22. Más Joins Espaciales¶
En la última sección vimos las funciones ST_Centroid(geometría) y ST_Union([geometría]), y algunos ejemplos sencillos. En esta sección haremos algunas cosas más elaboradas con ellas.
22.1. Creación de una tabla de secciones censales¶
En el directorio \data\ del taller, hay un archivo que incluye datos de atributos, pero no geometría, nyc_census_sociodata.sql. La tabla incluye datos socioeconómicos interesantes sobre Nueva York: tiempos de desplazamiento, ingresos y nivel de estudios. Sólo hay un problema. Los datos se resumen por «zona censal», ¡y no tenemos datos espaciales por zona censal!
En esta sección vamos a
Cargar la tabla
nyc_census_sociodata.sqlCrear una tabla espacial para las secciones censales
Unir los datos de atributos a los datos espaciales
Realizar algunos análisis con nuestros nuevos datos
22.1.1. Cargando nyc_census_sociodata.sql¶
Abrir la ventana de consulta SQL en PgAdmin
Selecciona File->Open en el menú y busca el archivo
nyc_census_sociodata.sqlPresiona el botón «Run Query»
Si presionas el botón «Refresh» en PgAdmin, la lista de tablas ahora debería incluir la tabla
nyc_census_sociodata
22.1.2. Creación de una tabla de secciones censales¶
Como vimos en la sección anterior, podemos construir geometrías de nivel superior a partir del bloque censal resumiendo en subcadenas de la clave blkid. Para obtener distritos censales, necesitamos resumir agrupando los primeros 11 caracteres del blkid.
360610001001001 = 36 061 000100 1 001
36 = State of New York
061 = New York County (Manhattan)
000100 = Census Tract
1 = Census Block Group
001 = Census Block
Crea la nueva tabla usando el agregado ST_Union:
-- Make the tracts table
CREATE TABLE nyc_census_tract_geoms AS
SELECT
ST_Union(geom) AS geom,
SubStr(blkid,1,11) AS tractid
FROM nyc_census_blocks
GROUP BY tractid;
-- Index the tractid
CREATE INDEX nyc_census_tract_geoms_tractid_idx
ON nyc_census_tract_geoms (tractid);
22.1.3. Unir los Atributos a los Datos Espaciales¶
Une la tabla de geometrías de distrito con la tabla de atributos de distrito mediante una unión de atributos estándar
-- Make the tracts table
CREATE TABLE nyc_census_tracts AS
SELECT
g.geom,
a.*
FROM nyc_census_tract_geoms g
JOIN nyc_census_sociodata a
ON g.tractid = a.tractid;
-- Index the geometries
CREATE INDEX nyc_census_tract_gidx
ON nyc_census_tracts USING GIST (geom);
22.1.4. Responder una Pregunta Interesante¶
Responde una pregunta interesante! «Lista los 10 principales vecindarios de Nueva York ordenados por la proporción de personas que tienen títulos de posgrado.»
SELECT
100.0 * Sum(t.edu_graduate_dipl) / Sum(t.edu_total) AS graduate_pct,
n.name, n.boroname
FROM nyc_neighborhoods n
JOIN nyc_census_tracts t
ON ST_Intersects(n.geom, t.geom)
WHERE t.edu_total > 0
GROUP BY n.name, n.boroname
ORDER BY graduate_pct DESC
LIMIT 10;
Sumamos las estadísticas que nos interesan y luego las dividimos al final. Para evitar errores de división por cero, no incluimos distritos con población igual a cero.
graduate_pct | name | boroname
--------------+-------------------+-----------
47.6 | Carnegie Hill | Manhattan
42.2 | Upper West Side | Manhattan
41.1 | Battery Park | Manhattan
39.6 | Flatbush | Brooklyn
39.3 | Tribeca | Manhattan
39.2 | North Sutton Area | Manhattan
38.7 | Greenwich Village | Manhattan
38.6 | Upper East Side | Manhattan
37.9 | Murray Hill | Manhattan
37.4 | Central Park | Manhattan
Nota
Los geógrafos de Nueva York se preguntarán por la presencia de «Flatbush» en esta lista de vecindarios sobreeducados. La respuesta se analiza en la siguiente sección.
