Name
ST_ClusterKMeans — Window function that returns a cluster id for each input geometry using the K-means algorithm.
Synopsis
integer ST_ClusterKMeans(
geometry winset
geom
,
integer
k
,
float8
max_radius
);
Description
Returns K-means cluster number for each input geometry. The distance used for clustering is the distance between the centroids for 2D geometries, and distance between bounding box centers for 3D geometries. For POINT inputs, M coordinate will be treated as weight of input and has to be larger than 0.
max_radius, if set, will cause ST_ClusterKMeans to generate more clusters than
k ensuring that no cluster in output has radius larger than max_radius.
This is useful in reachability analysis.
Enhanced: 3.2.0 Support for max_radius
Enhanced: 3.1.0 Support for 3D geometries and weights
Availability: 2.3.0
Examples
Generate dummy set of parcels for examples:
CREATE TABLE parcels AS
SELECT lpad((row_number() over())::text,3,'0') As parcel_id, geom,
('{residential, commercial}'::text[])[1 + mod(row_number()OVER(),2)] As type
FROM
ST_Subdivide(
ST_Buffer(
'SRID=3857;LINESTRING(40 100, 98 100, 100 150, 60 90)'::geometry,
40, 'endcap=square'),
12) As geom;
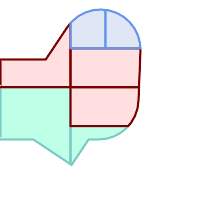
Parcels color-coded by cluster number (cid)
SELECT ST_ClusterKMeans(geom, 3) OVER() AS cid, parcel_id, geom
FROM parcels;
cid | parcel_id | geom -----+-----------+--------------- 0 | 001 | 0103000000... 0 | 002 | 0103000000... 1 | 003 | 0103000000... 0 | 004 | 0103000000... 1 | 005 | 0103000000... 2 | 006 | 0103000000... 2 | 007 | 0103000000...
Partitioning parcel clusters by type:
SELECT ST_ClusterKMeans(geom, 3) over (PARTITION BY type) AS cid, parcel_id, type
FROM parcels;
cid | parcel_id | type -----+-----------+------------- 1 | 005 | commercial 1 | 003 | commercial 2 | 007 | commercial 0 | 001 | commercial 1 | 004 | residential 0 | 002 | residential 2 | 006 | residential
Example: Clustering a preaggregated planetary-scale data population dataset using 3D clusering and weighting. Identify at least 20 regions based on Kontur Population Data that do not span more than 3000 km from their center:
create table kontur_population_3000km_clusters as
select
geom,
ST_ClusterKMeans(
ST_Force4D(
ST_Transform(ST_Force3D(geom), 4978), -- cluster in 3D XYZ CRS
mvalue => population -- set clustering to be weighed by population
),
20, -- aim to generate at least 20 clusters
max_radius => 3000000 -- but generate more to make each under 3000 km radius
) over () as cid
from
kontur_population;
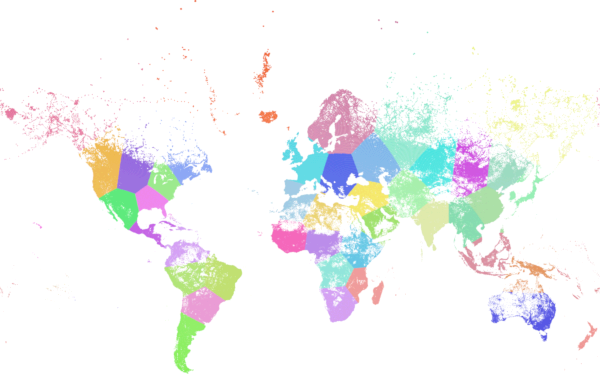
World population clustered to above specs produces 46 clusters. Clusters are centered at well-populated regions (New York, Moscow). Greenland is one cluster. There are island clusters that span across the antimeridian. Cluster edges follow Earth's curvature.