可能になります。
38.2. 基本的なバックアップとレストア¶
データベースの全体のバックアップは pg_dump ユーティリティを使うと簡単です。このユーティリティはコマンドラインツールなので、スクリプトで自動化がやりやすいです。また、pgAdminユーティリティないのGUIを介して実行することもできます。
``nyc``データベースのバックアップにGUIを使います。バックアップを取りたいデータベースを右クリックします:
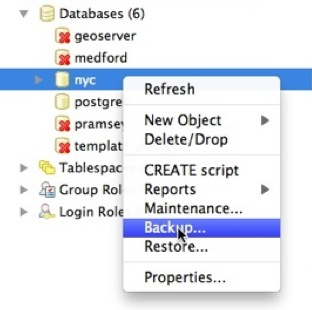
生成したバックアップファイルのファイル名を入力します。

バックアップフォーマットには、copress、tar、plainの三つの選択肢があります。
Plain は、単なる文字のSQLファイルです。これは最も単純なフォーマットです。また、簡単に編集、変更してデータベースに戻すことができ、所有者や他のグローバル情報といったもののオフラインで変更できるので、最も柔軟です。
Tar は UNIX アーカイブのフォーマットを使って、別々のファイルにダンプのコンポーネントを保持します。tar フォーマットでは、pg_restore ユーティリティを使ってダンプの一部を選択して格納することができます。
Compress は tar フォーマットのようなものですが、内部のコンポーネントを個別に圧縮しています。アーカイブ全体を復元せずに選択したものだけを格納することができます。
バックアップファイルを保存する時には Compress オプションにチェックを入れてから行います。
コマンドラインでの同じ操作は次のようになります:
pg_dump --file=nyc.backup --format=c --port=54321 --username=postgres nyc
バックアップファイルは Compress 書式なので、マニフェストの一覧を表示する pg_restore コマンドを使ってコンテンツを見ることができます。pgAdmin GUI では、パネルで "View" が任意選択できます。
マニフェストを見るとき、多数の "FUNCTION" があることに気づくかもしれません。

pg_dump ユーティリティは、データベースの 簡単な 非システムオブジェクトをダンプするので、PostGIS関数の定義を含むことになります。
注釈
PostgreSQL 9.1以上では "EXTENSION" 機能があり、PostGISのようなパッケージをシステムコンポーネントに登録したうえで追加できるので、pg_dump 出力から除かれます。PostGIS 2.0以上では、エクステンションシステムを使ったインストールに対応しています。
同じマニフェストをコマンドラインから pg_restore を使って直接得ることができます:
pg_restore --list nyc.backup
PostGIS関数のシグネチャが多数あるダンプファイルは、データだけが欲しくてシステム関数は不要ですので、問題があります。
あらゆるオブジェクトはダンプファイル内にあるため、データの無いデータベースのレストアを行おうとしても、全ての機能が得られます。そうすることで、レストアしようとしているシステムが、ダンプ元のものと確実に同じバージョンのPostGISを持っていることが期待されます (関数シグネチャ定義は特定のバーうじょんのPostGISの共有ライブラリを参照しているためです)。
コマンドラインからレストアは次のように見えます:
createdb --port 54321 nyc2
pg_restore --dbname=nyc2 --port 54321 --username=postgres nyc.backup
関数シグネチャが無いデータだけのダンプは、スキーマ内のデータを保持するもので、便利です。特定のスキーマだけをダンプするコマンドラインのフラグがあるからです。次のようにします:
pg_dump --port=54321 -format=c --schema=census --file=census.backup
ダンプのコンテント一覧を表示すると求めるデータテーブルだけを見ることができます:
pg_restore --list census.backup
;
; Archive created at Thu Aug 9 11:02:49 2012
; dbname: nyc
; TOC Entries: 11
; Compression: -1
; Dump Version: 1.11-0
; Format: CUSTOM
; Integer: 4 bytes
; Offset: 8 bytes
; Dumped from database version: 8.4.9
; Dumped by pg_dump version: 8.4.9
;
;
; Selected TOC Entries:
;
6; 2615 20091 SCHEMA - census postgres
146; 1259 19845 TABLE census nyc_census_blocks postgres
145; 1259 19843 SEQUENCE census nyc_census_blocks_gid_seq postgres
2691; 0 0 SEQUENCE OWNED BY census nyc_census_blocks_gid_seq postgres
2692; 0 0 SEQUENCE SET census nyc_census_blocks_gid_seq postgres
2681; 2604 19848 DEFAULT census gid postgres
2688; 0 19845 TABLE DATA census nyc_census_blocks postgres
2686; 2606 19853 CONSTRAINT census nyc_census_blocks_pkey postgres
2687; 1259 20078 INDEX census nyc_census_blocks_geom_gist postgres
データテーブルだけを持つのは ソフトウェアアップグレード で言及しているように、どのバージョンの PostGIS であってもデータベースに格納できるので、便利です。
38.2.1. ユーザーのバックアップ¶
pg_dump ユーティリティは、データベースを一度に (あるいは、制限した場合にはスキーマやテーブルを一度に) 操作します。しかし、ユーザまわりの情報はクラスタ全体に格納され、どのデータベースにも保存されません!