22.2. Polygon/Polygon Joins¶
En nuestra consulta interesante (en Responder una Pregunta Interesante) usamos la función ST_Intersects(geometry_a, geometry_b) para determinar qué polígonos de distritos censales incluir en cada resumen de vecindario. Lo que lleva a la pregunta: ¿qué pasa si un distrito se encuentra en la frontera entre dos vecindarios? Intersectará ambos, y por lo tanto será incluido en las estadísticas resumidas de ambos.
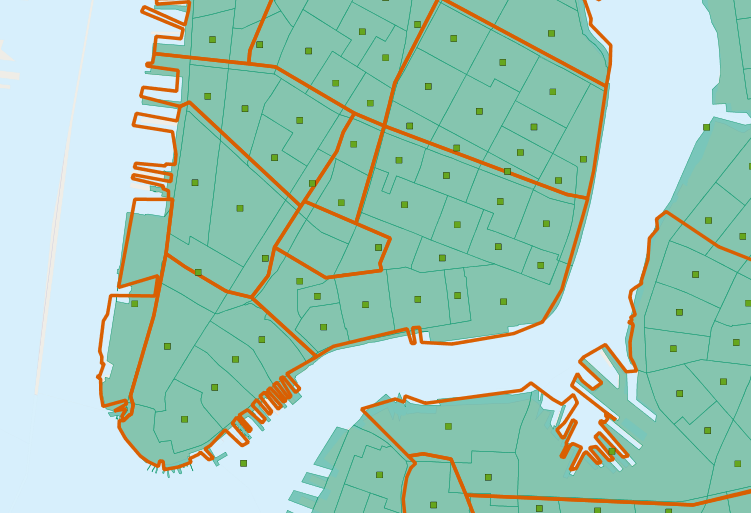
Para evitar este tipo de doble conteo hay dos métodos:
El método simple es asegurar que cada distrito solo caiga en una área de resumen (usando ST_Centroid(geometry))
El método complejo es dividir los distritos que cruzan fronteras (usando ST_Intersection(geometry,geometry))
Aquí hay un ejemplo de cómo usar el método simple para evitar el doble conteo en nuestra consulta de educación de posgrado:
SELECT
100.0 * Sum(t.edu_graduate_dipl) / Sum(t.edu_total) AS graduate_pct,
n.name, n.boroname
FROM nyc_neighborhoods n
JOIN nyc_census_tracts t
ON ST_Contains(n.geom, ST_Centroid(t.geom))
WHERE t.edu_total > 0
GROUP BY n.name, n.boroname
ORDER BY graduate_pct DESC
LIMIT 10;
Observa que la consulta tarda más en ejecutarse ahora, porque la función ST_Centroid debe ejecutarse en cada distrito censal.
graduate_pct | name | boroname
--------------+---------------------+-----------
48.0 | Carnegie Hill | Manhattan
44.2 | Morningside Heights | Manhattan
42.1 | Greenwich Village | Manhattan
42.0 | Upper West Side | Manhattan
41.4 | Tribeca | Manhattan
40.7 | Battery Park | Manhattan
39.5 | Upper East Side | Manhattan
39.3 | North Sutton Area | Manhattan
37.4 | Cobble Hill | Brooklyn
37.4 | Murray Hill | Manhattan
Evitar el doble conteo cambia los resultados!
22.2.1. ¿Qué pasa con Flatbush?¶
En particular, el vecindario de Flatbush ha desaparecido de la lista. La razón se puede ver observando más de cerca el mapa del vecindario Flatbush en nuestra tabla.
