29. Vecinos cercanos¶
29.1. ¿Qué es el Buscador de Vecinos Cercanos?¶
Una pregunta espacial frecuente es: «¿Cuál es la <<entidad>> más cercana a la <<entidad de consulta>>?»
A diferencia de la búsqueda por distancia, la búsqueda por «vecino más próximo» no incluye ninguna medida que restrinja la distancia a la que pueden estar las geometrías candidatas, se aceptarán características de cualquier distancia, siempre que sean las más próximas.
PostgreSQL resuelve el problema del vecino más cercano introduciendo un operador de «orden por distancia» (<->) que induce a la base de datos a utilizar un índice para acelerar un conjunto de resultados ordenado. Con un operador de «orden por distancia» en su lugar, una consulta de vecino más cercano puede devolver las «N características más cercanas» simplemente añadiendo un orden y limitando el conjunto de resultados a N entradas.
El operador «ordenar por distancia» funciona tanto para los tipos de geometría como de geografía. La única diferencia de funcionamiento entre ambos tipos es el valor de distancia devuelto. Para geometría <-> devuelve la misma respuesta que ST_Distance que depende de las unidades del sistema de referencia espacial en uso. Para geografía el valor de distancia devuelto es la distancia esférica, en lugar de la distancia esferoidal más precisa que devuelve ST_Distance(geography,geography).
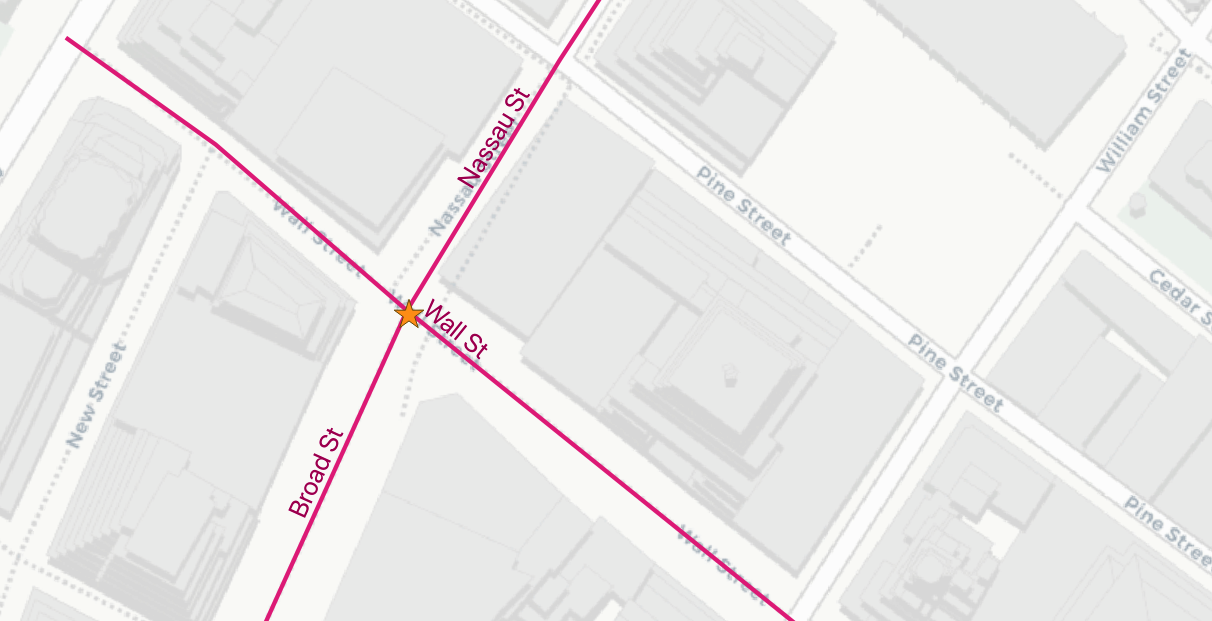
Aquí están las 3 calles más cercanas a la estación de metro “Broad St”:
-- Get the geometry of Broad St
SELECT ST_AsEWKT(geom, 1)
FROM nyc_subway_stations
WHERE name = 'Broad St';
SRID=26918;POINT(583571.9 4506714.3)
-- Plug the geometry into a nearest-neighbor query
SELECT streets.gid, streets.name,
ST_Transform(streets.geom, 4326),
streets.geom <-> 'SRID=26918;POINT(583571.9 4506714.3)'::geometry AS dist
FROM
nyc_streets streets
ORDER BY
dist
LIMIT 3;
gid | name | dist
-------+-----------+--------------------
17385 | Wall St | 0.749987508809928
17390 | Broad St | 0.8836306235191059
17436 | Nassau St | 1.3368280241070414
¿Cómo podemos estar seguros de que estamos obteniendo una consulta asistida por índices? Es una buena idea comprobar la salida de EXPLAIN para una consulta de vecino más cercano, porque es posible obtener respuestas correctas de SQL no indexado y la falta de un índice podría no ser obvia hasta que el tamaño de las tablas aumente.