ユーザ情報をバックアップするには pg_dumpall ユーティリティを使用し "--globals-only" フラグを付けます。
pg_dumpall --globals-only --port 54321
pg_dumpall をクラスタ全体のバックアップに使うデフォルトモードも可能ですが、pg_dump を使うのと同じに PostGIS 関数シグネチャをバックアップすることになるるので、ダンプは同じソフトウェアインストール状況になっているところにレストアする必要があり、また、アップグレード処理の一部としては使えないので、ご注意下さい。
38.3. オンラインでのバックアップと格納¶
オンラインでのバックアップとレストアによって、管理者が、データベース全体のダンプを反復して行うことで発生するオーバヘッドもなく、バックアップファイルのセットの最新版を非常によく保持できます。データベースが頻繁な追加と更新の負荷がかかっている場合には、オンラインバックアップは基本的なバックアップより好ましくなることもあります。
注釈
オンラインバックアップを習得する最善の方法は、PostgreSQLマニュアルの ` 継続的アーカイブとポイントインタイムリカバリ(PITR) <https://www.postgresql.jp/document/current/html/continuous-archiving.html>`_ などのセクションを読むことです。PostGIS ワークショップでは、オンラインバックアップの簡単なスナップショットを提供します。
38.3.1. 仕組み¶
PostgreSQL は変更されると、最初は、メインデータテーブルへの継続的な書き込みでなく、"write-ahead logs" (WAL) に保存します。まとめると、これらのログはデータベースで発生した全ての変更の完全な記録です。オンラインバックアップではデータベースのメインテーブルの複写を取得し、その後に生成される個々のWALの複製を取得します。
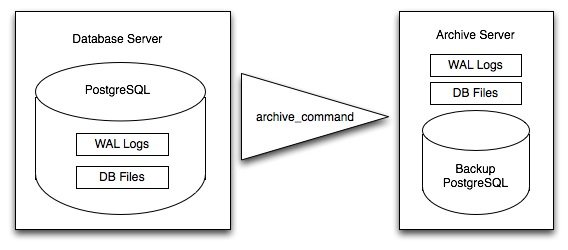
新しいデータベースへの回復を行うべき時になると、システムはメインデータの複写物から起動し、すべてのWALファイルをデータベースで実行します。最終的な結果は、最後にWALを受信した時点でのオリジナルと同じ状態の復元されたデータベースです。
WALはとにかく書き込まれていて、複写物のアーカイブサーバへの転送は計算コストが低いので、オンラインバックアップは、計算集中となる定期的なフルダンプを行わずに、システムのバックアップをごく最近のものとして維持する効果的な手段です。
38.3.2. WALファイルのアーカイブ¶
オンラインバックのセットアップで最初に行うべきことは、アーカイブ方法を作成することです。PostgreSQLアーカイブ方法は、柔軟性が非常に高いです。PostgreSQL バックエンドはコンフィギュレーションパラメータ archive_command で指定されるスクリプトを呼ぶだけです。
これはつまり、ファイルをネットワークドライブに複製するので、アーカイブは単純にすることができます。また、ファイルのリモートアーカイブへの暗号化とメール送信と同じくらいの複雑性を持ちます。ユーザがスクリプトとして書くことができる処理は全てファイルをアーカイブ化するのに使うことができます。
アーカイブを有効にする員は postgresql.conf を編集します。まず次のように WAL アーカイブを有効にします:
wal_level = archive
archive_mode = on
それから archive_command を設定して、アーカイブファイルを安全な位置 (複写先パスは必要に応じて変更します) に複写します。次のようにします:
# Unix
archive_command = 'test ! -f /archivedir/%f && cp %p /archivedir/%f'
# Windows
archive_command = 'copy "%p" "C:\\archivedir\\%f"'