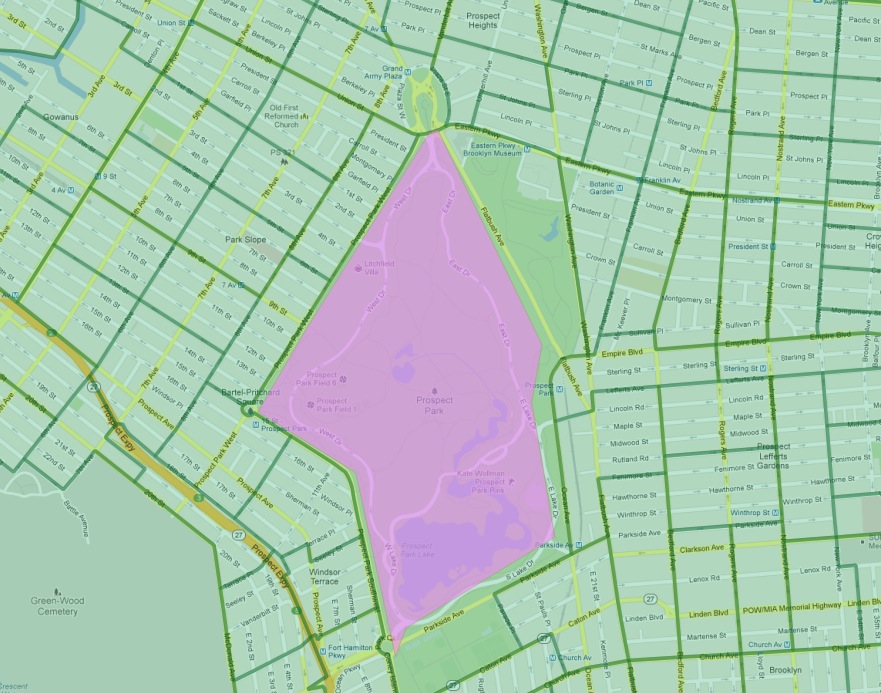
Según lo definido por nuestra fuente de datos, Flatbush no es realmente un vecindario en el sentido convencional, ya que solo cubre el área de Prospect Park. El distrito censal de esa área registra, naturalmente, cero residentes. Sin embargo, el límite del vecindario toca uno de los distritos censales costosos que bordean el lado norte del parque (en el gentrificado vecindario de Park Slope). Al usar pruebas de polígono/polígono, este único distrito fue agregado al Flatbush vacío, resultando en la puntuación muy alta de esa consulta.
22.3. Large Radius Distance Joins¶
Una consulta divertida de hacer es: «¿Cómo difieren los tiempos de viaje de las personas que viven cerca (a menos de 500 metros) de estaciones de metro de aquellos que viven lejos de las estaciones de metro?»
Sin embargo, la pregunta se enfrenta a algunos problemas de doble conteo: muchas personas estarán a menos de 500 metros de múltiples estaciones de metro. Compara la población de Nueva York:
SELECT Sum(popn_total)
FROM nyc_census_blocks;
8175032
Con la población de personas en Nueva York dentro de 500 metros de una estación de metro:
SELECT Sum(popn_total)
FROM nyc_census_blocks census
JOIN nyc_subway_stations subway
ON ST_DWithin(census.geom, subway.geom, 500);
10855873
Hay más personas cerca del metro de las que existen! Claramente, nuestro SQL simple está cometiendo un gran error de doble conteo. Puedes ver el problema observando la imagen de los buffers de las estaciones de metro.
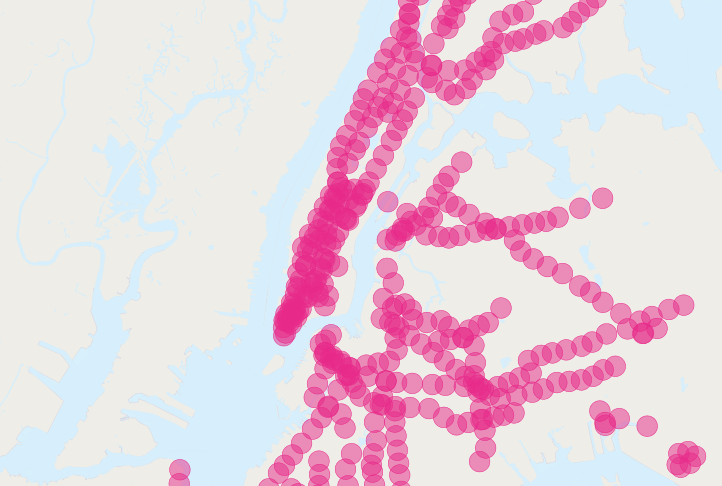
La solución es asegurarse de tener solo bloques censales distintos antes de pasarlos a la parte de resumen de la consulta. Podemos hacerlo dividiendo nuestra consulta en una subconsulta que encuentra los bloques distintos, envuelta en una consulta de resumen que devuelve nuestra respuesta:
WITH distinct_blocks AS (
SELECT DISTINCT ON (blkid) popn_total
FROM nyc_census_blocks census
JOIN nyc_subway_stations subway
ON ST_DWithin(census.geom, subway.geom, 500)
)
SELECT Sum(popn_total)
FROM distinct_blocks;
5005743
Eso es mejor! Así que un poco más de la mitad de la población de Nueva York está dentro de 500 m (aproximadamente una caminata de 5 a 7 minutos) del metro.