Esta es la salida de EXPLAIN, observe la exploración del índice sobre el order by:
QUERY PLAN
---------------------------------------------------------------------------------
Limit (cost=0.28..79.58 rows=3 width=31)
-> Index Scan using nyc_streets_geom_idx on nyc_streets streets
(cost=0.28..504685.12 rows=19091 width=31)
Order By:
(geom <-> '0101000020266900000EEBD4CF27CF2141BC17D69516315141'::geometry)
29.2. Join Vecino más próximo¶
El operador de ordenación por índice tiene un inconveniente importante: sólo funciona con un único literal geométrico en un lado del operador. Esto está bien para encontrar los objetos más cercanos a un objeto definido, pero no ayuda para un JOIN espacial, donde el objetivo es encontrar el vecino más cercano para cada uno de los objetos de un conjunto completo de candidatos.
Afortunadamente, existe una característica del lenguaje SQL que nos permite ejecutar una consulta en un bucle: el LATERAL join.
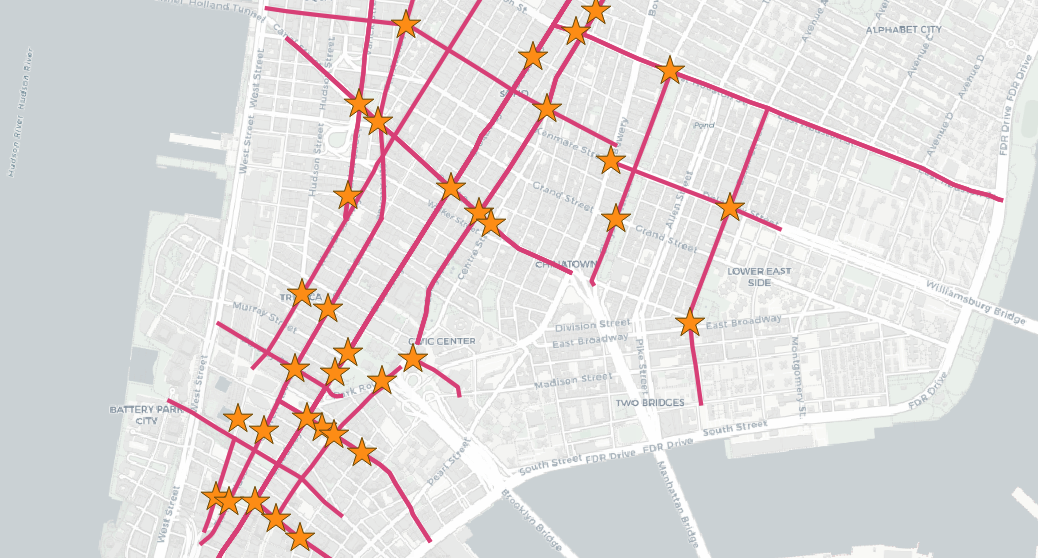
Aquí encontrará la calle más cercana a cada estación de metro:
SELECT subways.gid AS subway_gid,
subways.name AS subway,
streets.name AS street,
streets.gid AS street_gid,
streets.geom::geometry(MultiLinestring, 26918) AS street_geom,
streets.dist
FROM nyc_subway_stations subways
CROSS JOIN LATERAL (
SELECT streets.name, streets.geom, streets.gid, streets.geom <-> subways.geom AS dist
FROM nyc_streets AS streets
ORDER BY dist
LIMIT 1
) streets;
Observe cómo el CROSS JOIN LATERAL actúa como la parte interna de un bucle controlado por la tabla subways. Cada registro de la tabla subways se introduce en la subconsulta lateral, de uno en uno, de forma que se obtiene un resultado más cercano para cada registro de metro.
La explicación muestra el bucle en las estaciones de metro, y el orden asistido por índices dentro del bucle donde queramos:
QUERY PLAN
-------------------------------------------------------------------------
Nested Loop (cost=0.28..13140.71 rows=491 width=37)
-> Seq Scan on nyc_subway_stations subways
(cost=0.00..15.91 rows=491 width=46)
-> Limit
(cost=0.28..1.71 rows=1 width=170)
-> Index Scan using nyc_streets_geom_idx on nyc_streets streets
(cost=0.28..27410.12 rows=19091 width=170)
Order By: (geom <-> subways.geom)