アーカイブコマンドが存在するファイルの上書きを行わないようにすることが重要ですので、UNIX コマンドは、ファイルが既に存在していないか初期テストを行います。また、複写が失敗した場合にコマンドが 0 でないステータスを返すことも重要です。
変更を行ったら、PostgreSQLを再起動して、設定を有効化させることができます。
38.3.3. 基本バックアップの取得¶
アーカイブプロセスが用意できたら、基本バックアップを取る必要があります。
データベースをバックアップモードにします (クエリやデータ更新の処理の変更に関することは行わず、チェックポイントの強制とバックアップの取られた時を示すラベルファイルを書くだけです)。
SELECT pg_start_backup('/archivedir/basebackup.tgz');
ラベルの場合、バックファイルへのパスを使うのが良い方法です。バックアップが保存されている場所を追跡するのに役立つからです。
データベースをアーカイブ位置に複写します:
# Unix
tar cvfz /archivedir/basebackup.tgz ${PGDATA}
次に、バックアップ処理を完了したことをデータベースに通知します。
SELECT pg_stop_backup();
これらの手順の全ては、もちろん、定期的な基本バックアップに使うスクリプトにすることができます。
38.3.4. アーカイブからのレストア¶
これらの手順は PostgreSQL マニュアル 継続的アーカイブとポイントインタイムリカバリ(PITR) から取得しました。
サーバが動いている場合には止めます。
そのためのスペースがある場合には、クラスタデータディレクトリ全体と全てのテーブルスペースとを、後に必要になる場合のために、一時的な場所に複写します。この予防措置を行うには、既存のデータベースの二つの複写物を保持するだけの十分なフリースペースがシステム上に存在している必要があります。十分なスペースが無い場合には、少なくともクラスタの pg_xlog サブディレクトリの内容を保存すべきです。システムが落ちる前にアーカイブされなかったログを含んでいる可能性があるためです。
クラスタデータディレクトリ内とテーブルスペースのルートディレクトリ内の、全ての存在するファイルとサブディレクトリを削除します。
システムバックアップからデータベースをレストアします。正しい所有権 (データベースシステムユーザであって、root ではダメです!) を持ち、正しいパーミッションを持つようにして下さい。テーブルスペースを使用している場合には、pg_tblspc/ 内のシンボリックリンクが正しくレストアされたか確認して下さい。
pg_xlog/ 内に存在するファイルを全て削除します。このファイルはファイルシステムのバックアップから来たもので、今より前の者です。pg_xlog/ を全くアーカイブしていなかった場合には、適切な権限で再生成します。以前にシンボリックリンクで作っていた場合には、そのように再確立するように注意して下さい。
手順 2 で保存したアーカイブしていない WAL セグメントファイルがある場合にはそれらを pg_xlog/ の下に複写します。(複写が最善です。移動はよくありません。問題が発生して、やり直しになった場合でも、変更されていないファイルがまだ手元に残っているからです。)
リカバリコマンドファイル recovery.conf をクラスタデータディレクトリ (26章参照) 内に作ります。リカバリ成功が確認できるまで、一時的に pg_hba.conf を編集して、一般ユーザからの接続を防いだ方がいいかも知れません。
サーバを起動します。サーバはリカバリモードになり、必要なアーカイブ WAL ファイルが読まれます。外部エラーのためにリカバリが終わらされると、サーバは単に再起動され、リカバリが継続されます。リカバリ処理が完了すると、サーバは recovery.conf というファイル名を recovery.done に変え (誤ってリカバリモードに再び入るのを防ぐためです)、通常のデータベース操作を開始します。
求める状態へのリカバリに成功したことを確認するためにデータベースの内容を調査します。もしうまくいっていなかったら、手順 1 に戻ります。うまくいったなら、pg_hba.conf を通常に戻して、ユーザが接続できるようにします。
